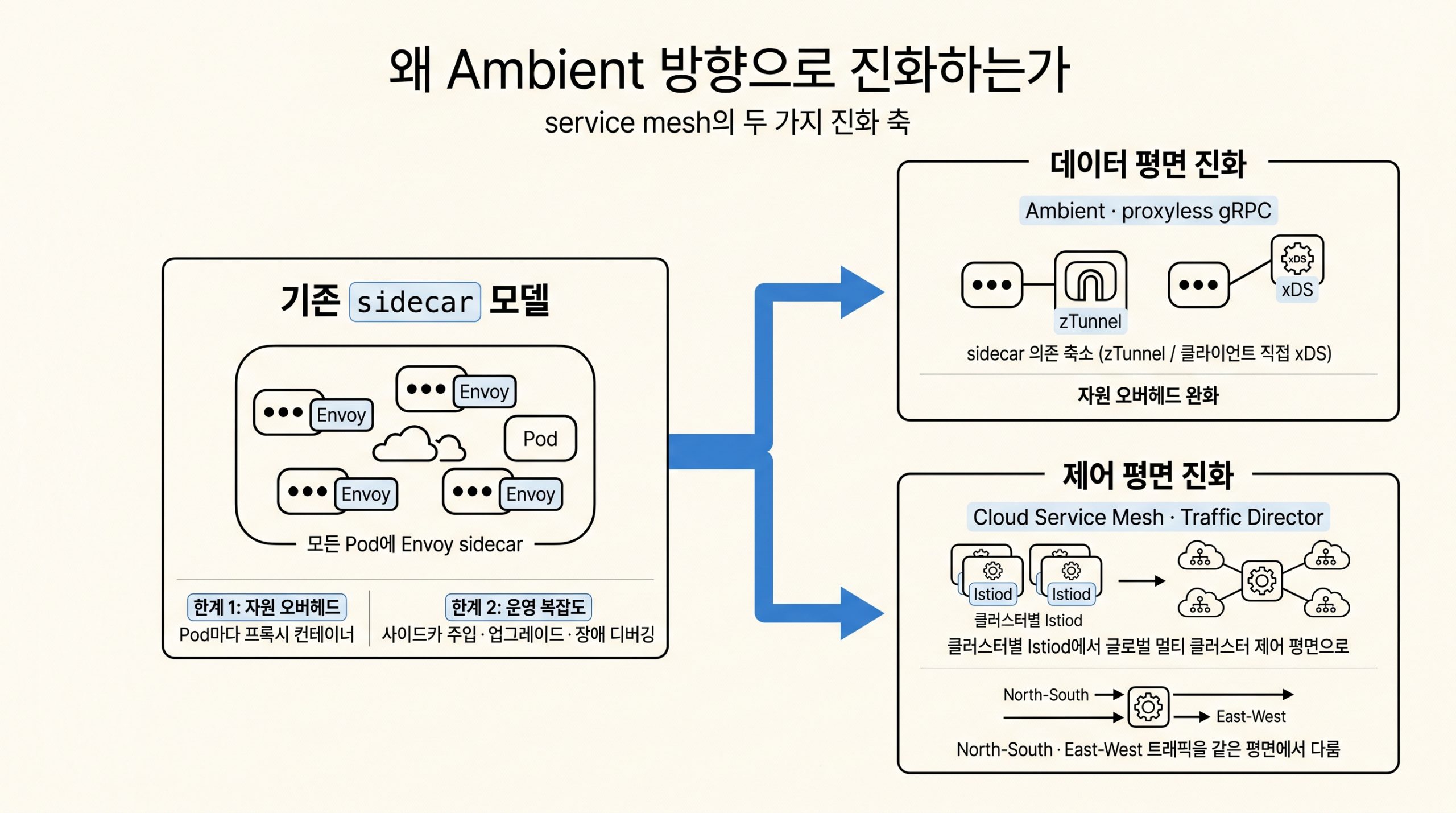
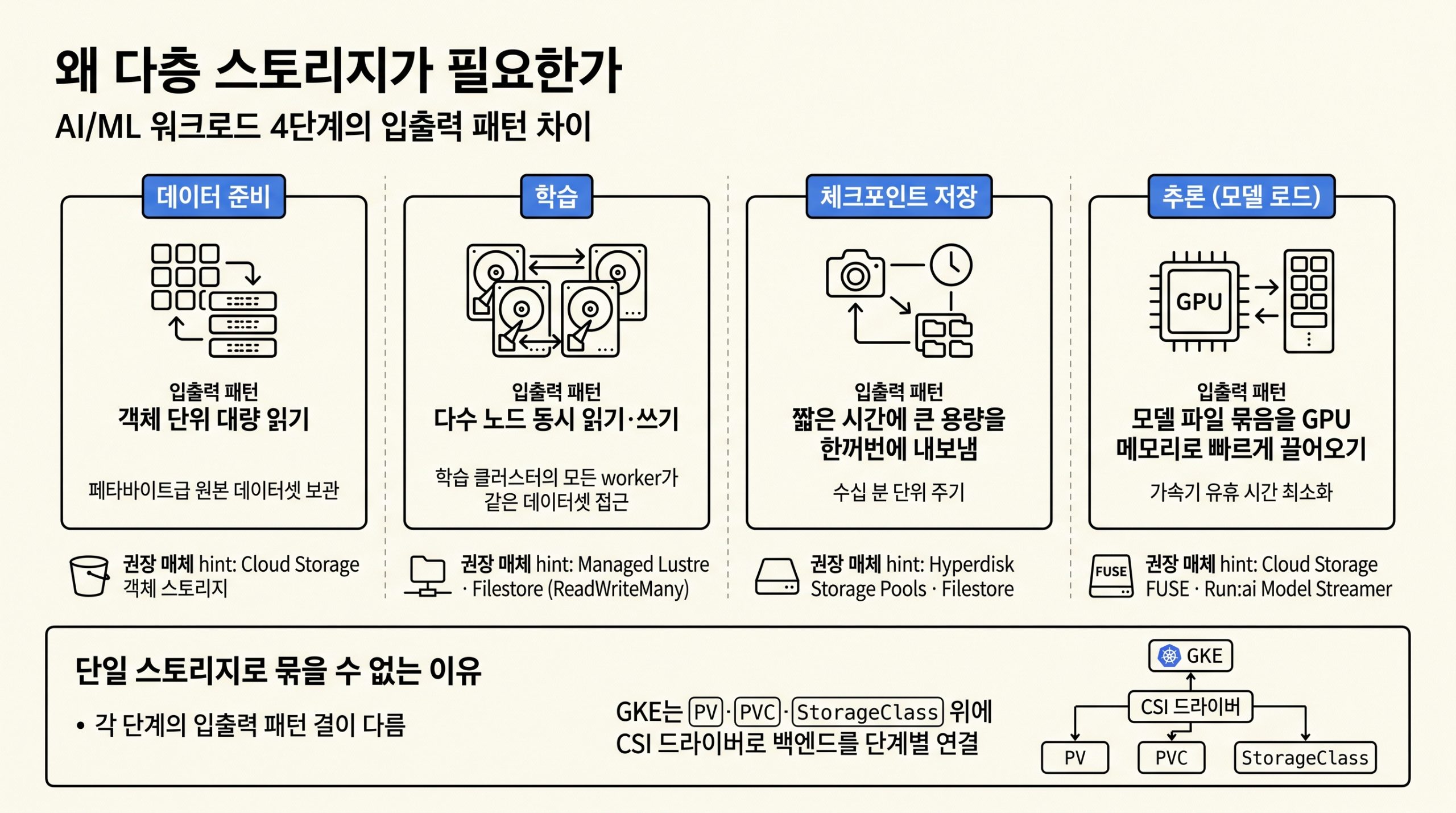
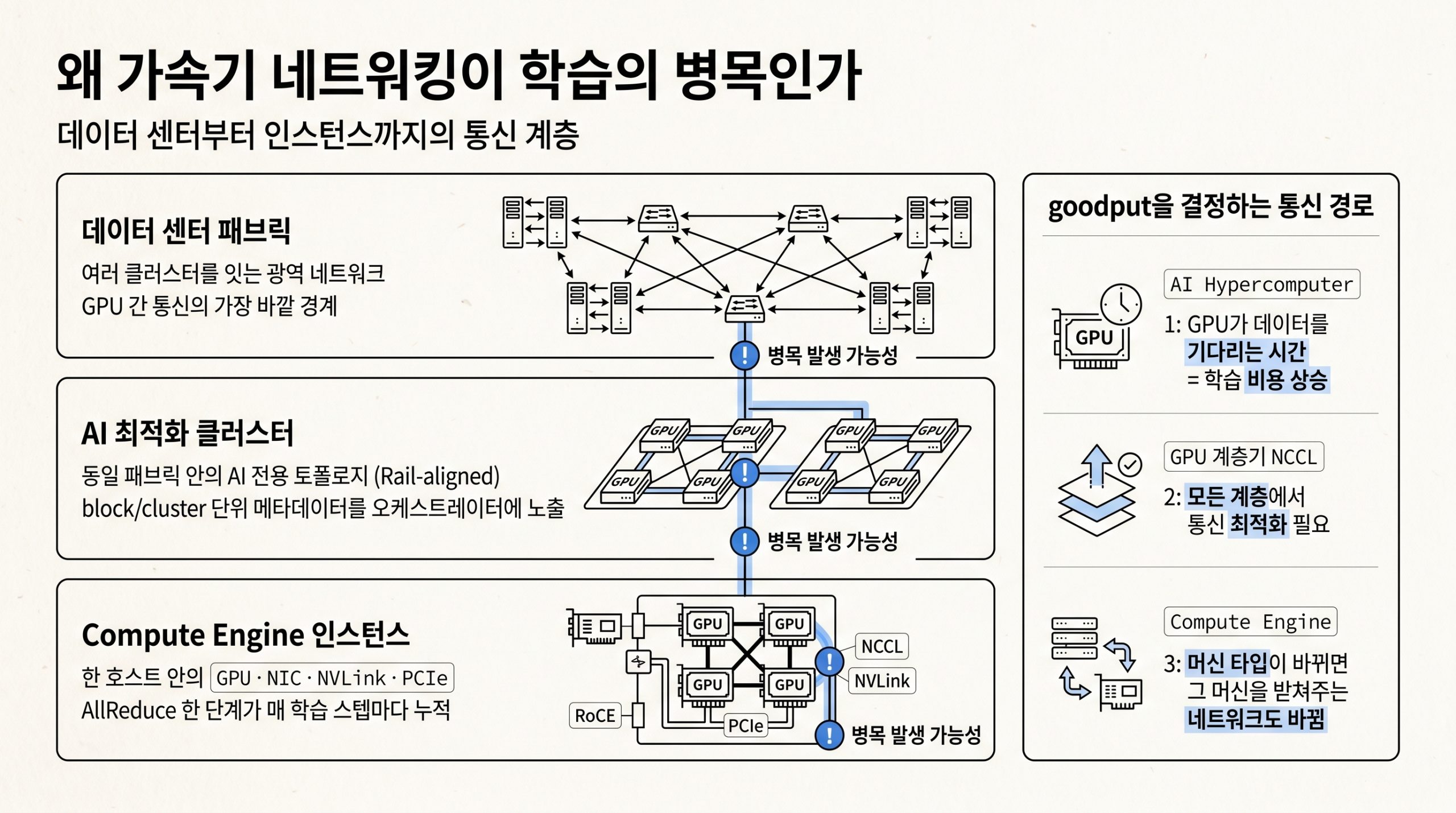
7편: 강화학습 워크로드 운영
대규모 언어 모델(LLM) 강화학습은 지도학습과 다르게 샘플링, 보상 계산, 학습, 동기화가 한 루프에서 돌아갑니다. 루프가 길어지면 노드 한 곳의 장애가 전체 진행을 멈추고, 수천 노드 규모에서는 중단이 시간 단위로 잦아집니다. Google Cloud Next 2026에서 구글 쿠버네티스 엔진(GKE)은 이 워크로드를 받아내기 위한 분산 학습, 관측, 체크포인트 세 축을 정리했습니다. 본 글은 NVIDIA NeMo RL과 verl로 분산 학습을 구성하고, OpenTelemetry로 골든 시그널을 잡고, Multi-Tier Checkpointing으로 빠르게 복구하는 흐름을 다룹니다. 이 글은 학습 인프라 축에 속합니다.
배경: 왜 RL 워크로드 운영이 따로 필요한가
