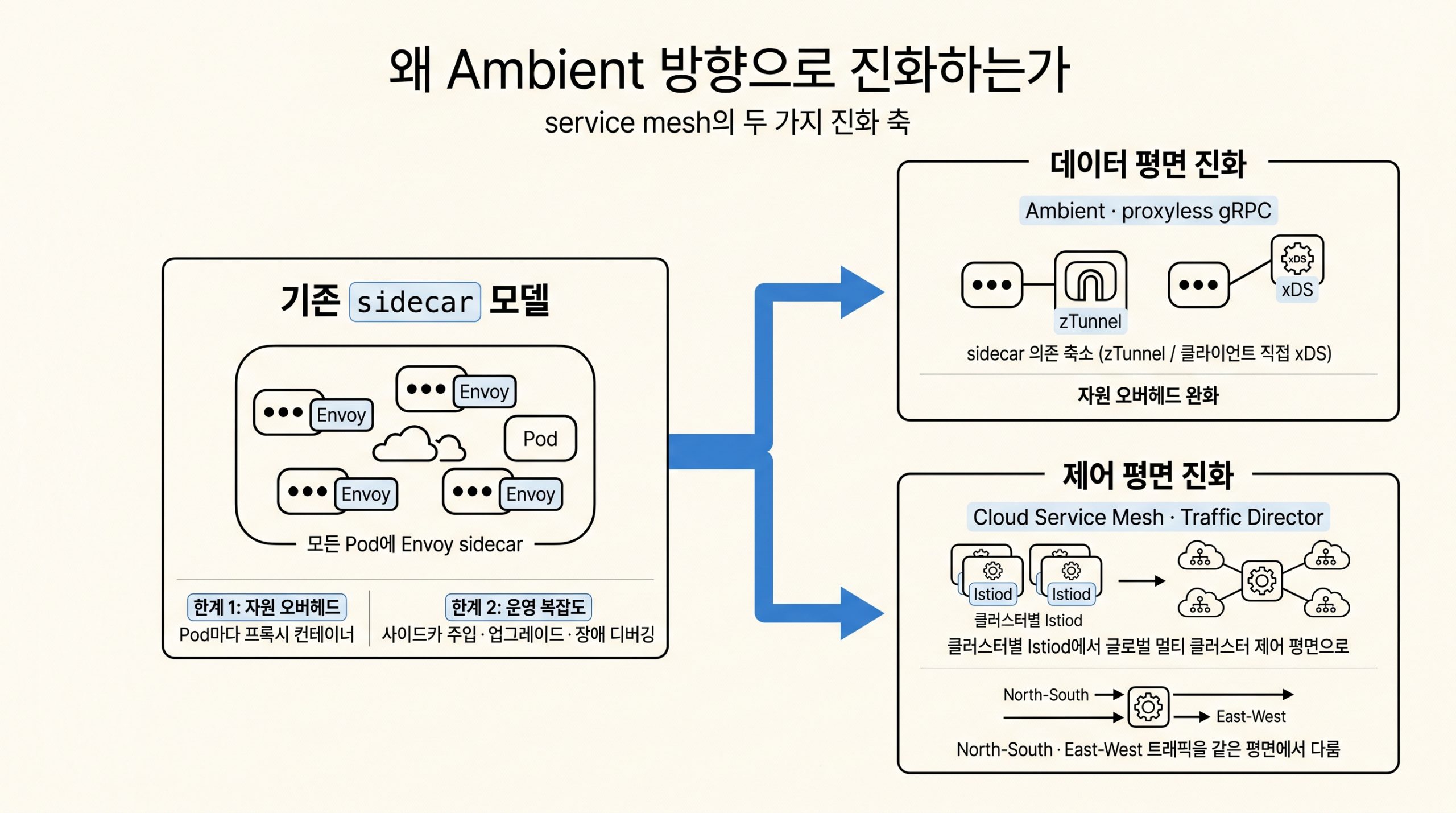
4편: 시작 가속과 의도 기반 오토스케일링
LLM 서빙 Pod의 라이프사이클은 두 시점에서 갈립니다. 새 Pod이 처음 트래픽을 받기까지 걸리는 시간과, 트래픽 변화에 맞춰 복제본 수를 조절하는 판단 시점입니다. 구글 쿠버네티스 엔진(GKE)은 Google Cloud Next 2026에서 이 두 시점을 함께 다루는 기능을 발표했습니다. 컨테이너 이미지와 모델 가중치를 빠르게 끌어오는 시작 가속 기술, 그리고 GPU 사용률 같은 단순 메트릭을 넘어 모델 서버가 내는 신호를 읽는 의도 기반 오토스케일링입니다. 본 시리즈는 Next 2026 GKE 신기능을 추론 인프라, 학습 인프라, 보안과 격리, 네트워킹 4축으로 다루며, 이 글은 추론 인프라 축에 속합니다.
