3편: KV 캐시 티어링과 메모리 계층화
키-값 캐시(KV 캐시)는 대규모 언어 모델(LLM) 서빙에서 그래픽 처리 장치(GPU) 메모리를 가장 빠르게 갉아먹는 자원입니다. 입력 시퀀스가 길어질수록 self-attention이 저장하는 키와 값의 크기가 비례해 늘어나고, 같은 GPU에 올릴 수 있는 동시 요청 수는 줄어듭니다. 본 글은 이 KV 캐시를 GPU의 고대역폭 메모리(HBM)에서 하위 저장소로 끌어내려 처리량을 끌어올리는 메모리 계층화 전략을 정리합니다. 본 시리즈는 Google Cloud Next 2026 GKE 신기능을 추론 인프라·학습 인프라·보안과 격리·네트워킹 4축으로 다루며, 이 글은 추론 인프라 축에 속합니다.
배경: 왜 KV 캐시가 병목이 되는가
self-attention의 K·V는 GPU vRAM을 점유하기 때문에 컨텍스트가 길어지거나 동시 요청이 늘면 메모리가 곧장 부족해집니다. 벤더 중립적인 해법은 캐시 자체를 줄이는 길(PagedAttention, FP8 양자화)과 캐시를 더 넓은 저장소로 옮기는 길(메모리 계층화) 두 갈래이며, 본 글은 후자를 다룹니다.
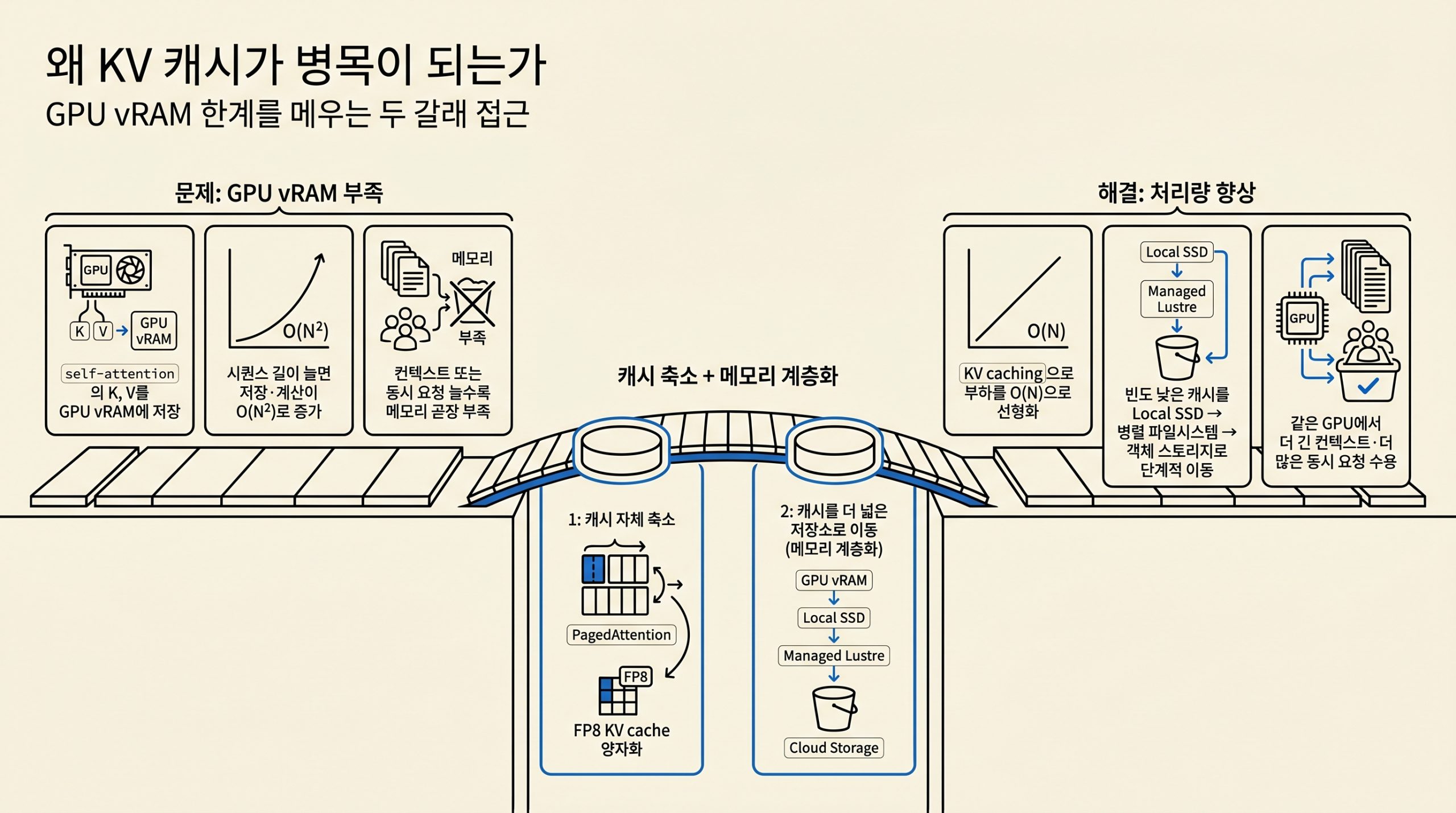
그림 1. GPU vRAM 부족 문제를 캐시 축소(PagedAttention·FP8 양자화)와 메모리 계층화(Local SSD → 병렬 파일시스템 → 객체 스토리지) 두 갈래로 푸는 구조