강화학습(RL)은 모델이 응답을 만들고 보상을 매기고 정책을 업데이트하는 과정이 한 루프에 묶여 있어, 사전학습과 달리 운영이 까다롭습니다. GKE 공식 문서가 정의하는 수천 노드 규모에서는 중단이 시간 단위로 발생하고 복구 시간이 곧 비용이라, RL 워크로드 운영은 분산 학습 프레임워크 선택, 관측 메트릭 설계, 체크포인트 계층화 세 축이 동시에 풀려야 합니다.
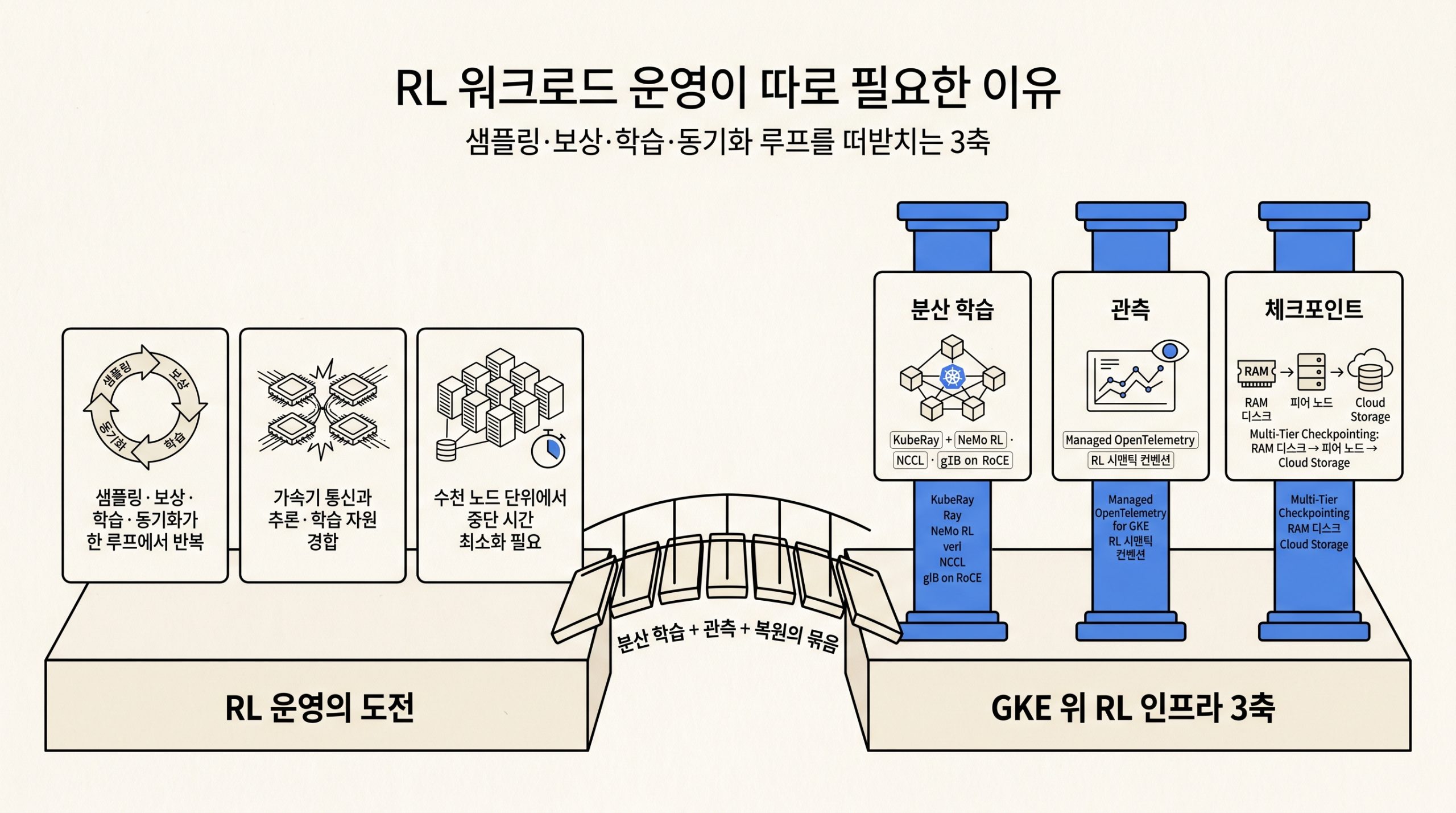
그림 1. 샘플링·보상·학습·동기화 루프의 운영 도전과 GKE 위 RL 인프라의 분산 학습·관측·체크포인트 3축
핵심 개념
세 갈래로 정리합니다.
- 분산 학습 프레임워크: GKE에서 KubeRay로 Ray 클러스터를 띄우고, 그 위에 NeMo RL 또는 verl을 올립니다. 두 프레임워크 모두 그룹 상대적 정책 최적화(GRPO) 알고리즘을 지원합니다.
