2편: GKE Inference Gateway로 LLM 서빙 표준화
GKE Inference Gateway는 구글 쿠버네티스 엔진(GKE) 위에서 대규모 언어 모델(LLM) 서빙을 표준화하는 추론 최적화 로드밸런서입니다. Google Cloud Next 2026에서 강조된 이 컴포넌트는 vLLM·TGI·JetStream 같은 모델 서버 위에 얹혀, 일반 HTTP 로드밸런서가 보지 못하는 KV 캐시 점유율, 요청 큐 길이, LoRA 어댑터 가용성 같은 추론 고유 신호를 라우팅 결정에 직접 활용합니다. 본 글은 이 게이트웨이의 구성 요소와 동작 원리를 정리하고, GKE 위에서 LLM을 운영하는 플랫폼 엔지니어가 어떤 결정을 내려야 하는지 살펴봅니다. 본 시리즈는 Next 2026 GKE 신기능을 추론 인프라, 학습 인프라, 보안과 격리, 네트워킹의 4축으로 다루며, 이 글은 추론 인프라 축에 속합니다.
배경: 왜 추론 전용 게이트웨이가 등장했는가
LLM 추론 트래픽은 요청별 토큰 수와 prefill 비용이 균일하지 않고 모델 서버가 attention의 K, V 텐서를 메모리에 들고 있어, 라우팅 결정이 연결 수가 아닌 GPU 메모리 상태에 좌우됩니다. 일반 Application Load Balancer는 이 결을 보지 못해 세 가지 한계에 부딪히고, GKE Inference Gateway는 Gateway API 확장과 추론 전용 CRD로 모델 서버의 내부 신호를 라우팅 평면으로 끌어올려 그 간극을 메웁니다.
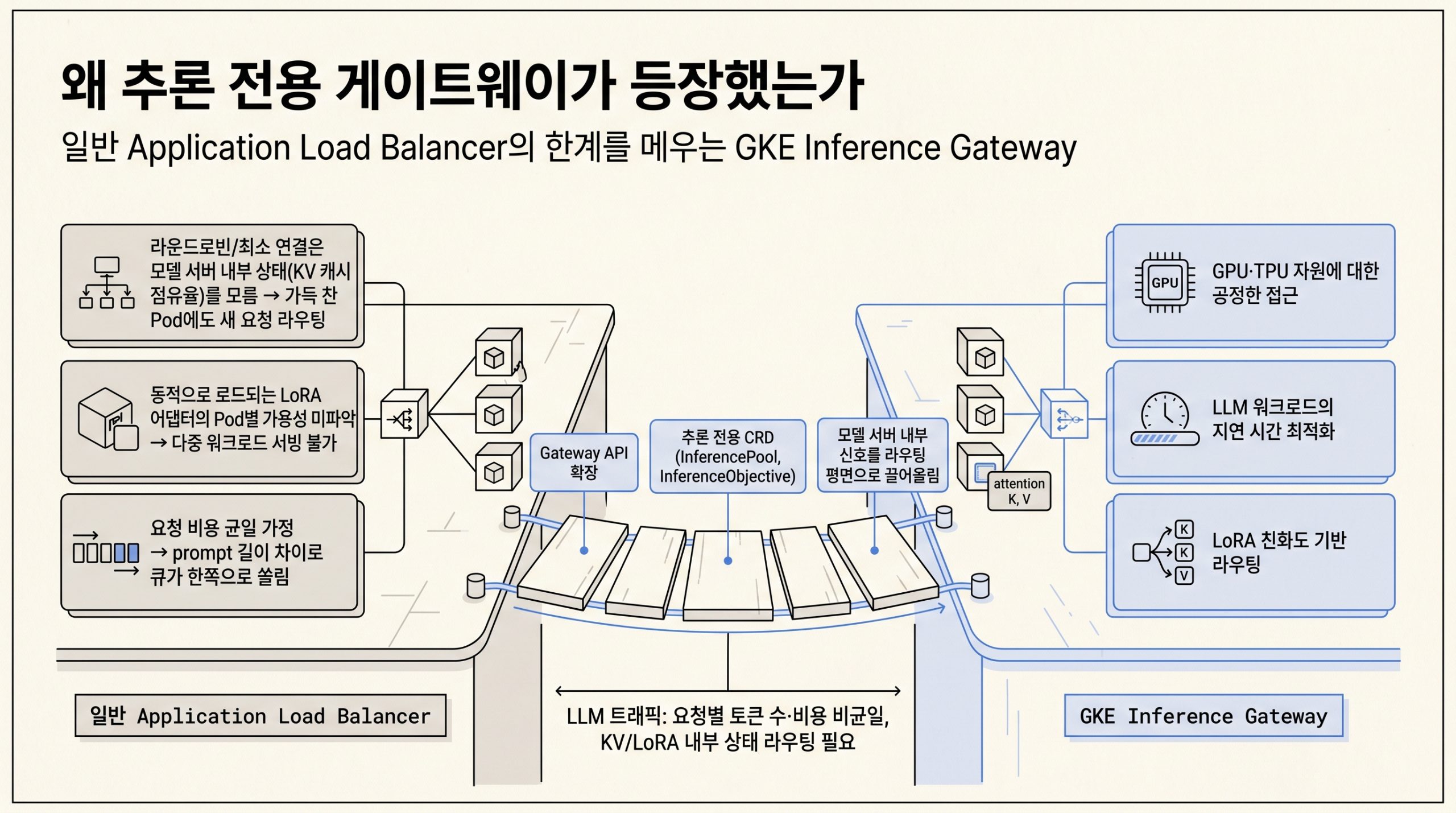
그림 1. 일반 Application Load Balancer의 세 가지 한계와 GKE Inference Gateway가 Gateway API 확장·전용 CRD·모델 서버 신호로 메우는 방식
아키텍처 한눈에 보기
GKE Inference Gateway는 표준 Gateway API 위에 얹힌 확장 계층입니다. 외부 클라이언트가 Gateway 리소스로 진입해 HTTPRoute로 경로를 매칭한 뒤 일반 Service가 아닌 InferencePool이 백엔드 모델 서버 Pod 그룹을 가리키며, 게이트웨이는 라운드로빈이 아니라 다섯 가지 추론 고유 신호를 묶어 가장 덜 부하된 복제본으로 트래픽을 분배합니다.
