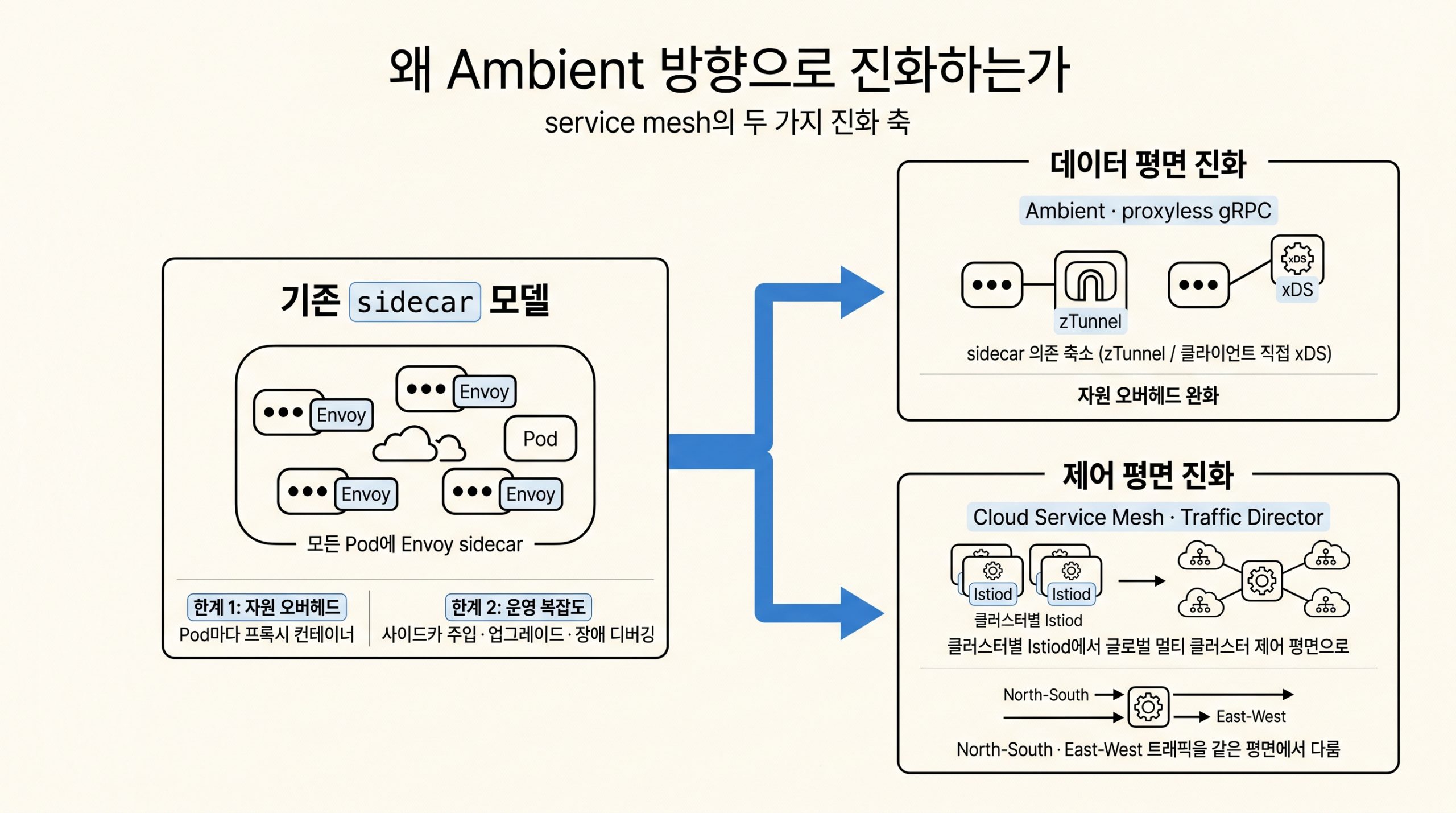
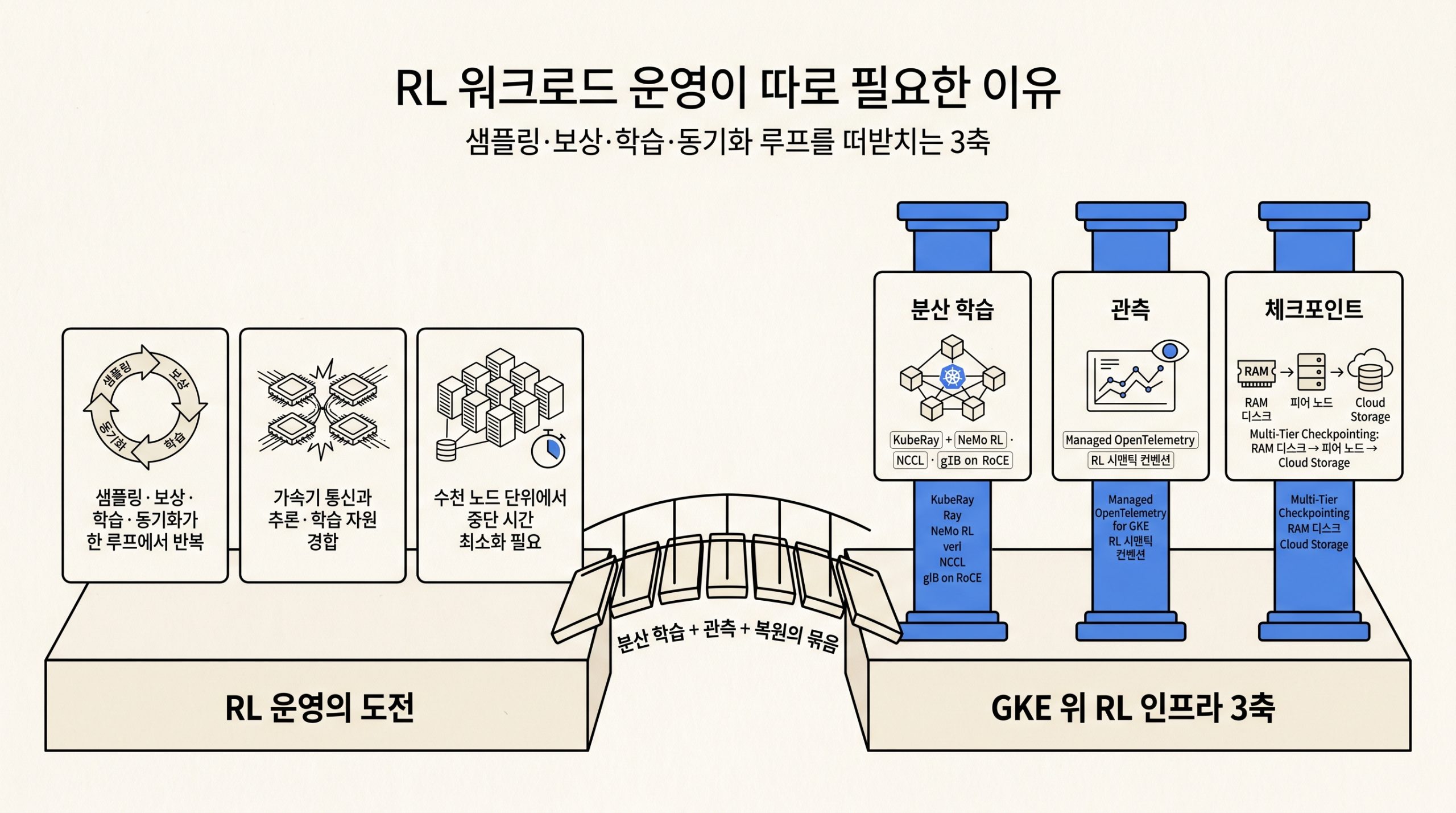
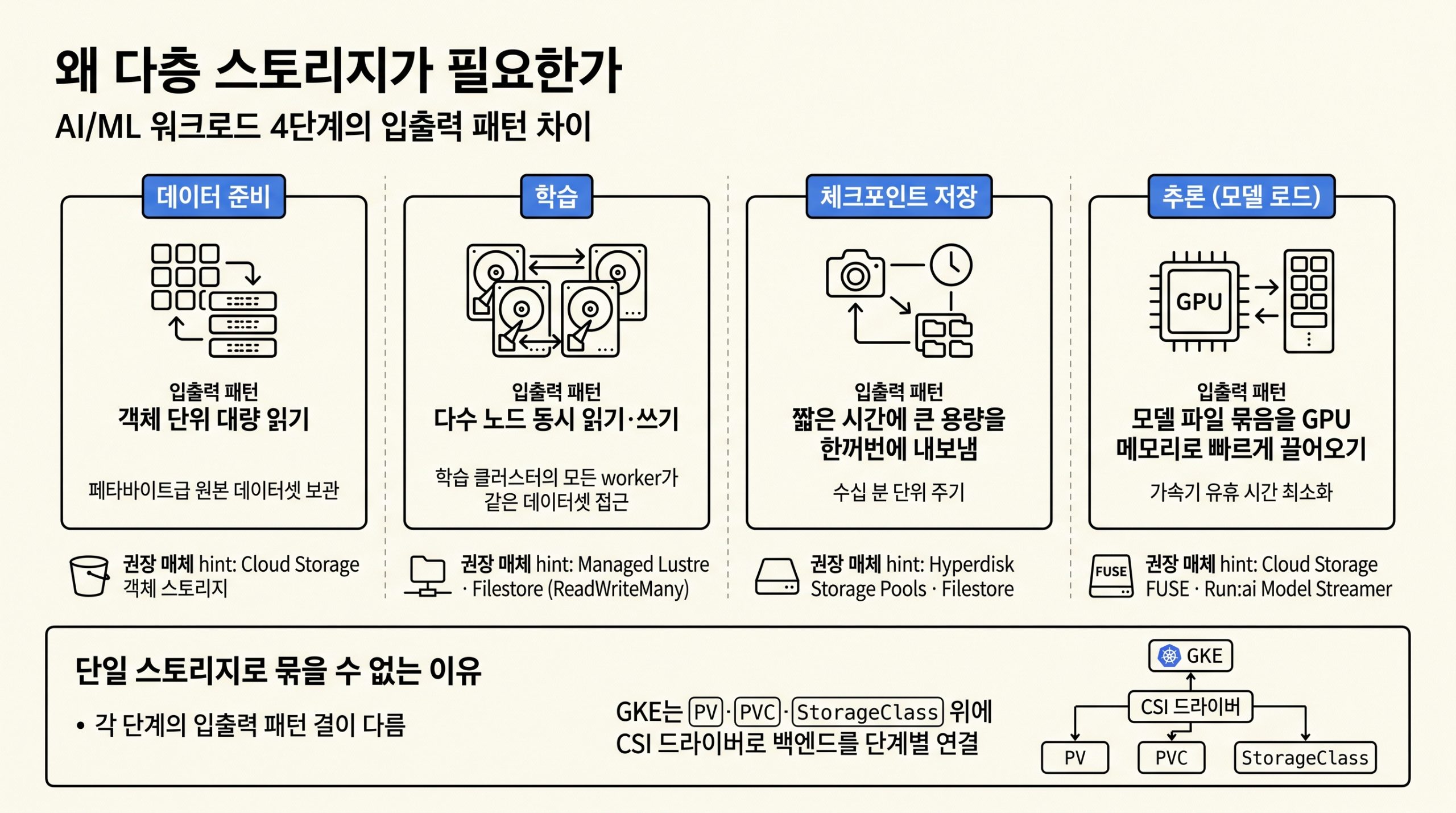
5편: 가속기 네트워킹, NCCL과 gIB와 A4X
대규모 학습은 가속기 한 장이 아니라 수백·수천 장이 함께 한 모델을 학습합니다. 이때 GPU 사이의 통신이 학습 시간을 결정합니다. AllReduce 한 단계가 길어지면 매 스텝마다 그만큼이 누적되고, 결국 토큰당 학습 비용이 올라갑니다. AI Hypercomputer는 이 통신 경로를 하드웨어와 소프트웨어 양쪽에서 손봤습니다. 본 글은 GPU-to-GPU 트래픽을 떠받치는 Rail-aligned 토폴로지, NCCL과 그 위의 gIB 라이브러리, 그리고 GPUDirect RDMA를 사용하는 A4X와 같은 가속기 인스턴스를 정리합니다. 이 글은 학습 인프라 축에 속합니다.