메모리 계층 한눈에 보기
추론 워크로드의 4단 계층은 GPU HBM, Local SSD, Managed Lustre, Cloud Storage 순으로 이어지며 빈도가 낮은 캐시가 아래 계층으로 축출되었다가 필요 시 다시 끌어 올려집니다. 무게중심은 가운데 두 계층에 있고, 공유 계층인 Managed Lustre가 GKE에서 어떻게 마운트되는지가 KV 캐시 티어링을 실제로 가능케 합니다.
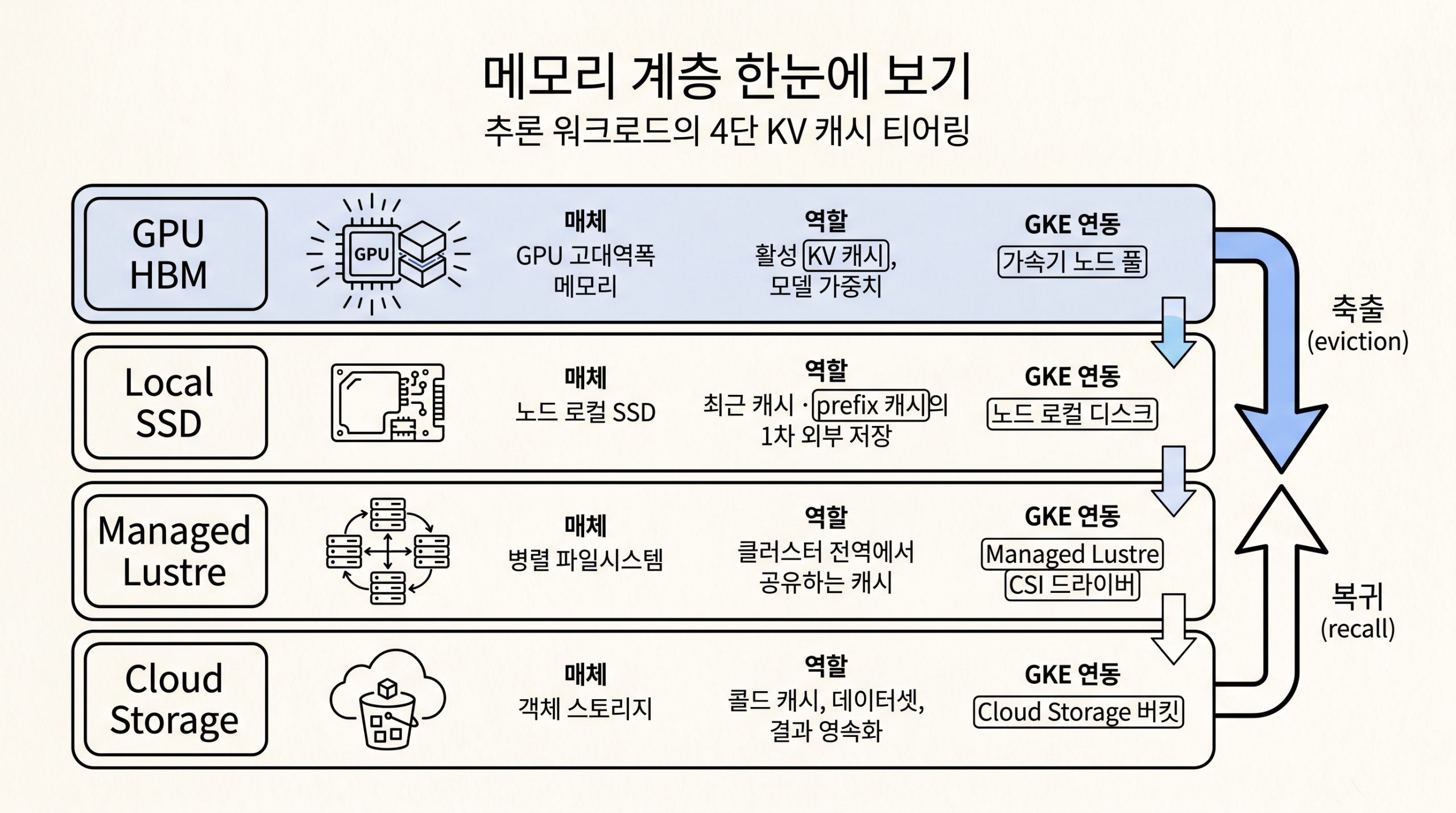
그림 2. GPU HBM → Local SSD → Managed Lustre → Cloud Storage 4단 계층의 매체·역할·GKE 연동 방식과 축출·복귀 흐름
주요 구성 요소
Managed Lustre
Google Cloud Managed Lustre는 인공지능과 고성능 컴퓨팅(HPC) 워크로드에 맞춰진 완전 관리형 병렬 파일시스템입니다. DDN과 협업해 개발했고, Lustre 파일시스템의 주요 메인테이너가 동일하게 이 서비스를 받쳐줍니다. 용량은 9,000 GiB부터 84,016,000 GiB(80.1 PiB)까지, 처리량은 최대 10 TBps, IOPS는 TiB당 최대 5,800 read·5,600 write입니다. 