배경: 왜 시작 시간과 스케일링 판단이 같이 묶이는가
LLM 추론은 컨테이너 이미지가 무겁고 가속기가 비싸 시작 시간이 길어지면 GPU·TPU가 놀고, 스케일링 판단이 GPU 사용률 한 메트릭만 보면 LLM의 큐 적체나 KV 캐시 포화를 놓칩니다. 시작 시간 단축과 의도 기반 스케일링은 한 묶음으로 풀어야 LLM 서빙 자동화가 닫힙니다.
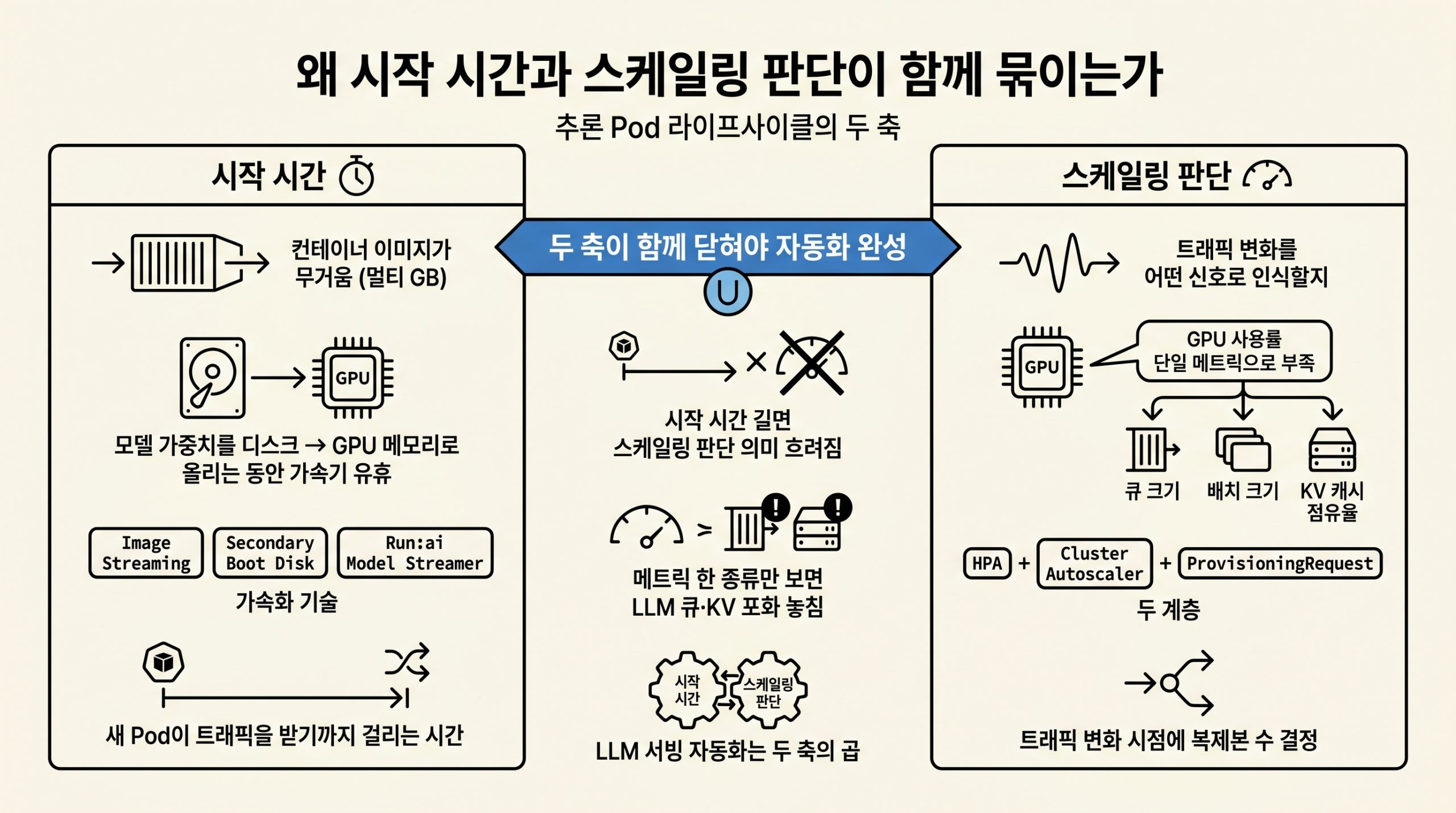
그림 1. 시작 시간(가속화 기술)과 스케일링 판단(LLM 메트릭) 두 축이 함께 닫혀야 LLM 서빙 자동화가 완성됩니다.