배경: 왜 가속기 네트워킹이 학습의 병목인가
학습 워크로드의 진척도(goodput)를 높이려면 GPU가 데이터를 기다리는 시간을 줄여야 하고, GPU 머신 타입이 바뀌면 그 머신을 받쳐주는 네트워크 서비스도 함께 바뀝니다. GPU 머신 타입은 데이터 센터 패브릭부터 AI 최적화 클러스터, Compute Engine 인스턴스까지 계층 구조를 갖고, 모든 단계에서 통신을 최적화한다는 설계가 출발점입니다.
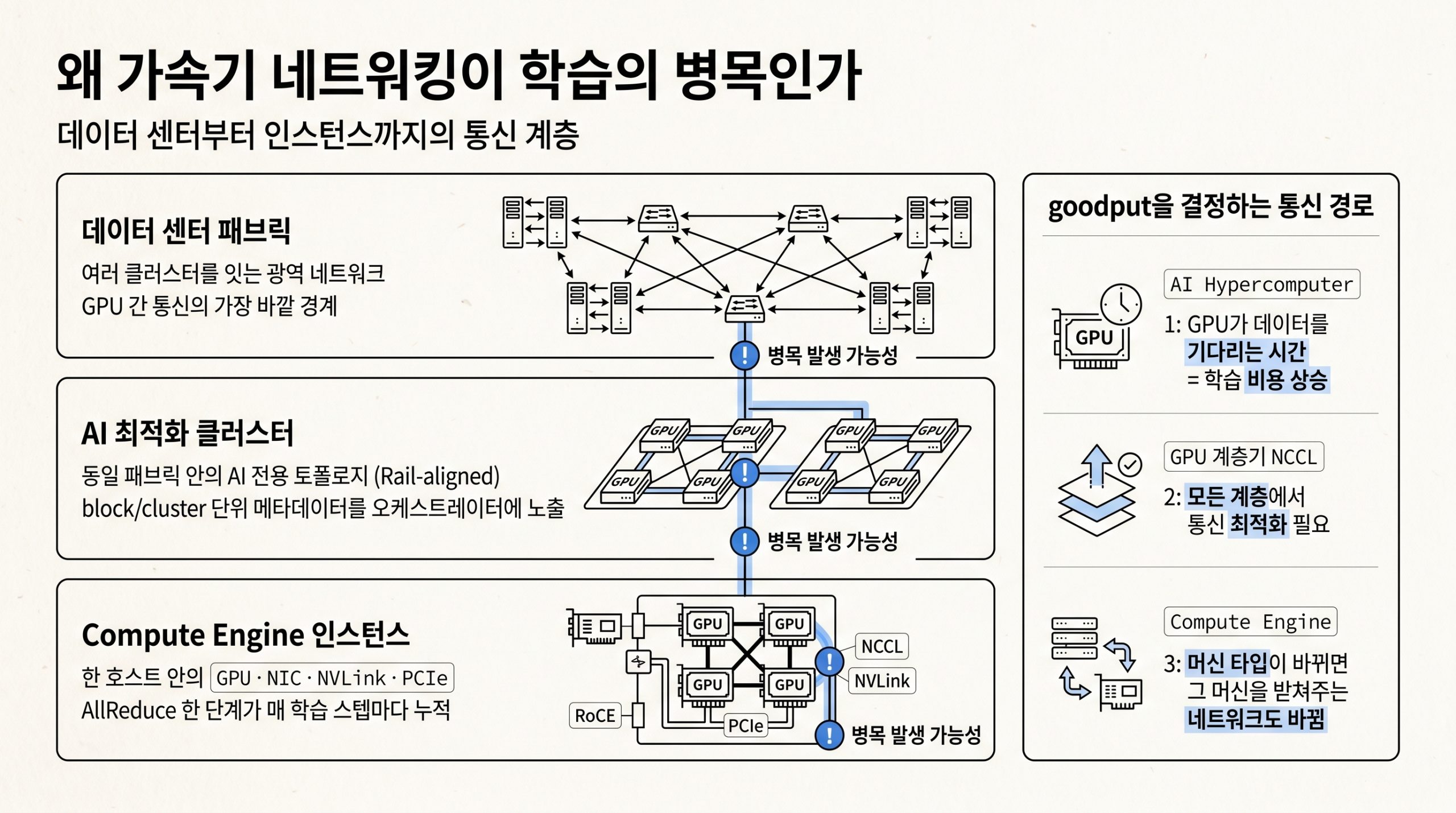
그림 1. 데이터 센터 패브릭, AI 최적화 클러스터, Compute Engine 인스턴스 3계층과 각 계층에서 발생할 수 있는 병목, 그리고 goodput을 결정하는 통신 경로.
Rail-aligned 토폴로지 한눈에 보기
AI Hypercomputer의 GPU 머신은 계층적이고 Rail-aligned된 네트워크 아키텍처 위에서 동작하며, 워크로드부터 NIC까지의 5개 레이어와 sub-block · block · cluster 3단위 구성으로 통신 오버헤드를 줄여 GPU가 계산에 더 많은 시간을 쓰도록 합니다.