메타데이터 성능은 처리량 72 GBps당 최대 410,000 stats/s, 115,000 creates/s, 95,000 deletes/s를 기본값으로 가지며, 이 기본값의 최대 22배까지 확장됩니다. 단일 파일은 0.5 PiB까지 지원합니다.
POSIX를 준수하므로 기존 애플리케이션이 별도 변경 없이 마운트해 사용할 수 있고, Cloud Storage와의 양방향 고속 전송이 내장되어 있습니다. 일부 고성능 구성에서는 정기 호스트 점검을 위해 최대 4시간의 계획 다운타임이 필요할 수 있으며, 이 일정은 사전에 조율됩니다.
Managed Lustre CSI 드라이버
GKE에서 Managed Lustre를 다루는 표준 경로는 Managed Lustre Container Storage Interface(CSI) 드라이버입니다. 이 드라이버는 GKE가 관리하며, 표준 Kubernetes Persistent Volume Claim(PVC)과 Persistent Volume(PV)으로 Managed Lustre 인스턴스를 프로비저닝, 마운트, 언마운트합니다. 동적 프로비저닝(PVC가 인스턴스를 만드는 방식)과 정적 프로비저닝(기존 인스턴스에 연결하는 방식) 양쪽을 지원하며, 액세스 모드는 ReadWriteMany, ReadOnlyMany, ReadWriteOnce를 모두 받습니다.