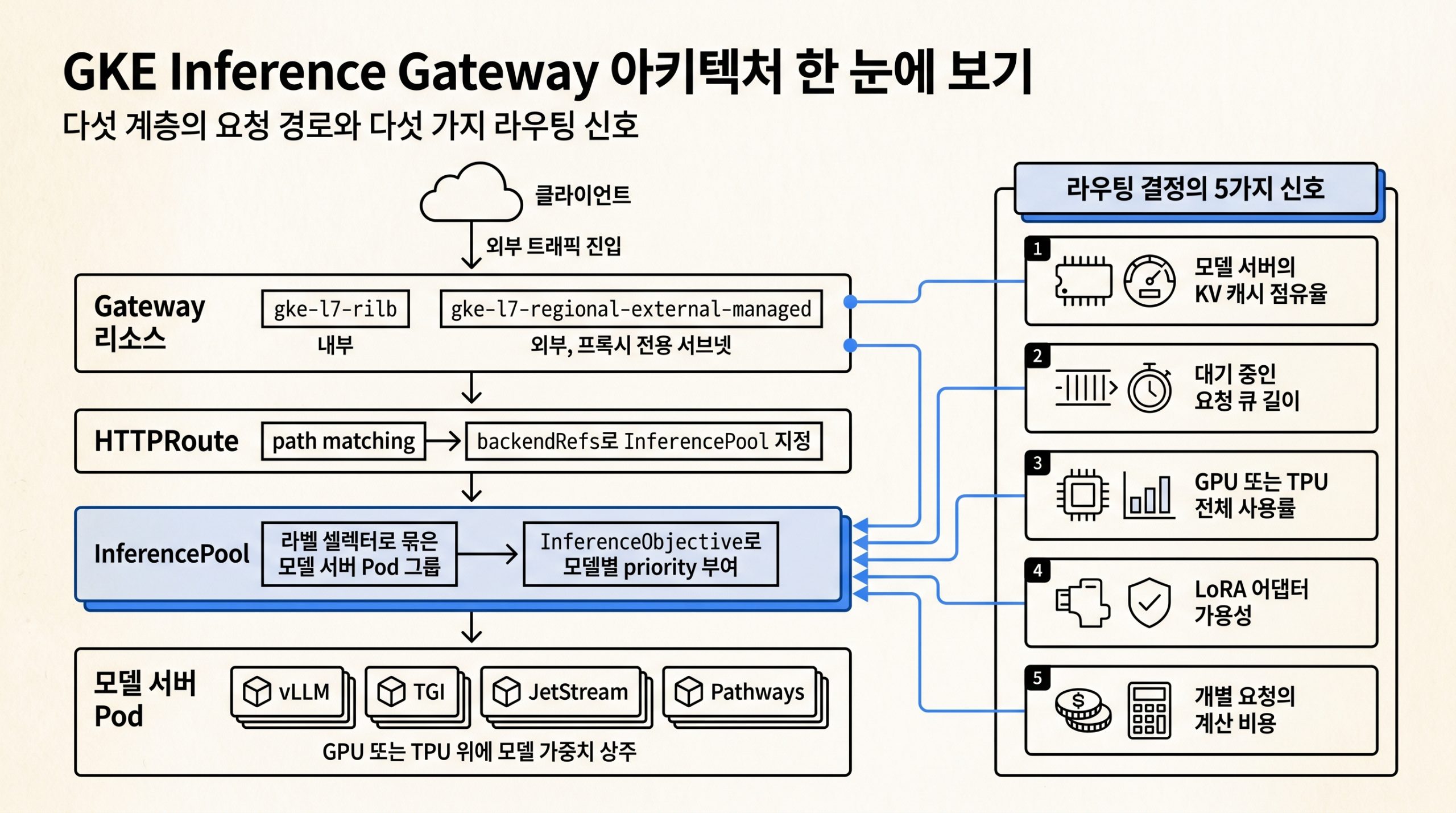
그림 2. 클라이언트부터 모델 서버 Pod까지의 5계층 요청 경로와 라우팅 결정의 5가지 신호.
주요 구성 요소
GKE Inference Gateway는 두 개의 CRD를 중심에 둡니다.
- InferencePool: 동일한 베이스 LLM과 컴퓨트 구성을 공유하는 Pod 그룹의 논리적 단위입니다. selector로 모델 서버 Pod을 묶고, targetPort로 모델 서버가 노출하는 포트를 지정합니다.
- InferenceObjective: 풀 위에서 서빙되는 개별 모델의 운영 파라미터를 정의합니다. metadata.name이 모델 이름, priority가 서빙 중요도, poolRef가 연결된 InferencePool을 가리킵니다. 베이스 모델과 LoRA 어댑터 모두 같은 풀 안에서 별도의 InferenceObjective로 구분됩니다.
다음은 food-review LoRA 모델을 우선순위 10으로, llama3-base-model을 우선순위 20으로 같은 풀에 등록하는 예시입니다.