시작 가속
Pod 시작 시간을 줄이는 GKE의 세 가지 기술은 서로 다른 계층을 노립니다. 컨테이너 이미지 자체, 노드에 미리 캐시된 디스크, 그리고 모델 가중치 로딩입니다.

그림 2. 시작 가속 3기술이 노리는 계층, 효과, 활성화 방법, 요구 조건을 한눈에 비교.
Image Streaming: 이미지 데이터의 지연 다운로드
Image Streaming은 GKE가 원격 파일 시스템을 root filesystem으로 사용해 워크로드가 실제로 읽는 파일만 즉시 가져오고, 백그라운드에서 이미지를 노드 디스크에 캐시해 두 번째 풀부터는 로컬 캐시로 응답하는 방식입니다. 공식 예시에 따르면 327 MB의 gb-frontend 이미지가 Image Streaming이 켜진 클러스터에서는 약 1.5초, 꺼진 클러스터에서는 약 24초의 Pulled 이벤트로 풀립니다. 효과는 캐시가 형성된 이후의 풀에서 두드러집니다.
활성화에는 Container File System API가 켜져 있어야 하고, 노드 이미지가 COS_CONTAINERD 또는 UBUNTU_CONTAINERD여야 하며, 이미지는 Artifact Registry나 Docker Hub에 올라가 있어야 합니다. V2 Image Manifest schema 1과 중복 레이어가 있는 이미지는 대상 외입니다. Standard 클러스터는 gcloud container clusters update CLUSTER_NAME –enable-image-streaming로 켜고, Autopilot은 적격 이미지에 대해 자동으로 사용합니다.
Secondary Boot Disk: 컨테이너 이미지와 데이터 사전 로드
Secondary Boot Disk는 GKE가 노드를 프로비저닝할 때 미리 만들어둔 영구 디스크(Persistent Disk)에서 컨테이너 이미지나 ML 모델 같은 데이터를 사전 로드한 상태로 노드를 띄워, Image Streaming이 손대지 못하는 첫 풀 단계의 지연까지 앞당깁니다. 컨테이너 이미지 사전 로드는 containerd 런타임 위에서 동작하며, 베이스 레이어처럼 큰 부분을 보조 디스크에 두고 윗단의 작은 레이어는 레지스트리에서 끌어옵니다.
도구로는 gke-disk-image-builder가 제공되고, 노드 풀 생성 시 –secondary-boot-disk 플래그로 디스크 이미지를 지정합니다. Image Streaming과 함께 써야 한다는 요구 조건이 있어 두 기술은 사실상 한 세트이며, 캐시된 컨테이너 이미지의 풀 지연이 이미지 크기와 무관하게 몇 초 이내로 줄어드는 것이 기대 동작입니다.
Run:ai Model Streamer: 모델 가중치를 가속기로 직접 스트리밍
Run:ai Model Streamer는 오픈소스 Python SDK로, 모델 가중치를 Cloud Storage에서 가속기 메모리로 직접 스트리밍해 download-then-load 흐름을 없앱니다. 텐서를 여러 부분으로 나눠 병렬로 읽고, safetensors 파일 포맷과 결합해 zero-copy 접근으로 로컬 메모리를 거치지 않고 텐서에 직접 도달합니다. 공식 문서 기준 가중치 로딩이 기존 방식 대비 최대 6배 빨라집니다. vLLM Deployment에 –load-format=runai_streamer를 추가하면 vLLM이 시작할 때 지정된 gs:// 경로에서 가중치를 스트리밍하며, Cloud Storage 인증 통합은 vLLM 0.11.1 이상에서 지원합니다.