운영 측 전제 조건은 다음과 같습니다. GKE 클러스터와 노드 풀 버전이 1.33.2-gke.1111000 이상이어야 하고, Google Cloud CLI는 523.0.0 이상이어야 합니다. CSI 드라이버는 Standard와 Autopilot 모두에서 기본 비활성화 상태이므로 클러스터 생성 시점이나 그 이후에 명시적으로 활성화해야 합니다. 노드 OS는 Container-Optimized OS(COS)만 지원하며, 사용자 정의 노드 이미지는 지원하지 않습니다. 클러스터는 Managed Lustre 인스턴스와 동일한 가상 사설 클라우드(VPC) 네트워크에 있어야 합니다. 볼륨 확장은 GKE 1.35.0-gke.2331000 이상에서만 가능하고, 그 이전 버전에서는 PVC를 다시 만들거나 정적 프로비저닝으로 연결해야 합니다.
PagedAttention과 보조 최적화
캐시를 넓은 저장소로 밀어내는 일과 별개로, GPU 안에서 KV 캐시 자체를 줄이는 기법이 나란히 사용됩니다. PagedAttention은 운영체제의 가상 메모리에서 영감을 얻은 페이징 기법으로, KV 캐시의 단편화와 중복을 줄여 같은 GPU 메모리에서 더 긴 입력 시퀀스를 수용합니다. Flash attention은 토큰 생성 시 GPU RAM과 L1 캐시 사이의 데이터 이동을 줄여 컴퓨트 코어가 노는 시간을 없애는 방향입니다.
vLLM에서는 KV 캐시 자체에도 양자화를 적용할 수 있습니다. –kv-cache-dtype=fp8_e5m2 플래그를 켜면 FP8 E5M2 형식으로 KV 캐시를 저장해 메모리 사용량을 크게 줄이고 큰 배치 크기에서 지연 시간을 낮춥니다. 다만 추론 정확도는 떨어집니다. vLLM은 FP8 E5M2와 E4M3 두 형식을 지원합니다.
동작 흐름
추론 게이트웨이가 라우팅한 요청은 vLLM 같은 서빙 엔진에 도달합니다. 엔진은 먼저 prefix caching을 확인합니다. 동일하거나 유사한 prefix의 KV 캐시가 GPU HBM에 있으면 그대로 사용하고, 없으면 하위 계층을 차례로 조회합니다. Local SSD에 있다면 GPU HBM으로 끌어올리고, 거기에도 없으면 Managed Lustre 볼륨에서 읽어 옵니다. 이 모든 단계가 실패하면 프롬프트의 처음부터 다시 prefill을 수행합니다.
이 흐름이 작동하려면 GKE 측 설계가 함께 맞물려야 합니다. 동일 모델을 서빙하는 Pod들이 같은 PVC로 Managed Lustre 볼륨을 공유하면 클러스터 전역에서 prefix 캐시가 재사용됩니다. ReadWriteMany 액세스 모드는 이 공유를 가능하게 하는 최소 조건입니다.
배치·비동기 추론 측면에서도 같은 계층이 활용됩니다. 다음 다이어그램은 Pub/Sub부터 추론 서버까지 이어지는 비동기 추론 플랫폼 구조를 보여줍니다. 이 구조에서 추론 서버 자체가 KV 캐시 티어링의 수혜자이며, Pub/Sub은 트래픽 스파이크를 흡수해 KV 캐시가 한 번에 폭발적으로 늘어나는 상황을 완화합니다.