- 관측: Managed OpenTelemetry for GKE를 활성화한 클러스터에서 RL 애플리케이션이 OpenTelemetry 형식의 메트릭과 트레이스를 내보내고, Cloud Monitoring과 Cloud Trace에서 봅니다.
- 체크포인트: Multi-Tier Checkpointing으로 로컬 RAM 디스크, 클러스터 내 피어 노드, Cloud Storage 백업 세 계층에 체크포인트를 두고 가장 가까운 계층에서 복구합니다.
GRPO는 DeepSeek가 알린 알고리즘으로, Proximal Policy Optimization(PPO)에서 Critic, 즉 가치 모델을 빼고 같은 프롬프트에 대한 응답 그룹의 평균 보상을 베이스라인으로 씁니다. Critic 네트워크가 빠지면서 메모리 효율을 노리는 LLM 정렬 알고리즘으로 자주 쓰입니다.
주요 구성 요소
Ray와 NeMo RL, verl
NeMo RL은 NVIDIA의 오픈소스 후처리 학습 라이브러리로, 단일 GPU 실험부터 수천 GPU 분산까지 다룹니다. verl(Volcano Engine Reinforcement Learning)은 LLM RL의 메모리·연산 패턴을 위해 설계된 고성능 프레임워크입니다. 두 프레임워크 모두 GKE 위에서 KubeRay로 Ray 클러스터를 띄우고, head Pod이 Ray Dashboard와 작업 스케줄링을 맡고 worker Pod이 GPU에서 학습을 실행하는 구조를 공유합니다.
NeMo RL 튜토리얼의 예시는 Gemma3-27b-it 모델을 GSM8K 데이터셋으로 GRPO 학습합니다. 한 스텝에서 16개 프롬프트, 프롬프트당 64개 생성, 총 1,024개 응답을 만들어 그룹 평균 보상으로 정책을 갱신합니다. verl 튜토리얼은 같은 GSM8K 데이터셋으로 Qwen2.5-32B-Instruct를 학습합니다.
Managed OpenTelemetry와 골든 시그널
Managed OpenTelemetry for GKE는 OTLP 엔드포인트로 받은 메트릭과 트레이스를 Cloud Monitoring·Cloud Trace로 넘기며, RL 애플리케이션은 SRE 골든 시그널 네 가지에 맞춘 OpenTelemetry 시맨틱 메트릭을 내보냅니다.