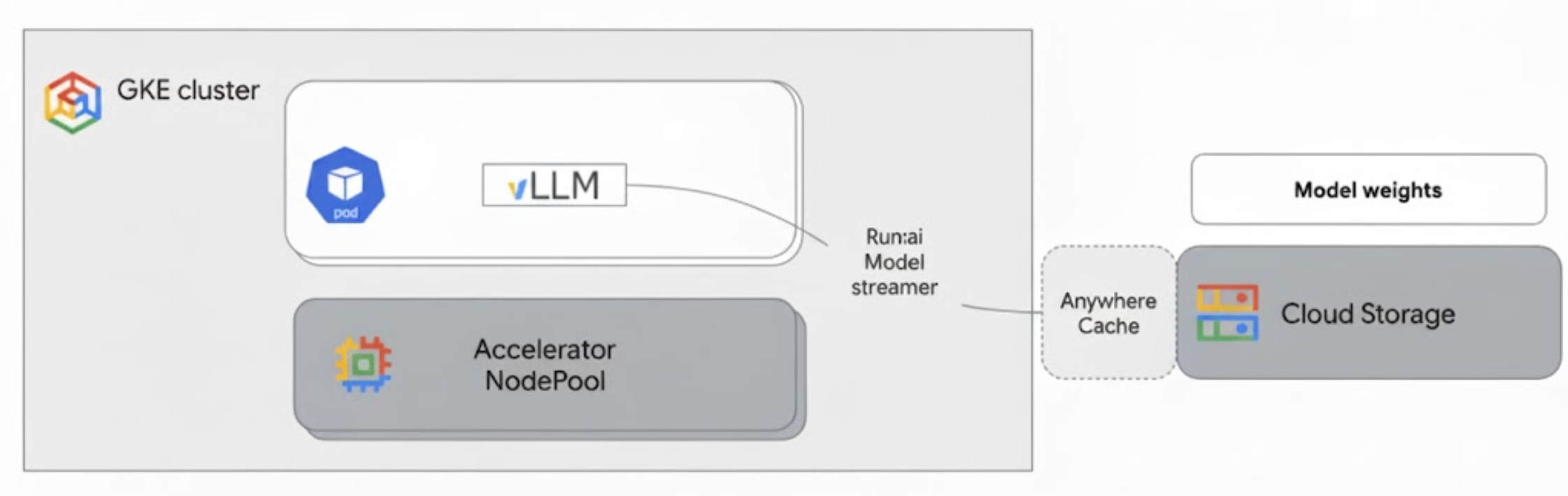
그림 3. Run:ai Model Streamer가 Cloud Storage의 가중치를 GKE Pod의 가속기 메모리로 직접 스트리밍하는 구조.
추가로 Cloud Storage Rapid Cache를 활성화하면 GKE 노드와 같은 존에 버킷 데이터를 캐싱해 스트리머의 데이터 접근을 더 가속할 수 있습니다. 같은 존에서 여러 노드가 스케일아웃되는 환경에서 효과가 큽니다.
의도 기반 오토스케일링
시작 시간을 줄였다면 다음은 언제 얼마만큼 띄울지를 결정하는 단계입니다. GKE의 오토스케일링은 두 계층이 함께 움직입니다. Pod 단위의 HPA, 노드 단위의 클러스터 오토스케일러입니다. LLM 워크로드에서는 두 계층이 모두 모델 서버 신호를 받아들이도록 메트릭을 골라야 합니다.
HPA의 다중 메트릭과 트래픽 기반 스케일링
HPA는 CPU 사용률 외에도 메모리, 외부·커스텀 메트릭, 여러 메트릭을 동시에 보는 구성을 지원합니다. apiVersion: autoscaling/v2로 한 Deployment에 CPU·메모리·커스텀 메트릭을 함께 정의하면 HPA는 가장 큰 스케일링 이벤트를 만드는 메트릭을 따릅니다.