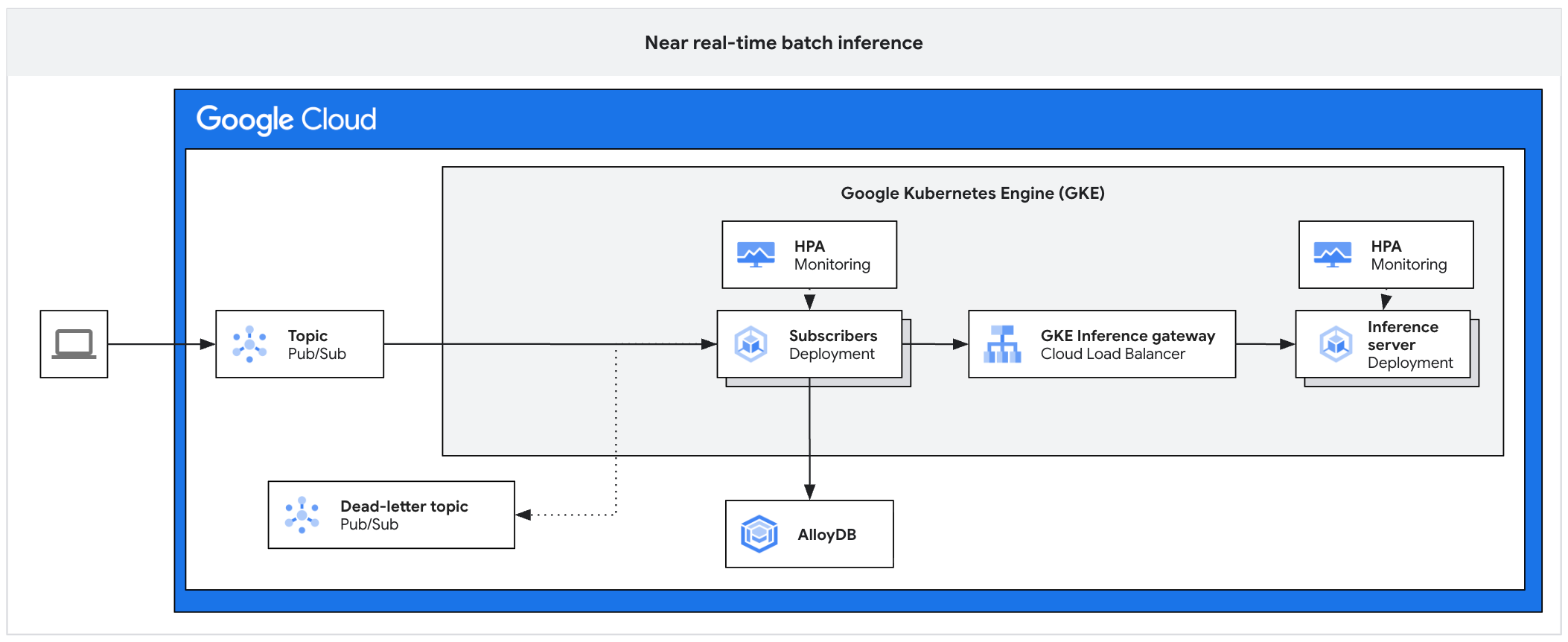
그림 2. GPU HBM → Local SSD → Managed Lustre → Cloud Storage 4단 계층의 매체·역할·GKE 연동 방식과 축출·복귀 흐름
vLLM에서는 –max-num-seqs 같은 플래그로 동시에 처리할 시퀀스 수를 정하고, max_num_batched_tokens로 한 번의 forward pass에 묶을 토큰 수를 정합니다. KV 캐시 메모리가 여유로워지면 이 두 값을 더 크게 잡을 수 있고, 동시 처리 요청 수가 늘어나는 메커니즘이 작동합니다. PagedAttention과 KV 캐시 양자화, 그리고 외부 저장 계층 연결은 이 여유를 만들어내는 세 가지 입력입니다.