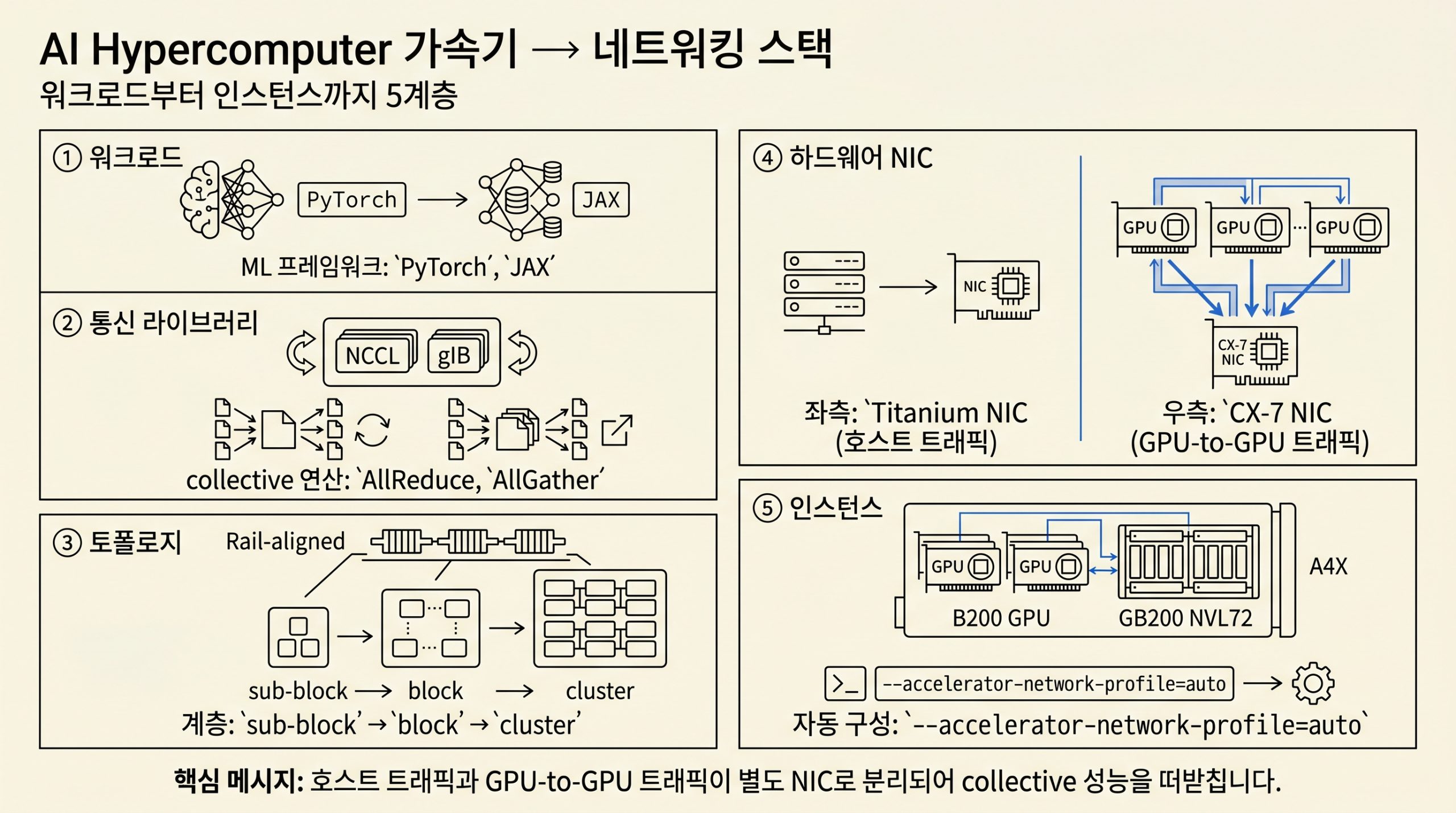
그림 2. 가속기 네트워킹의 워크로드부터 NIC까지 5개 레이어
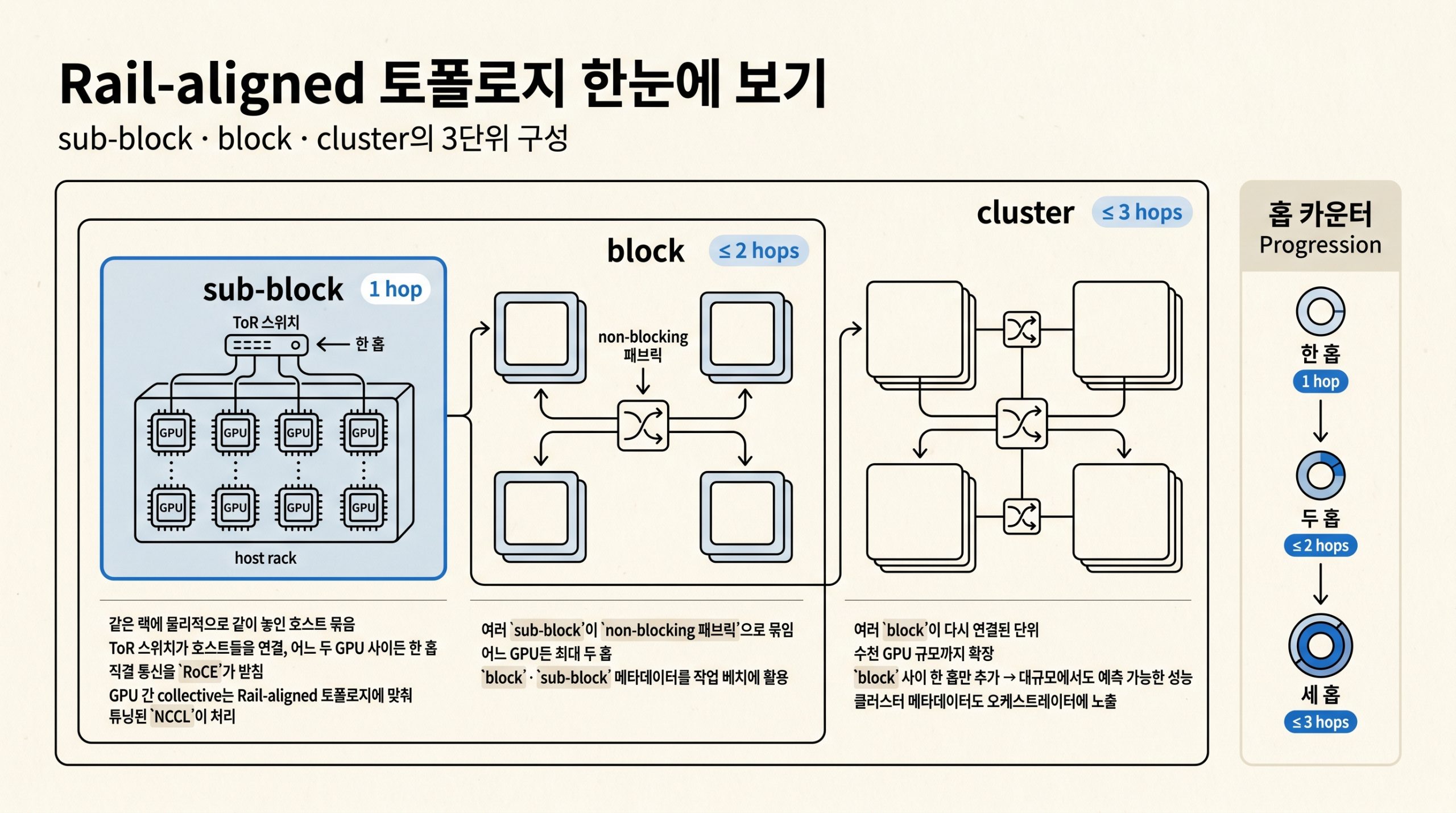
그림 3. sub-block(한 홉)에서 block(최대 두 홉), cluster(최대 세 홉)로 확장되는 Rail-aligned 토폴로지의 3단위 구성
GPU-to-GPU 통신은 RoCE(RDMA over Converged Ethernet), NVIDIA NIC, 그리고 데이터 센터 전반의 Rail-aligned 네트워크 토폴로지가 받칩니다. NVIDIA NVLink는 머신 안의 GPU들을 초고속 직결로 묶고, 머신 사이는 RoCE로 원격 직접 메모리 액세스(RDMA)를 수행합니다.