Gateway API로 노출된 워크로드는 트래픽 자체를 스케일링 신호로 쓸 수 있습니다. 트래픽 기반 오토스케일링은 Gateway 컨트롤러의 글로벌 트래픽 관리 기능 위에서 동작하며 GKE 1.31 이상에서 지원됩니다. Service의 GCPBackendPolicy에 maxRatePerEndpoint를 설정하면 HPA는 autoscaling.googleapis.com|gclb-capacity-fullness 메트릭을 보고 Pod 수를 조절합니다.
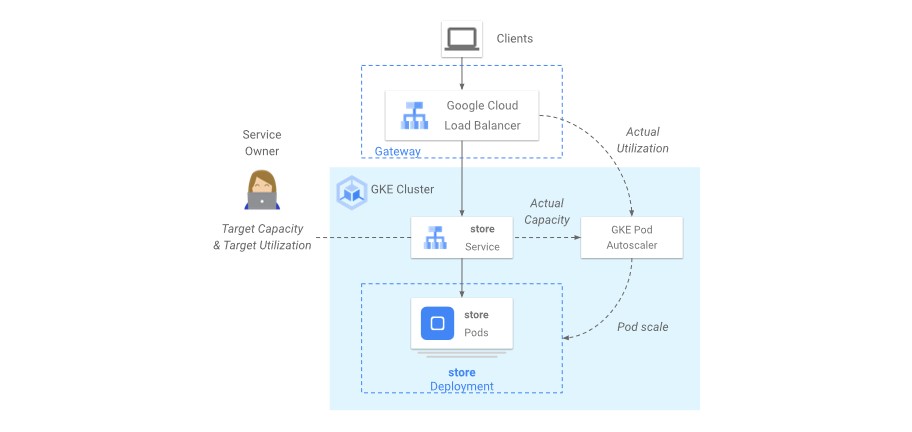
그림 4. Gateway 로드밸런서의 트래픽 신호를 HPA가 받아 Deployment 복제본 수를 조절하는 흐름.
대규모 클러스터를 위해서는 Performance HPA 프로필이 있습니다. HPA 반응 시간을 개선해 1.31~1.32에서는 최대 1,000개, 1.33 이상에서는 최대 5,000개 객체까지 다룰 수 있게 합니다.
LLM 서빙용 메트릭: 큐 크기, 배치 크기, GPU 사용률
LLM 추론 워크로드는 CPU·메모리 사용률로 부하를 깔끔히 매핑하기 어렵기 때문에 GKE 문서는 모델 서버 메트릭(큐 크기, 배치 크기)과 GPU 메트릭(DCGM_FI_DEV_GPU_UTIL, DCGM_FI_DEV_FB_USED)을 축으로 권장합니다. 세 메트릭의 측정 의미와 워크로드 적합성, 임계값 권장, 한계는 다음 인포그래픽으로 정리합니다.
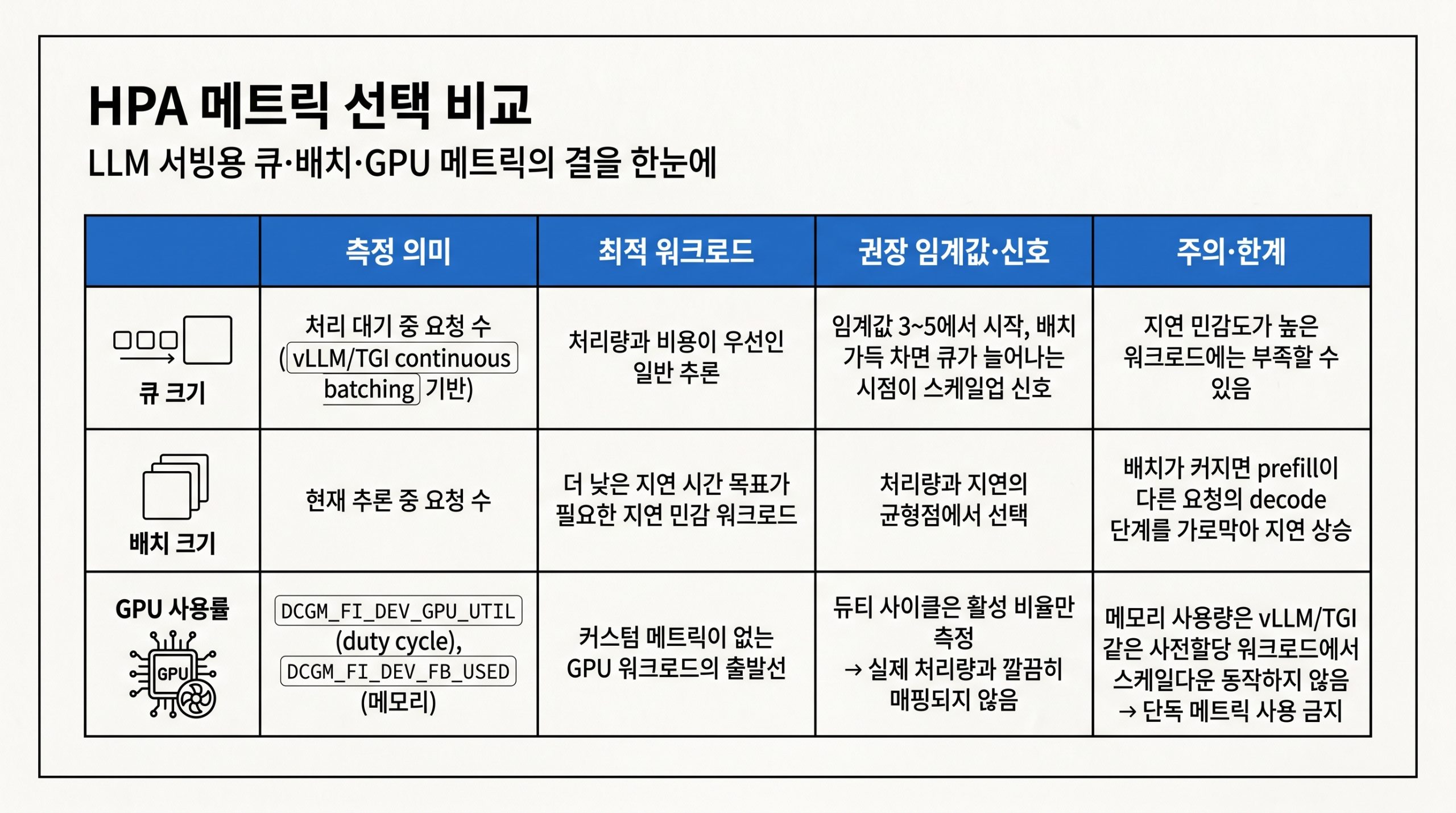
그림 5. 큐 크기·배치 크기·GPU 사용률의 측정 의미, 최적 워크로드, 권장 임계값, 주의 한계 비교.