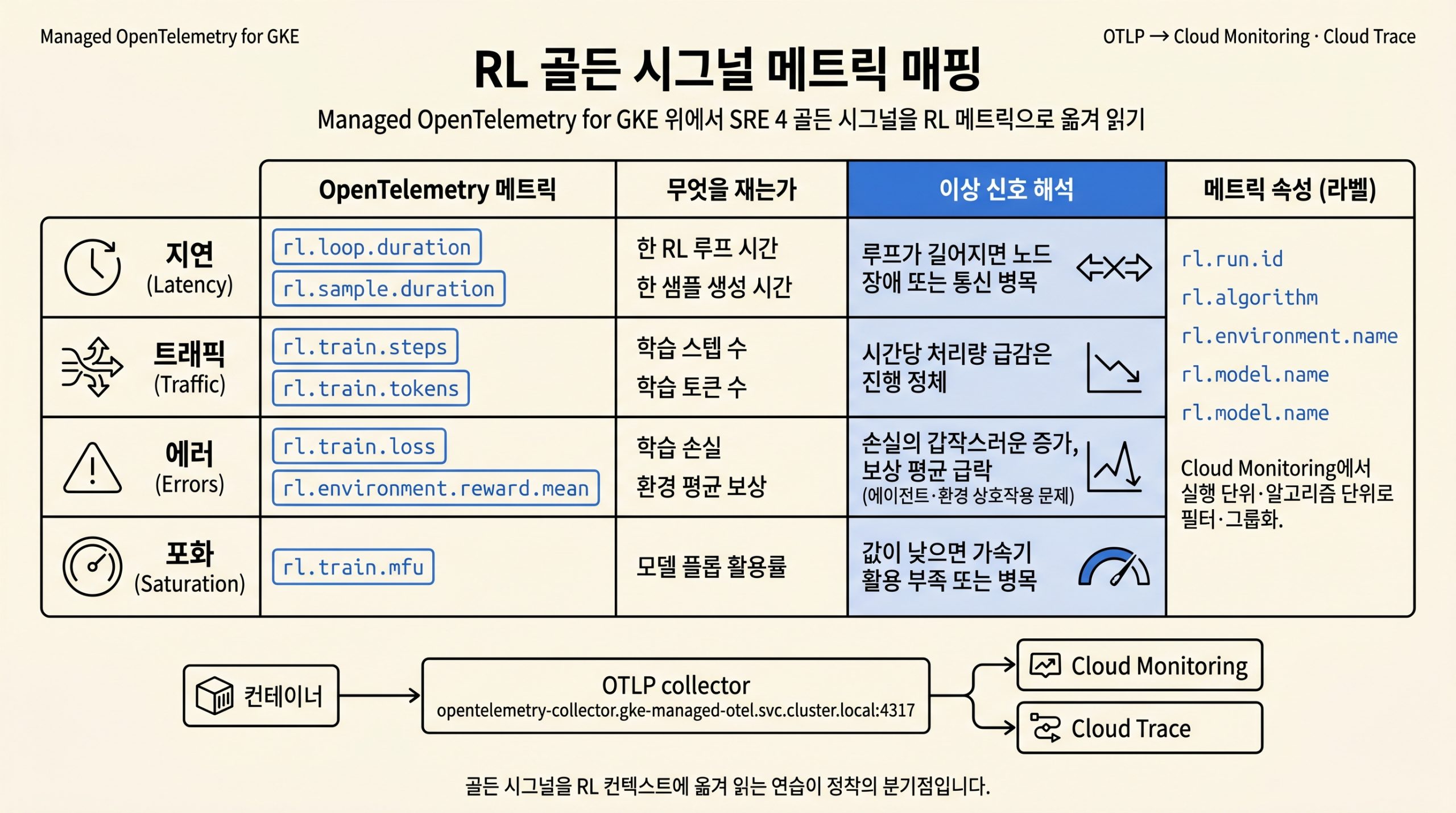
그림 2. 지연·트래픽·에러·포화 네 골든 시그널을 RL 메트릭(rl.loop.duration·rl.train.tokens·rl.train.loss·rl.train.mfu 등)으로 옮겨 읽는 매핑
rl.run.id, rl.algorithm, rl.environment.name, rl.model.name 같은 속성이 메트릭에 따라붙어 Cloud Monitoring에서 실행 단위·알고리즘 단위로 필터·그룹화가 가능합니다.
Multi-Tier Checkpointing
체크포인트는 강화학습이 멈춘 자리에서 다시 일어서는 데 필요한 상태입니다. Multi-Tier Checkpointing은 체크포인트를 RAM 디스크, 피어 노드, Cloud Storage 세 계층에 두고, 복구 시에는 살아 있는 가장 빠른 계층의 last known good(LKG)부터 사용합니다. JAX/Orbax와 PyTorch 양쪽이 지원되며, 계층별 설정 키는 peer-ranks·peers-per-node·backup-interval-minutes입니다.