💻 예시 코드
apiVersion: inference.networking.k8s.io/v1alpha1
kind: InferenceObjective
metadata:
name: food-review
spec:
priority: 10
poolRef:
name: vllm-llama3.1-8b-instruct
kind: “InferencePool”
—
apiVersion: inference.networking.k8s.io/v1alpha1
kind: InferenceObjective
metadata:
name: llama3-base-model
spec:
priority: 20
poolRef:
name: vllm-llama3.1-8b-instruct
kind: “InferencePool”
게이트웨이 아래의 모델 서버 계층은 프레임워크가 담당합니다. vLLM은 PagedAttention으로 KV 캐시 단편화를 줄이고, continuous batching으로 디코딩 슬롯을 빈틈없이 채우며, 텐서 병렬화로 단일 GPU 메모리를 넘는 모델을 여러 GPU에 쪼개 올립니다. TGI는 quantization 옵션(awq, gptq, eetq, bitsandbytes, bitsandbytes-nf4, bitsandbytes-fp4)을 지원해 작은 가속기에서도 큰 모델을 돌릴 수 있게 합니다. JetStream과 Pathways는 멀티호스트 TPU 노드 풀 위에서 대형 모델을 분산 서빙합니다. 멀티호스트 TPU 슬라이스 노드 풀이 JetStream Deployment와 Pathways 구성 요소를 함께 호스팅하며, Pathways resource manager가 가속기 자원을 관리하고 사용자 작업의 가속기 할당을 조정합니다.
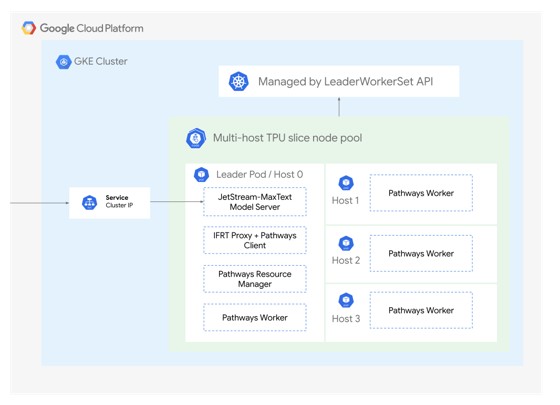
그림 3. JetStream과 Pathways 위에서 동작하는 멀티호스트 TPU 노드 풀 구성
vLLM은 FP8 E5M2와 E4M3 형식의 KV 캐시 양자화도 제공해 큰 배치 크기에서 메모리 사용량을 줄입니다.