다음은 TGI의 큐 크기 메트릭으로 HPA를 구성하는 예시입니다.
💻 예시 코드
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: gemma-server
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: tgi-gemma-deployment
minReplicas: 1
maxReplicas: 5
metrics:
– type: Pods
pods:
metric:
name: prometheus.googleapis.com|tgi_queue_size|gauge
target:
type: AverageValue
averageValue: $HPA_AVERAGEVALUE_TARGET
스케일링 동작 자체를 다듬는 옵션도 있습니다. Stabilization window는 메트릭 변동에 따른 잦은 복제본 변경을 막는데, 기본값은 스케일다운 5분, 스케일업 0입니다. Scaling policies로 단위 시간당 변경할 절대 Pod 수와 비율을 한정할 수 있습니다.
클러스터 오토스케일러와 ProvisioningRequest
Pod이 늘어나면 노드도 늘어야 합니다. 클러스터 오토스케일러는 Pod의 리소스 요청을 기반으로 노드 풀의 노드 수를 자동으로 늘리고 줄입니다. 스케일링은 노드 풀별로 일어나며 –min-nodes, –max-nodes 또는 1.24 이상의 –total-min-nodes, –total-max-nodes로 한계를 잡습니다. 1.27 이상에서는 미사용 예약(reservation)을 가진 노드 풀이 스케일업 시 우선됩니다.