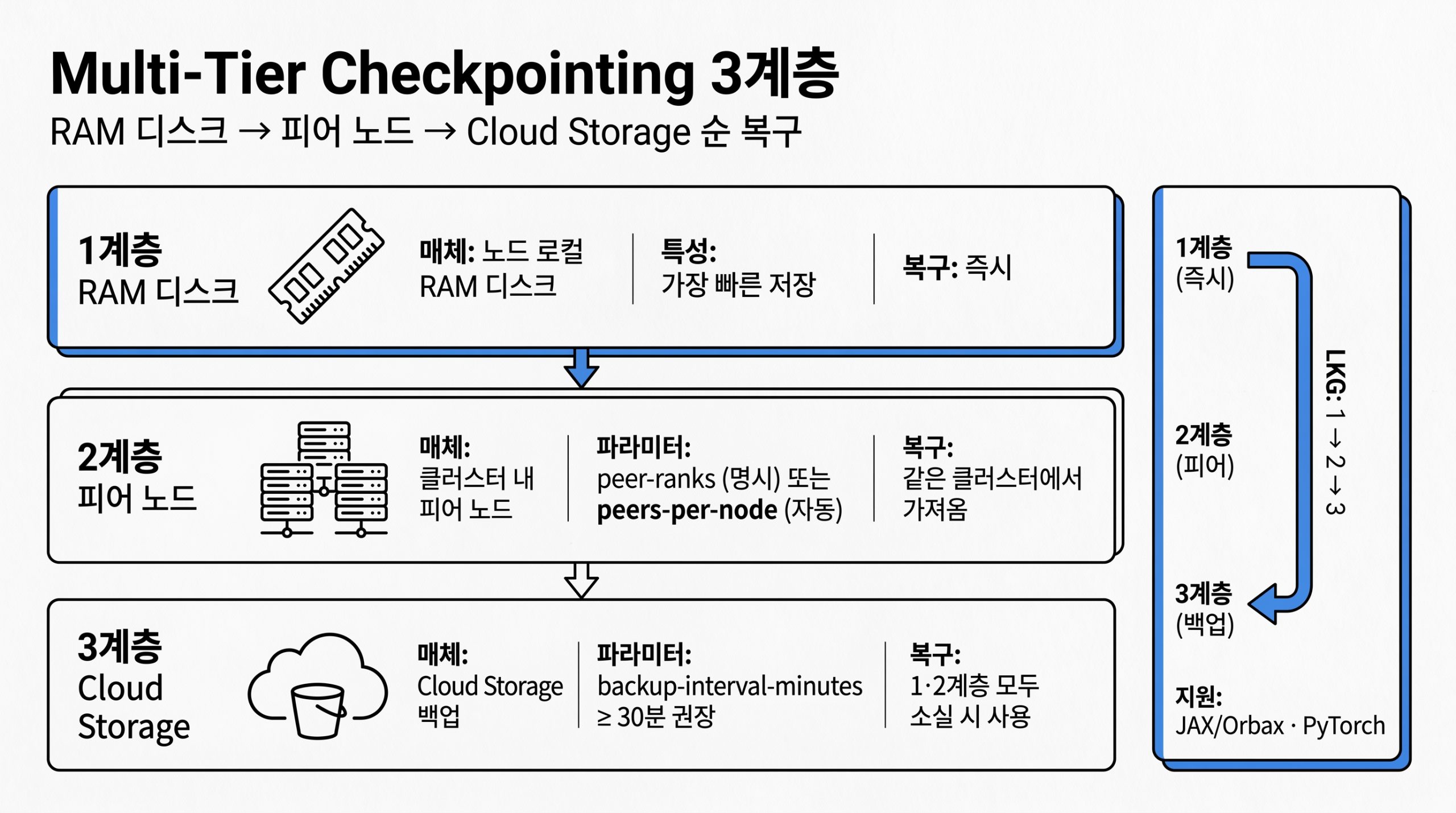
그림 3. 1계층 RAM 디스크, 2계층 피어 노드, 3계층 Cloud Storage로 이어지는 Multi-Tier Checkpointing의 저장 계층과 LKG 복구 우선순위
동작 흐름: 객체에서 GPU까지
전체 흐름은 KubeRay로 띄운 Ray 클러스터(head 1 + worker N) 위에서 NCCL/gIB가 RDMA로 가속기 통신을 잇고, NeMo RL은 Managed Lustre, verl은 Cloud Storage FUSE로 데이터·체크포인트를 마운트하며, head Pod의 Ray Dashboard에 제출된 GRPO 작업이 OpenTelemetry로 메트릭을 내보내고, replicator.yaml이 트리거한 Replicator가 RAM 디스크 → 피어 노드 → Cloud Storage 순으로 체크포인트를 복제하는 6단계입니다.