NCCL과 gIB의 역할
현대의 ML 프레임워크는 GPU 간 통신 프리미티브로 NVIDIA Collective Communications Library(NCCL)를 사용합니다. AllReduce, AllGather 같은 collective 연산이 NCCL에서 정의되며, 이 연산이 분산 학습의 모든 스텝마다 실행됩니다.
Google은 이 NCCL의 강화판인 NCCL/gIB를 A3 Ultra, A4, A4X VM에서 제공합니다. 같은 NCCL 파라미터를 쓰더라도 통신 패턴에 따라 NCCL/gIB가 upstream NCCL과 만들어내는 성능 격차가 매우 큽니다. 문서가 제시한 두 비교를 그대로 옮기면 다음과 같습니다. 32노드 A3 Ultra(H200) 환경에서 background 트래픽이 없을 때 AllReduce는 특정 메시지 크기에서 NCCL/gIB가 upstream NCCL을 최대 12배까지 앞섰습니다. shared 패브릭에 noisy background가 있는 환경에서 큰 메시지 크기의 AllGather 비교에서는 NCCL/gIB가 upstream NCCL을 약 50% 정도 앞섰습니다.
NCCL/gIB가 들고 오는 Google 특화 구성은 세 가지입니다.
- gIB 네트워크 플러그인: Google 네트워크에서 load balancing을 개선해 collective 연산 동안 처리량과 지연을 일관되게 가져갑니다.
- custom tuner 플러그인: Google Cloud VM에서 가장 잘 맞는 튜닝 옵션을 골라줍니다.
- CoMMA profiler 플러그인: 워크로드의 성능 메트릭과 진단 데이터를 수집하고, 워크로드 단위 이슈가 발생했을 때 Google이 분석할 수 있는 텔레메트리를 제공합니다.
upstream NCCL을 그대로 써도 안정성에 문제가 있는 것은 아닙니다. 다만 Google Cloud 환경에서는 NCCL/gIB가 더 잘 맞게 최적화되어 있고, 학습 비용 관점에서 차이가 무시할 수준이 아닙니다.
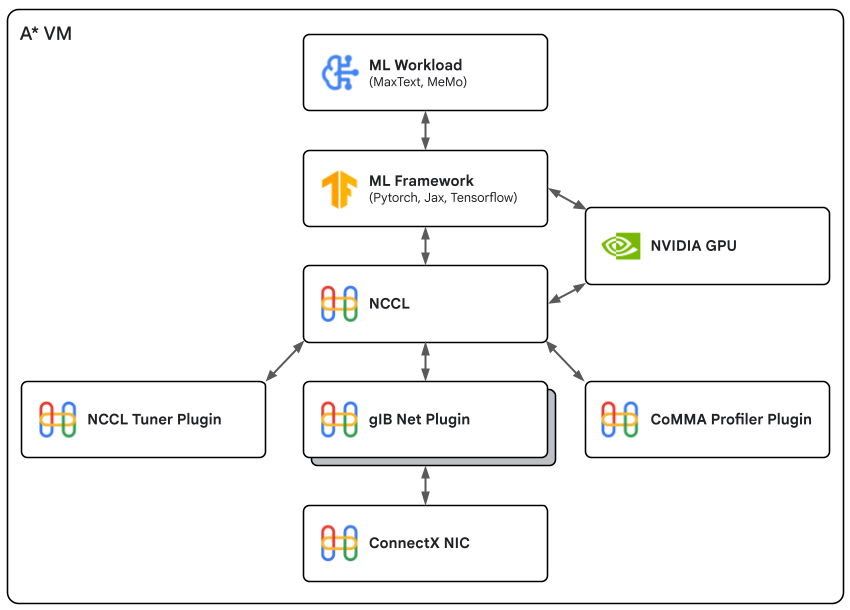
그림 4. ML 워크로드는 ML 프레임워크가 NVIDIA GPU와 NCCL을 함께 호출하고, NCCL은 Google의 도구·플러그인 묶음과 연결됩니다.
호스트 트래픽과 GPU-to-GPU 트래픽 분리
GPU-to-GPU가 아닌 모든 트래픽, 즉 Cloud Storage 액세스, 호스트 관리, 다른 Google Cloud 서비스와의 통신은 별도 네트워크 경로로 흐릅니다. 이 트래픽을 Google Titanium NIC가 처리합니다.
Titanium NIC는 네트워크 처리 작업을 CPU에서 분리해 받아주므로, CPU는 워크로드 자체에 집중할 수 있습니다. 일반 트래픽과 전용 GPU-to-GPU 트래픽이 서로 다른 물리 인터페이스를 쓰게 되어, 동일한 시스템 자원을 두고 경쟁하지 않습니다.
이 분리는 다중 가상 사설 클라우드(VPC) 환경으로 구현됩니다. A4X Max, A4X, A4, A3 Ultra와 GPUDirect RDMA를 함께 쓰는 머신은 default VPC 네트워크를 일반 호스트 트래픽(gVNIC)에 사용하고, 일반 호스트 트래픽용 VPC 네트워크 1개와 GPU-to-GPU 트래픽 전용 공유 VPC 네트워크 1개를 추가로 요구합니다. GPU 트래픽 VPC는 RDMA 네트워크 프로파일이 활성화되어 있어야 합니다. A3 Mega는 GPUDirect-TCPXO 위에서 GPU NIC 전용 VPC 8개, A3 High는 GPUDirect-TCPX 위에서 GPU NIC 전용 VPC 4개가 필요합니다.