LLM 학습이나 큐드 워크로드에는 ProvisioningRequest가 더 맞습니다. ProvisioningRequest는 Pod 그룹 단위로 클러스터 오토스케일러에 용량을 요청하는 namespaced 사용자 정의 리소스(CRD)입니다. 세 가지 ProvisioningClass가 있습니다. queued-provisioning.gke.io는 GKE 전용으로 Dynamic Workload Scheduler와 통합되어 자원이 가용해질 때까지 요청을 큐잉하며, 배치나 지연 허용 워크로드에 적합합니다. check-capacity.autoscaling.x-k8s.io는 스케줄링 전 자원 가용성을 확인하고, best-effort-atomic.autoscaling.x-k8s.io는 모든 Pod에 대한 자원을 한꺼번에 프로비저닝하려 시도하다 일부라도 실패하면 전체를 실패시킵니다.
멀티 호스트 TPU 슬라이스 노드 풀은 토폴로지가 요구하는 노드 수를 모두 동시에 띄우거나 동시에 0으로 내리는 atomic 동작을 합니다. ct5lp-hightpu-4t에 16×16 토폴로지를 쓰는 노드 풀이라면 정확히 0개 또는 64개가 됩니다.
도입을 검토할 때 짚어야 할 점
시작 가속 3기술은 각자 다른 함정을 안고 있어 도입 시 주의 사항과 권장 조치를 함께 챙겨야 합니다.
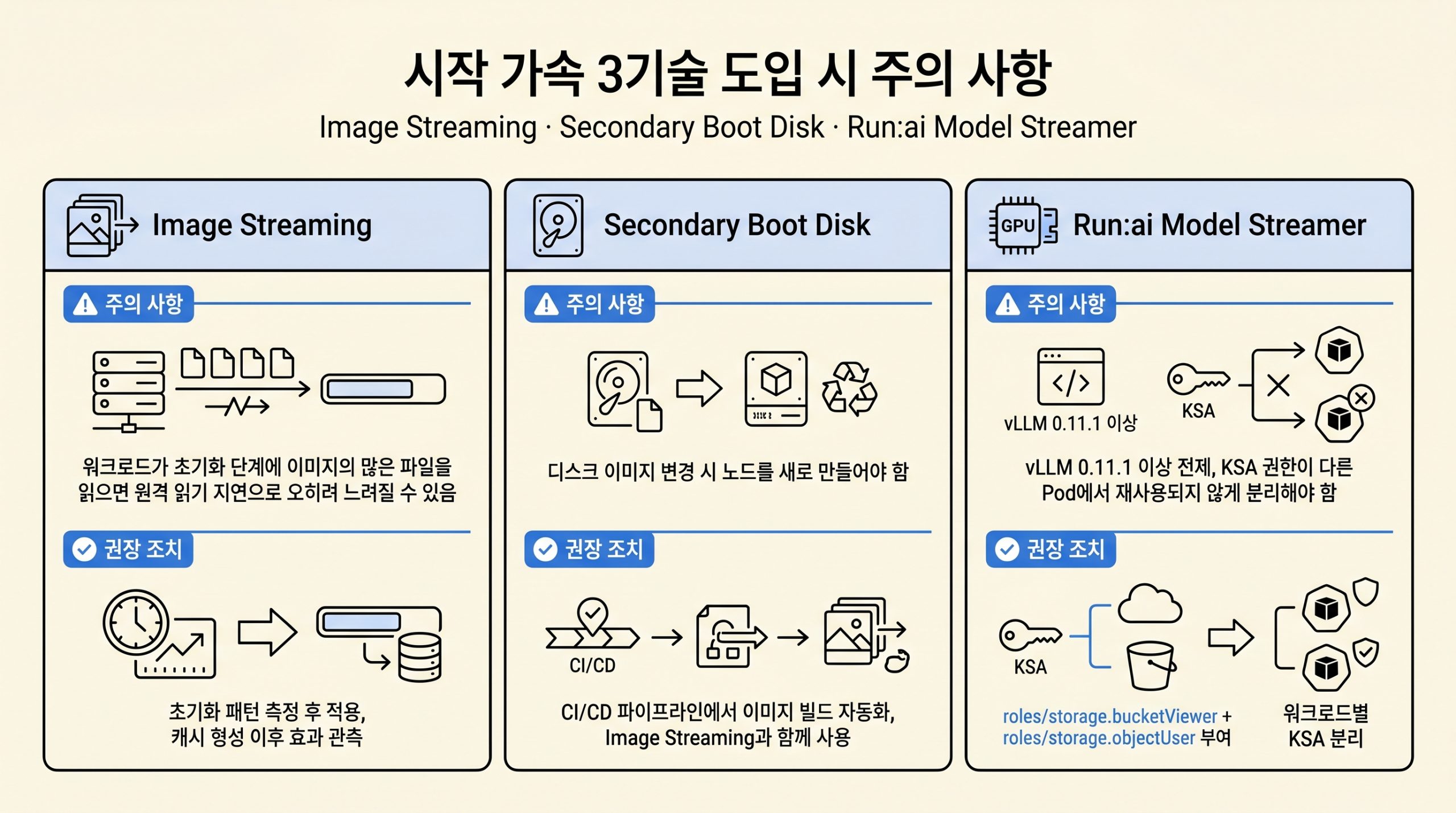
그림 6. 시작 가속 3기술의 주의 사항과 권장 조치를 한 화면에 정리
HPA 메트릭 선택은 워크로드 성격을 따릅니다. 처리량과 비용이 우선이면 큐 크기, 지연 민감도가 우선이면 배치 크기, 커스텀 메트릭이 없는 GPU 워크로드에는 GPU 사용률이 출발선이며, GPU 메모리 사용량은 사전 할당 워크로드에서 스케일다운이 동작하지 않으므로 단독 메트릭으로 쓰지 않습니다. 클러스터 오토스케일러는 Pod의 실제 사용량이 아니라 리소스 요청을 기준으로 결정하므로 요청을 명시적으로 적어야 합니다.
본 시리즈와의 연결
시작 가속과 의도 기반 오토스케일링은 본 시리즈의 다른 글들과 다음과 같이 이어집니다.
- 본 시리즈 2편에서 다루는 GKE Inference Gateway는 KV 캐시 사용률 같은 모델 서버 메트릭으로 라우팅하는데, 본편의 HPA 메트릭과 같은 결의 신호를 활용합니다. 같이 보면 라우팅과 스케일링이 어떻게 같은 신호를 공유하는지가 보입니다.
- 본 시리즈 3편의 KV 캐시 티어링은 본편이 가속하는 Pod 시작 직후의 메모리 계층화를 다룹니다. 모델 가중치가 가속기에 올라온 다음 KV 캐시가 어떻게 계층화되는지가 3편의 주제입니다.
- 본 시리즈 6편의 AI 스토리지 다층 전략은 본편의 Run:ai Model Streamer와 Cloud Storage Rapid Cache를 더 큰 스토리지 그림 안에 배치합니다. Hyperdisk ML이나 Managed Lustre 같은 다른 옵션과 함께 살펴볼 수 있습니다.
참고 자료