InferencePool은 베이스 LLM을 공유하는 풀 단위로 묶이므로, 풀 자체가 어떤 가속기 위에 어떤 프레임워크로 올려졌는지에 따라 운영 특성이 달라집니다.
동작 흐름
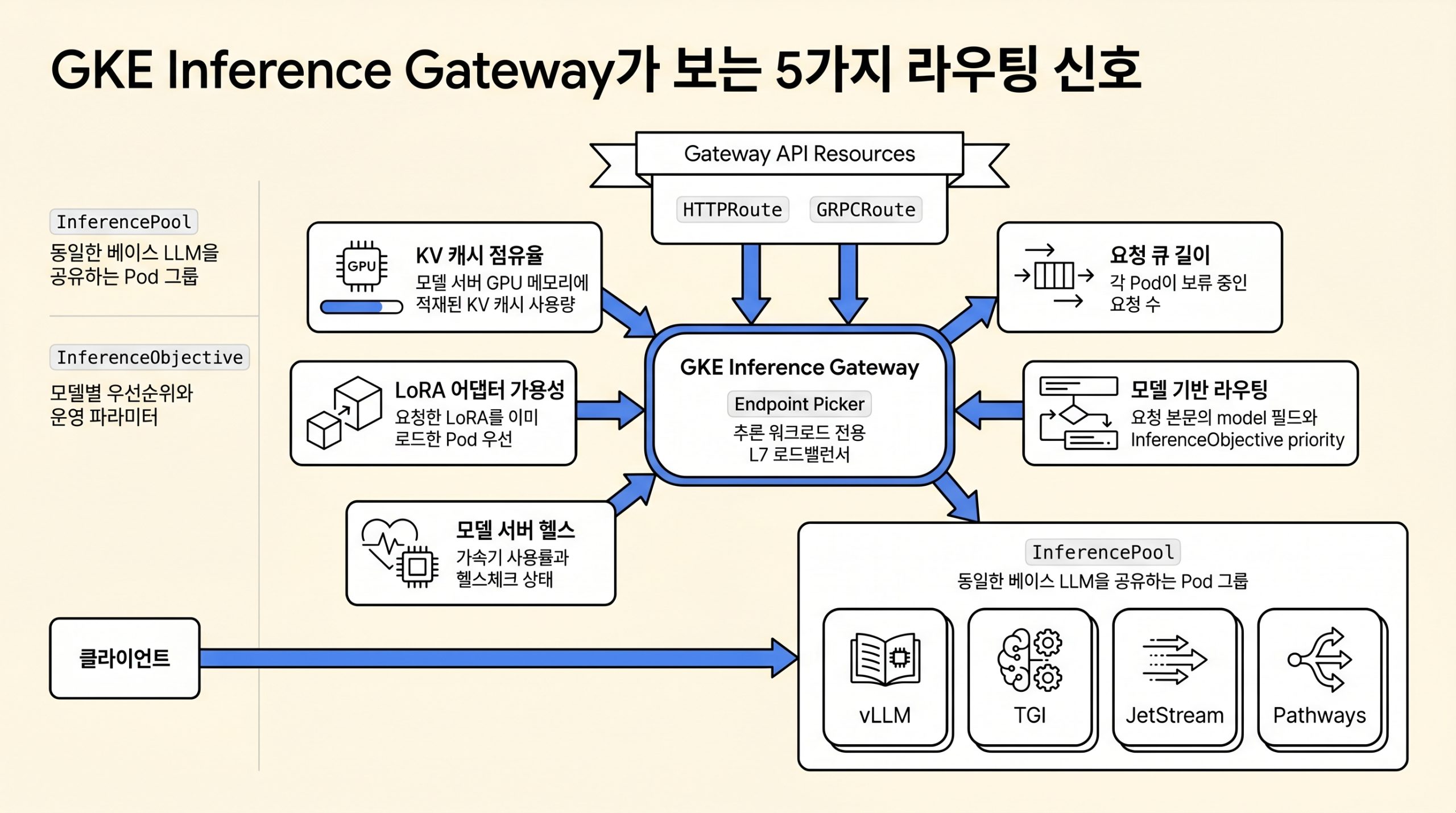
그림 4. GKE Inference Gateway가 라우팅 결정에 사용하는 추론 고유 신호와 핵심 백엔드
요청 한 건이 GKE Inference Gateway를 통과하는 흐름은 다음과 같습니다.
- 클라이언트가 Gateway의 외부 IP로 HTTP POST 요청을 보냅니다. 본문에는 model 필드가 포함됩니다.
- HTTPRoute가 요청 경로를 매칭하고, backendRefs에 지정된 InferencePool로 라우팅을 위임합니다.
- 게이트웨이의 Endpoint Picker가 InferencePool 안의 후보 Pod 목록을 받아옵니다. 이때 KV 캐시 점유율, 큐 길이, 가속기 사용률, 요청 본문에 명시된 모델이 LoRA 어댑터일 경우 해당 어댑터를 이미 로드한 Pod의 affinity를 함께 고려합니다.
- 선택된 Pod의 모델 서버가 요청을 받아 추론을 수행하고 응답을 반환합니다. vLLM 기준 /v1/completions 엔드포인트를 사용합니다.
- InferenceObjective의 priority 값이 높은 요청은 혼잡 상황에서 낮은 우선순위 요청보다 먼저 처리됩니다.
InferencePool을 Helm으로 설치할 때는 다음 명령을 사용합니다.
💻 예시 코드
helm install vllm-llama3.1-8b-instruct \
–set inferencePool.modelServers.matchLabels.app=vllm-llama3.1-8b-instruct \
–set provider.name=gke \
–set healthCheckPolicy.create=false \
–version v1.0.0 \
oci://registry.k8s.io/gateway-api-inference-extension/charts/inferencepool
이 명령은 app=vllm-llama3.1-8b-instruct 라벨을 가진 Pod을 자동으로 선택해 풀에 묶습니다.