이 다중 VPC 구성이 있어야 스토리지 작업과 다른 시스템 작업이 critical한 GPU-to-GPU 통신과 대역폭을 두고 다투지 않습니다.
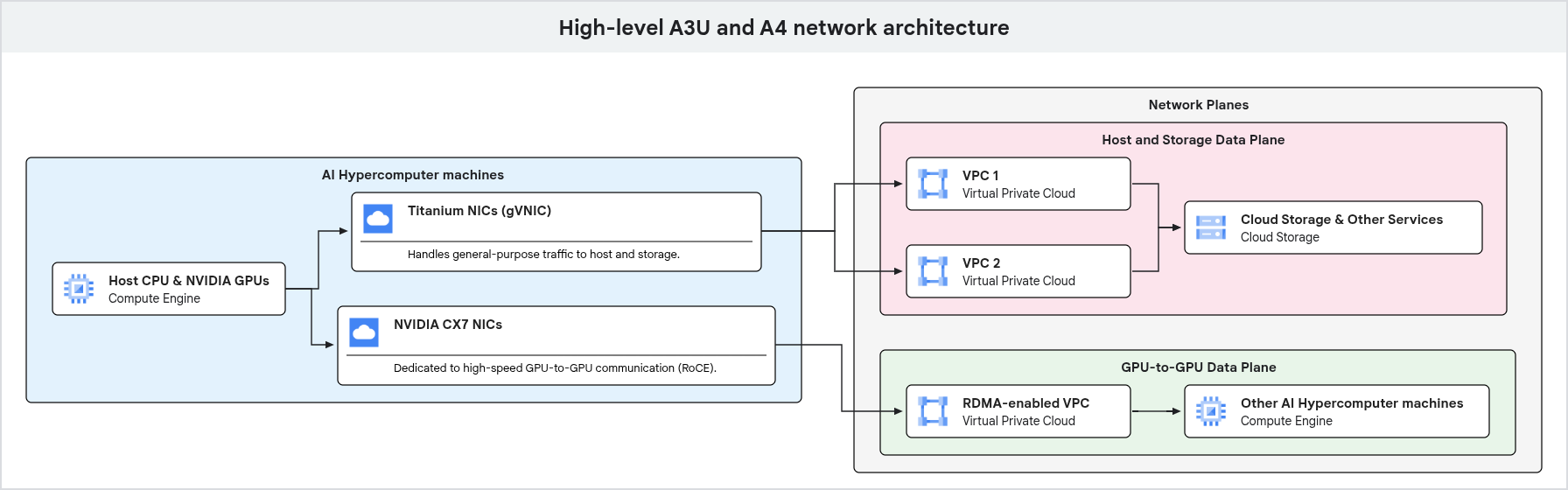
그림 5. 일반 트래픽은 Titanium NIC와 VPC를 거치고, GPU-to-GPU 통신은 RDMA로 최적화된 별도 NIC와 VPC를 사용합니다
A4X와 GPUDirect RDMA: 인스턴스 한 줄 정리
A4X는 NVIDIA GB200 NVL72 rack-scale 아키텍처를 기반으로 한 exascale 플랫폼입니다. NVIDIA Multi-Node NVLink(MNNVL) 시스템으로 rack-scale에서 GPU를 묶고, GPU 사이의 협업 성능을 끌어올립니다. A4X 한 대는 다음 구성을 갖습니다.
- VM당 NVIDIA B200 GPU 4개, NVLink로 연결
- Arm 기반 NVIDIA Grace CPU 2개
- GPU-to-GPU 네트워킹용 400 Gbps CX-7 NIC 4개
- 외부 서비스용 200 Gbps Google Titanium NIC 2개
머신 타입별 NIC 구성은 자동 네트워킹 문서가 표로 정리합니다. A3는 H100 GPU 8개에 Titanium NIC 1개, GPU NIC 4개, GPU NIC용 추가 VPC 4개를 사용합니다. A3 Mega는 같은 H100 8개에 GPU NIC 8개와 추가 VPC 8개. A3 Ultra는 H200 8개, Titanium NIC 2개, GPU NIC 8개에 추가 VPC 2개. A4는 B200 8개로 같은 NIC 구성을, A4X는 GB200 4개에 GPU NIC 4개를 사용합니다.
A4X에는 추가 요건이 따릅니다. 1.33 라인이라면 GKE 1.33.4-gke.1036000 이상, 1.32 라인이라면 1.32.8-gke.1108000 이상이 필요합니다. 이 버전은 R580 GPU 드라이버와 Coherent Driver-based Memory Management(CDMM)를 기본 활성화합니다. CDMM은 GPU 메모리를 OS가 아닌 드라이버에서 관리해 메모리 over-reporting을 해소하고, GPU 메모리를 NUMA 노드로 OS에 노출합니다. CDMM이 켜져 있으면 multi-instance GPU는 지원되지 않습니다. 노드는 Container-Optimized OS 노드 이미지를 사용해야 하며, Ubuntu와 Windows 이미지는 지원되지 않습니다. GPUDirect RDMA는 NCCL Fast Socket이나 GPUDirect TCPX/TCPXO와 호환되지 않으므로, RDMA 클러스터에서는 이들 플러그인을 켜지 않습니다.
A4X 워크로드의 Pod은 노드의 GPU 4개를 모두 요청해야 하고, 단일 노드에서 여러 Pod이 RDMA를 공유할 수 없습니다.
다중 VPC를 단일 플래그로: 자동 네트워킹 구성
가속기 머신은 호스트용 NIC와 고속 인터커넥트용 GPU NIC가 별도 VPC에 붙는 다중 네트워크가 기본입니다. 이 구성을 노드 풀마다 손으로 정렬하는 일은 IP 범위 관리, NIC 매핑, RDMA용 MTU 8896 설정까지 손이 많이 갑니다. GKE는 이 절차를 가속기 네트워크 프로파일이라는 단일 플래그로 자동화합니다.
다음 명령은 노드 풀을 하나 만들면서 자동 네트워킹을 켭니다.