- Google Cloud, “AI infrastructure at Next 26”, https://cloud.google.com/blog/ko/products/compute/ai-infrastructure-at-next26/
- Google Cloud, “Google Cloud Next 2026 wrap-up”, https://cloud.google.com/blog/topics/google-cloud-next/google-cloud-next-2026-wrap-up
- Google Cloud Documentation, “Use Image streaming to pull container images”, https://docs.cloud.google.com/kubernetes-engine/docs/how-to/image-streaming
- Google Cloud Documentation, “Use secondary boot disks to preload data or container images”, https://docs.cloud.google.com/kubernetes-engine/docs/how-to/data-container-image-preloading
- Google Cloud Documentation, “Accelerate model loading on GKE with Run:ai Model Streamer”, https://docs.cloud.google.com/kubernetes-engine/docs/how-to/persistent-volumes/run-ai-model-streamer
- Google Cloud Documentation, “About GKE cluster autoscaling”, https://docs.cloud.google.com/kubernetes-engine/docs/concepts/cluster-autoscaler
- Google Cloud Documentation, “Configuring horizontal Pod autoscaling”, https://docs.cloud.google.com/kubernetes-engine/docs/how-to/horizontal-pod-autoscaling
- Google Cloud Documentation, “Configure autoscaling for LLM workloads on GPUs with GKE”, https://docs.cloud.google.com/kubernetes-engine/docs/how-to/machine-learning/inference/autoscaling
- Google Cloud Documentation, “Best practices for autoscaling LLM inference workloads with GPUs on GKE”, https://docs.cloud.google.com/kubernetes-engine/docs/best-practices/machine-learning/inference/autoscaling
자세한 내용이 궁금하시다면, 메가존소프트 문의포탈을 통해 궁금한 부분을 남겨주세요.