적용 시나리오
긴 문서 요약, 코드 어시스턴트, 멀티턴 챗봇처럼 prefix가 길고 반복되는 워크로드가 일순위입니다. 같은 시스템 프롬프트나 코드베이스를 공유하는 요청들이 모이면 prefix caching의 적중률이 올라가고, 캐시 계층이 깊어진 만큼 더 큰 캐시 풀에서 적중을 노릴 수 있습니다.
배치 추론 파이프라인도 동일한 구조를 그대로 차용합니다. 입력 데이터셋을 Cloud Storage나 BigQuery에서 가져와 처리하고, 중간 산출물을 Managed Lustre에 두며, 최종 결과를 다시 객체 스토리지에 적재하는 형태입니다. 이때 Spot VM과 체크포인팅을 결합하면 비용을 더 끌어내릴 수 있습니다. 비동기 추론은 그 사이에 있습니다. 수 초에서 수 분의 지연을 허용하는 사용자 추천 갱신, 소셜 미디어 모니터링, 금융 신호 탐지가 대표적입니다.
vLLM 기준으로 KV 캐시 양자화를 켜는 설정은 다음과 같이 단순합니다.
💻 예시 코드
args:
– –model=$(MODEL_ID)
– –tensor-parallel-size=1
– –kv-cache-dtype=fp8_e5m2
– –max-model-len=1200
KV 캐시 티어링 도입을 검토할 때 짚어야 할 점
도입 결정은 클러스터·노드 사전 조건, 네트워크 구성, 볼륨 확장 정책, 운영·SLO 설계의 4단계로 정리됩니다.
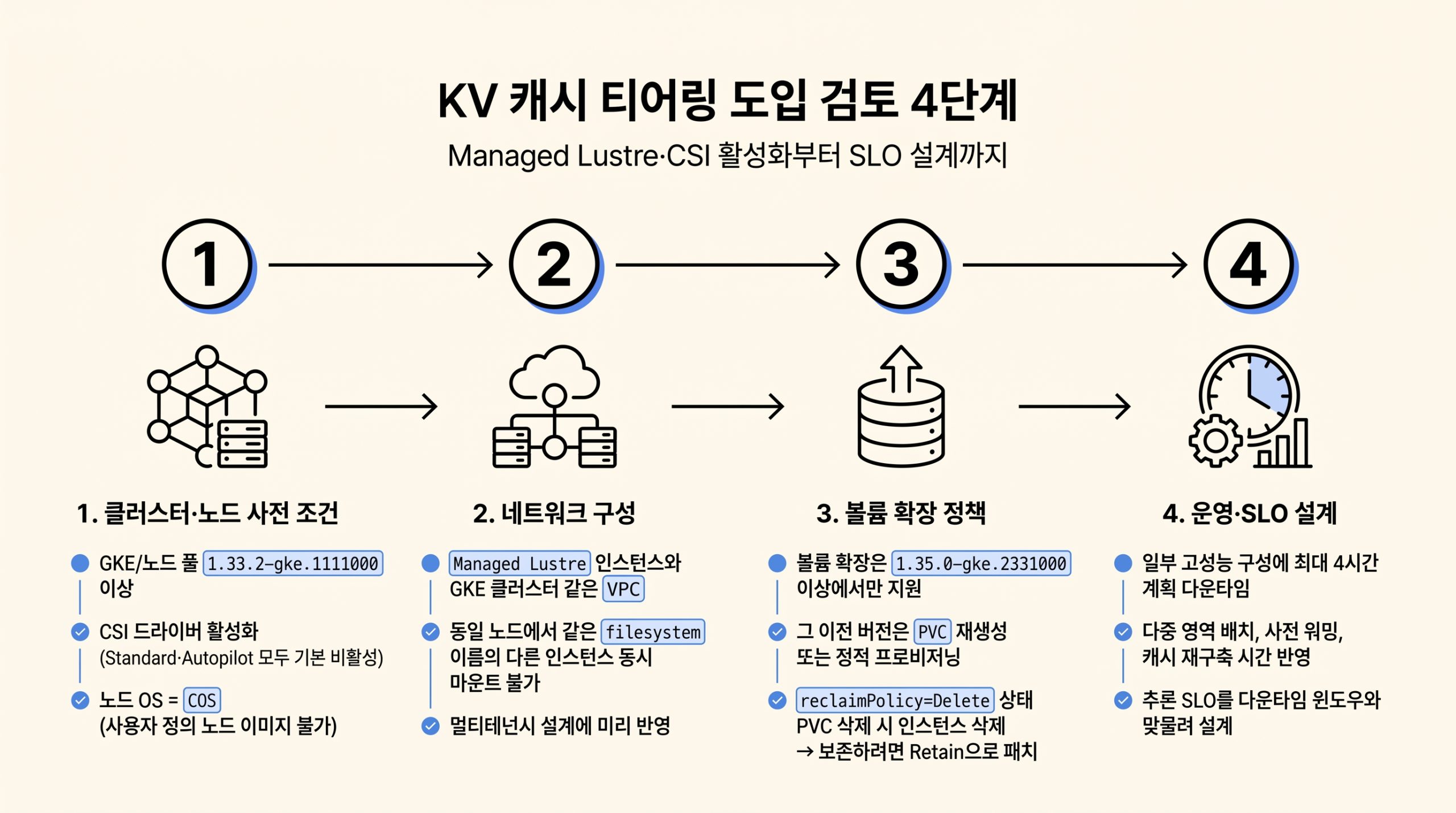
그림 4. 클러스터·CSI 활성화부터 다중 영역 SLO까지, KV 캐시 티어링 도입 검토 4단계.
본 시리즈와의 연결
KV 캐시 티어링은 본 시리즈의 다른 글들과 다음과 같이 이어집니다.
- 본 시리즈 2편에서 다루는 GKE Inference Gateway는 prefix를 인식한 라우팅으로 KV 캐시 적중률을 올립니다. 게이트웨이가 같은 prefix의 요청을 같은 백엔드로 모아주면, 본 글의 메모리 계층화가 만든 캐시 풀이 실제로 적중을 일으킵니다.
- 본 시리즈 6편의 AI 스토리지 다층 전략은 본 글의 Managed Lustre·Cloud Storage 계층을 학습 측면에서 다시 다룹니다. 추론 캐시 풀과 학습 데이터셋이 같은 병렬 파일시스템을 공유할 수 있는지, 분리해야 하는지가 6편의 논의로 이어집니다.