💻 예시 코드
gcloud beta container node-pools create NODE_POOL_NAME \
–accelerator-network-profile=auto \
–node-locations=ZONE \
–machine-type=MACHINE_TYPE
–accelerator-network-profile=auto 플래그가 붙으면 GKE는 노드에 gke.networks.io/accelerator-network-profile: auto 라벨을 자동으로 추가합니다. 워크로드의 nodeSelector에 이 라벨을 포함시키면 그 노드들로 스케줄됩니다.
자동 네트워킹은 단일 영역 노드 풀에서 동작하며, A3, A4, TPU Trillium(v6e) 가속기 최적화 머신 패밀리를 지원합니다. 클러스터는 GKE Dataplane V2를 사용해야 하고, GKE 1.34.1-gke.2037000 이상이 필요합니다. 노드 자동 프로비저닝과 사용자 정의 ComputeClass를 함께 쓰려면 1.35.2-gke.1302000 이상을 사용합니다. 같은 노드 풀에서 multi-network API와 DRANET을 동시에 사용할 수는 없으므로 한 가지 방식을 선택합니다.
다중 VPC를 손으로 만드는 흐름은 A4X 커스텀 클러스터 절차에 잘 드러납니다. 두 번째 Titanium NIC용 VPC 한 개와 RDMA NIC 4개용 VPC 한 개를 만들 때 다음과 같은 형식을 사용합니다. RDMA VPC는 ZONE-vpc-roce 네트워크 프로파일을 적용해 RoCE에 맞춰 사전 구성됩니다.
💻 예시 코드
gcloud compute –project=${PROJECT} \
networks create RDMA_NETWORK_PREFIX-net \
–network-profile=${ZONE}-vpc-roce \
–subnet-mode=custom
자동 네트워킹은 이 흐름과 같은 결과를 단일 플래그로 만들어줍니다. 손수 관리하는 흐름과 자동 흐름 둘 다 사용 가능하며, 이미 다중 VPC 토폴로지를 운영 중이거나 세밀한 제어가 필요할 때는 multi-network API와 GKENetworkParamSet으로 명시적으로 구성할 수 있습니다.
동작 흐름
Gateway API로 노출된 워크로드는 트래픽 자체를 스케일링 신호로 쓸 수 있습니다. 트래픽 기반 오토스케일링은 Gateway 컨트롤러의 글로벌 트래픽 관리 기능 위에서 동작하며 GKE 1.31 이상에서 지원됩니다. Service의 GCPBackendPolicy에 maxRatePerEndpoint를 설정하면 HPA는 autoscaling.googleapis.com|gclb-capacity-fullness 메트릭을 보고 Pod 수를 조절합니다.
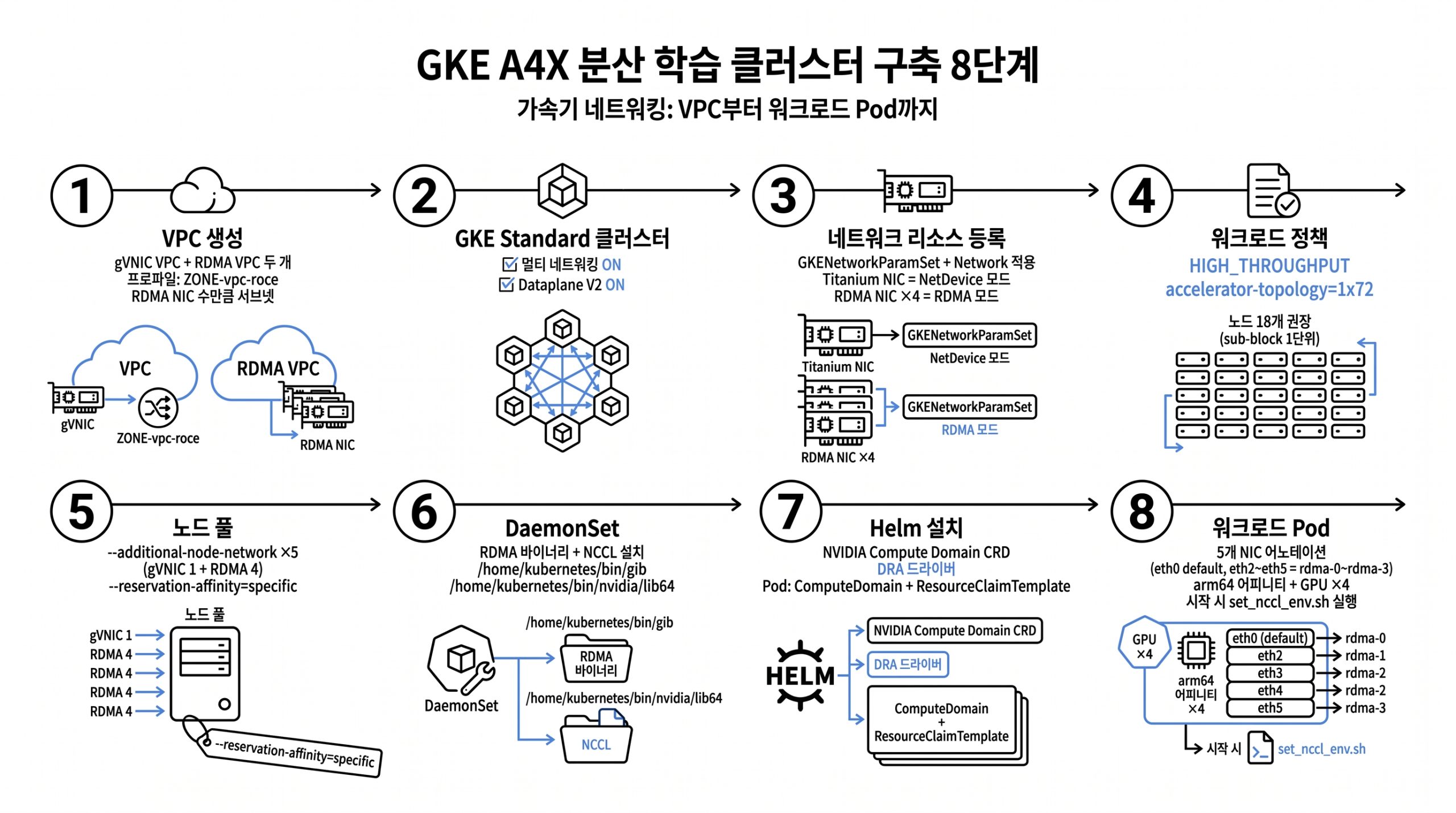
그림 6. VPC 생성부터 워크로드 Pod 어노테이션까지, A4X 분산 학습 클러스터 구축 8단계
1×72 토폴로지는 NVLink 도메인 안에서 sub-block 한 단위를 차지하며 권장 노드 수는 정확히 18개입니다. 노드 풀에는 –additional-node-network로 gVNIC 1개와 RDMA 4개를 붙이고 –reservation-affinity=specific으로 reservation block에 고정합니다. 워크로드 Pod은 eth0 default와 eth2~eth5의 rdma-0~rdma-3 매핑을 어노테이션으로 적고, 컨테이너 시작 시점에 source /usr/local/gib/scripts/set_nccl_env.sh로 NCCL 환경 변수를 일괄 설정합니다.