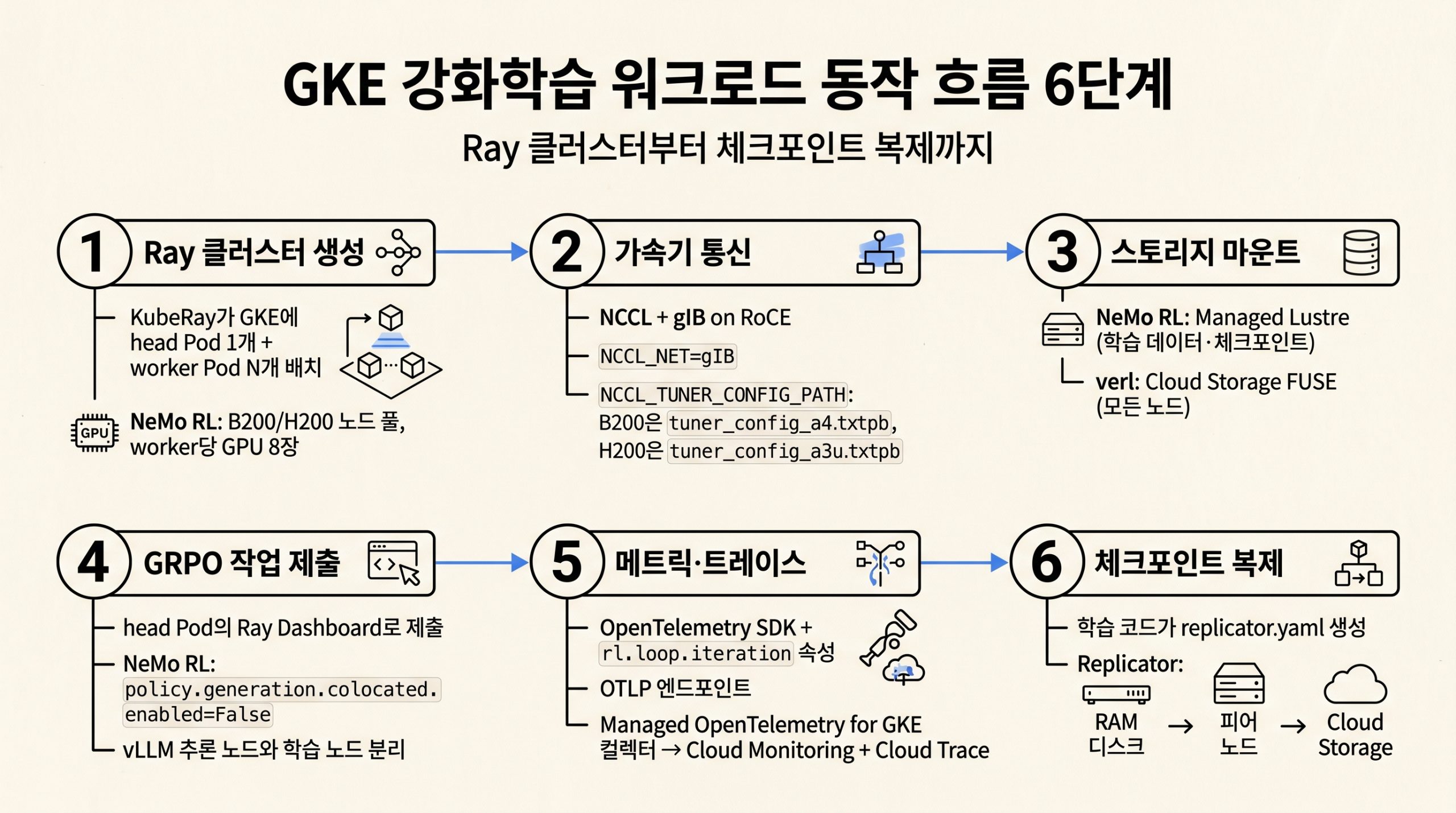
그림 4. Ray 클러스터 생성부터 체크포인트 복제까지, RL 워크로드의 6단계 동작 흐름
워커 환경 변수에는 NCCL_NET=gIB, NCCL_TUNER_CONFIG_PATH(B200은 tuner_config_a4.txtpb, H200은 tuner_config_a3u.txtpb)가 들어갑니다. NeMo RL은 policy.generation.colocated.enabled=False로 vLLM 추론 노드와 학습 노드를 분리해 메모리 집약적인 학습 버퍼와 연산 집약적인 추론 워크로드의 자원 경합을 피합니다.
OTLP 엔드포인트로 메트릭을 보내는 컨테이너 환경 변수는 다음과 같이 설정합니다.
💻 예시 코드
env:
– name: OTEL_COLLECTOR_NAME
value: ‘opentelemetry-collector’
– name: OTEL_COLLECTOR_NAMESPACE
value: ‘gke-managed-otel’
– name: OTEL_EXPORTER_OTLP_METRICS_ENDPOINT
value: $(OTEL_COLLECTOR_NAME).$(OTEL_COLLECTOR_NAMESPACE).svc.cluster.local:4317
– name: OTEL_EXPORTER_OTLP_TRACES_ENDPOINT
value: $(OTEL_COLLECTOR_NAME).$(OTEL_COLLECTOR_NAMESPACE).svc.cluster.local:4317
– name: OTEL_RESOURCE_ATTRIBUTES
value: service.name=$(OTEL_SERVICE_NAME),service.namespace=opentelemetry-demo
체크포인트 흐름의 핵심 제어 파일인 replicator.yaml은 다음과 같은 형태입니다.