- 본 시리즈 4편의 시작 가속과 의도 기반 오토스케일링은 KV 캐시 티어링이 워밍 비용을 낮춰주는 만큼 더 공격적인 스케일 아웃을 가능하게 합니다. 새 Pod이 기존 캐시 풀에 곧장 붙을 수 있다면 콜드 스타트 부담이 줄어듭니다.
참고 자료
- Google Cloud, “AI infrastructure at Next 26”, https://cloud.google.com/blog/ko/products/compute/ai-infrastructure-at-next26/
- Google Cloud, “Google Cloud Next 2026 wrap-up”, https://cloud.google.com/blog/topics/google-cloud-next/google-cloud-next-2026-wrap-up
- Google Cloud Documentation, “Best practices for optimizing large language model inference with GPUs on Google Kubernetes Engine (GKE)”, https://docs.cloud.google.com/kubernetes-engine/docs/best-practices/machine-learning/inference/llm-optimization
- Google Cloud Documentation, “Best practices for batch inference on GKE”, https://docs.cloud.google.com/kubernetes-engine/docs/best-practices/machine-learning/inference/batch-inference
- Google Cloud Documentation, “Managed Lustre”, https://docs.cloud.google.com/managed-lustre/docs/overview
- Google Cloud Documentation, “Managed Lustre CSI driver overview”, https://docs.cloud.google.com/managed-lustre/docs/lustre-csi-driver-overview
자세한 내용이 궁금하시다면, 메가존소프트 문의포탈을 통해 궁금한 부분을 남겨주세요.