적용 시나리오
NCCL/gIB가 만들어내는 격차는 학습 워크로드 성격에 따라 갈립니다. 32노드 A3 Ultra 환경의 측정값을 기준으로 보면, 백그라운드 트래픽이 없는 클러스터에서 AllReduce가 자주 실행되는 모델일수록 효과가 큽니다. shared 패브릭에 다른 작업이 함께 도는 환경이라면 큰 메시지 AllGather에서도 차이가 나타납니다. 두 결과 모두 upstream NCCL이 동작하지 않는다는 의미는 아닙니다. 다만 같은 하드웨어를 두고 학습 시간이 단축되는지가 갈립니다.
A4X 같은 rack-scale 인스턴스는 매우 큰 모델의 사전 학습이나 파인 튜닝, 그리고 18노드 단위의 sub-block 토폴로지에 잘 맞습니다. 작은 작업으로는 1×72 토폴로지의 18 인스턴스 sub-block 일부가 유휴 상태로 남아 자원이 낭비될 수 있습니다. 노드 풀 한 개당 정확히 18개 노드를 두는 구성이 권장되는 이유입니다.
자동 네트워킹은 ML 플랫폼 팀이 클러스터를 자주 새로 띄우거나, 가속기 머신 타입을 늘려 가는 단계에서 효과가 큽니다. 다중 VPC, 서브넷, MTU, RDMA 모드 같은 설정을 한 플래그로 묶어주므로 노드 풀 정의가 단순해집니다.
가속기 네트워킹 도입을 검토할 때 짚어야 할 점
기본 베스트 프랙티스 몇 가지가 문서에 정리되어 있습니다. AI Hypercomputer 배포에서는 default Compute Engine 서비스 계정과 그에 자동으로 붙는 Editor 권한을 그대로 쓰지 말고, 전용 서비스 계정을 만들어 roles/compute.admin, roles/iam.serviceAccountUser, roles/storage.admin, roles/logging.admin 같은 신원 및 액세스 관리(IAM) 역할을 명시적으로 부여하는 편이 안전합니다. Cluster Toolkit 같은 도구가 강화된 보안 환경에서 권한 부족으로 실패하는 사례는 자주 보고됩니다.
내부 DNS는 Zonal DNS로 설정해 글로벌 DNS 장애의 영향을 줄이고, 가능하면 외부 IP를 비활성화합니다. 다만 외부 IP를 끄기 전에는 staging 환경에서 의존성을 확인합니다. managed instance group이나 public 노드를 가진 GKE 클러스터처럼 외부 IP를 가정하는 구성이 있을 수 있습니다.
A4X와 GPUDirect RDMA를 도입한다면 다음을 함께 점검합니다. GKE 버전 요건, Container-Optimized OS 노드 이미지 사용, NCCL Fast Socket과 GPUDirect TCPX/TCPXO 비활성화, 그리고 1×72 토폴로지에 맞춘 18 노드 풀 크기. reservation은 reservation-bound 프로비저닝 모델만 허용되며, A4X 용량은 future reservation의 all capacity 모드로만 받습니다.
본 시리즈와의 연결
가속기 네트워킹은 본 시리즈의 다른 글들과 다음과 같이 이어집니다.
- 본 시리즈 6편의 AI 스토리지 다층 전략은 이 글이 다룬 호스트 트래픽 경로를 가정합니다. Cloud Storage FUSE, Managed Lustre, Hyperdisk 같은 스토리지 옵션은 Titanium NIC가 처리하는 일반 트래픽 경로를 거치므로, 다중 VPC 분리가 모델 가중치 로딩과 GPU collective의 간섭을 막아줍니다.
- 본 시리즈 7편의 강화학습 워크로드 운영은 이 글이 다룬 가속기 클러스터 위에서 돌아갑니다. RL 루프의 actor와 learner가 같은 NCCL collective를 거치며, 그 위에 OpenTelemetry 메트릭이 얹힙니다.
- 본 시리즈 2편의 GKE Inference Gateway는 학습된 모델을 받아 서빙합니다. 이 글의 학습 인프라가 산출하는 체크포인트가 추론 경로의 시작점이 됩니다.
참고 자료
- Google Cloud, “AI infrastructure at Next 26”, https://cloud.google.com/blog/ko/products/compute/ai-infrastructure-at-next26/
- Google Cloud, “Google Cloud Next 2026 wrap-up”, https://cloud.google.com/blog/topics/google-cloud-next/google-cloud-next-2026-wrap-up
- Google Cloud Documentation, “GPU networking overview”, https://docs.cloud.google.com/ai-hypercomputer/docs/networking-overview
- Google Cloud Documentation, “Optimize cluster networking by using NCCL/gIB”, https://docs.cloud.google.com/ai-hypercomputer/docs/nccl/overview
- Google Cloud Documentation, “Create a custom AI-optimized GKE cluster which uses A4X”, https://docs.cloud.google.com/ai-hypercomputer/docs/create/gke-ai-hypercompute-custom-a4x
- Google Cloud Documentation, “Configure automated networking for accelerator VMs”, https://docs.cloud.google.com/kubernetes-engine/docs/how-to/config-auto-net-for-accelerators
- Google Cloud Documentation, “Networking best practices”, https://docs.cloud.google.com/ai-hypercomputer/docs/networking-best-practices
- Google Cloud Documentation, “Network services for deployments”, https://docs.cloud.google.com/ai-hypercomputer/docs/networking-services
자세한 내용이 궁금하시다면, 메가존소프트 문의포탈을 통해 궁금한 부분을 남겨주세요.