💻 예시 코드
job-name: orbax
framework: orbax
assume-data-parallelism: 3
node-rank: 0
nodes: 32
peer-ranks: [1, 16] or peers-per-node: 2
backup-interval-minutes: 30
적용 시나리오
세 가지 상황이 분명합니다.
첫째, GRPO로 LLM의 추론 능력을 정렬하는 후처리 학습입니다. NeMo RL의 GSM8K 예시처럼 한 프롬프트당 수십 개의 응답을 만들고 그룹 평균을 베이스라인으로 쓰는 방식이 적합합니다. 두 RL 튜토리얼은 모두 Spot VM 기반 GPU 노드 풀로 비용을 낮추는 구성을 보여 줍니다.
둘째, 추론과 학습을 분리해 자원 경합을 피하는 RLHF 파이프라인입니다. NeMo RL은 policy.generation.colocated.resources 파라미터로 vLLM 추론 전용 노드를 따로 잡고, 나머지 클러스터를 학습에 씁니다.
셋째, 수천 노드 단위 분산 학습에서 중단 시간을 줄여야 하는 경우입니다. Multi-Tier Checkpointing은 노드 단위 장애에서는 RAM 디스크 또는 피어 노드에서 즉시 복구하고, 클러스터 단위 장애에서는 Cloud Storage 백업에서 복원합니다. 백업 주기를 30분 이상으로 두라는 권장이 있고, 보존 정책은 backup-warden이나 logrotate 같은 외부 도구로 사용자가 직접 관리합니다.
RL 워크로드 도입을 검토할 때 짚어야 할 점
도입 평가는 지원 버전과 모드, 메트릭 매핑, 체크포인트 계층 설계, 비용 네 영역으로 정리됩니다.

그림 5. 지원 버전·메트릭 매핑·체크포인트 계층 설계·비용 네 영역으로 정리한 도입 검토 체크리스트
본 시리즈와의 연결
강화학습 워크로드 운영은 본 시리즈의 다른 글들과 다음과 같이 이어집니다.
- 본 시리즈 5편(가속기 네트워킹)에서 다루는 NCCL과 gIB는 본 글의 NeMo RL·verl 워커가 그대로 사용하는 통신 스택입니다. NCCL_TUNER_CONFIG_PATH로 A4와 A3 Ultra의 토폴로지를 지정하는 부분이 5편의 Rail-aligned 토폴로지 위에서 동작합니다.
- 본 시리즈 6편(AI 스토리지)에서 다루는 Managed Lustre와 Cloud Storage FUSE는 본 글의 두 RL 튜토리얼이 학습 데이터와 체크포인트 경로로 사용하는 스토리지입니다. Multi-Tier Checkpointing의 Cloud Storage 백업 계층이 6편 스토리지 전략과 같은 평면에서 만납니다.
- 본 시리즈 8편(보안과 격리)의 GKE Agent Sandbox는 RL 보상 계산을 안전하게 격리하는 환경으로 검토할 수 있습니다. OpenTelemetry RL 시맨틱 컨벤션에는 rl.reward.sandbox 속성이 정의되어 있어, 보상 계산이 외부 코드 실행을 포함할 때 샌드박스 식별자를 메트릭 라벨로 직접 다룰 수 있습니다.
참고 자료
- Google Cloud, “AI infrastructure at Next 26”, https://cloud.google.com/blog/ko/products/compute/ai-infrastructure-at-next26/
- Google Cloud, “Google Cloud Next 2026 wrap-up”, https://cloud.google.com/blog/topics/google-cloud-next/google-cloud-next-2026-wrap-up
- Google Cloud Documentation, “Monitor reinforcement learning workloads on GKE”, https://docs.cloud.google.com/kubernetes-engine/docs/tutorials/monitor-reinforcement-learning-workloads
- Google Cloud Documentation, “Fine-tune and scale reinforcement learning with NVIDIA NeMo RL on GKE”, https://docs.cloud.google.com/kubernetes-engine/docs/tutorials/nemo-rl-gke
- Google Cloud Documentation, “Fine-tune and scale reinforcement learning with verl on GKE”, https://docs.cloud.google.com/kubernetes-engine/docs/tutorials/scaling-rl-verl-gke
- Google Cloud Documentation, “Train large-scale machine learning models on GKE with Multi-Tier Checkpointing”, https://docs.cloud.google.com/kubernetes-engine/docs/how-to/machine-learning/training/multi-tier-checkpointing
자세한 내용이 궁금하시다면, 메가존소프트 문의포탈을 통해 궁금한 부분을 남겨주세요.