적용 시나리오
GKE Inference Gateway는 동기 요청뿐 아니라 비동기 추론 플랫폼 앞단에도 놓입니다. Pub/Sub 토픽을 영속 버퍼로 두고 Subscriber가 메시지 배치를 읽어 추론 게이트웨이로 보내는 구조에서, 게이트웨이는 동기 요청과 동일한 라우팅·우선순위·관측 신호를 그대로 적용합니다.
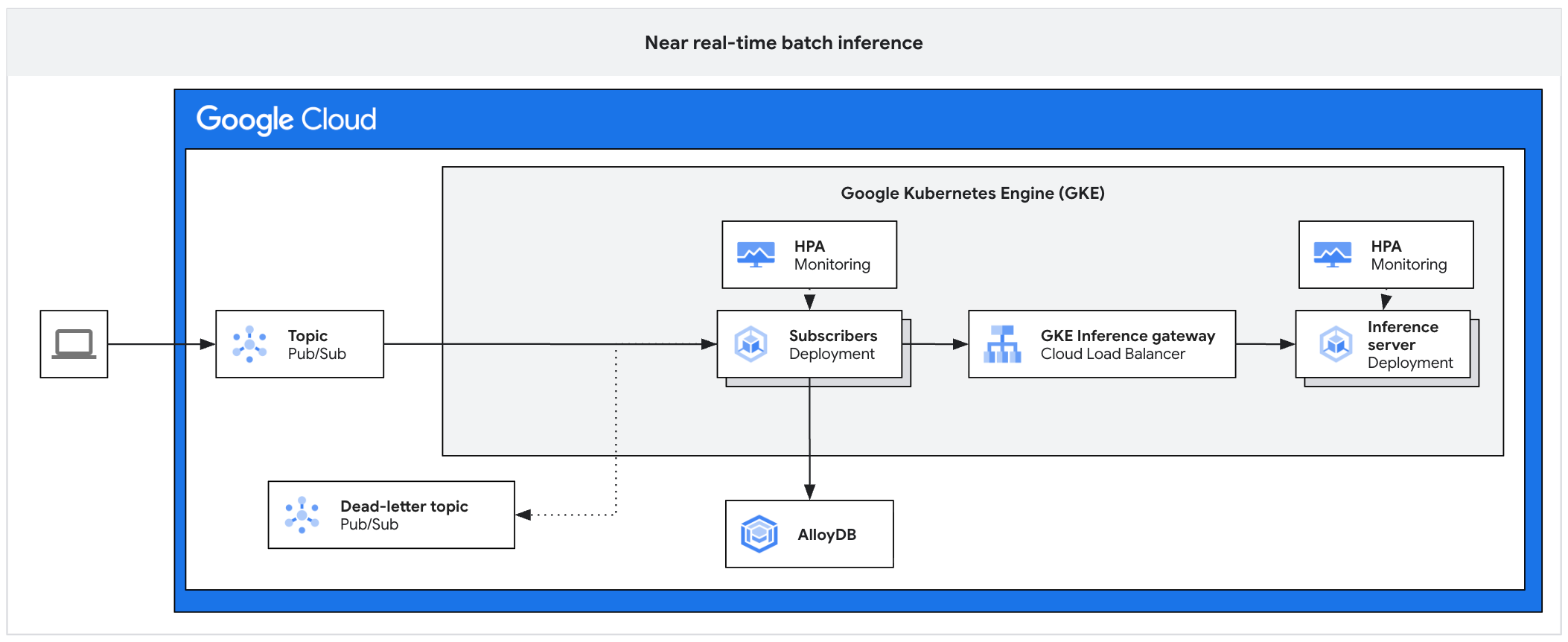
그림 5. GKE 위 비동기 추론 플랫폼 아키텍처
GKE Inference Gateway는 다음 상황에서 효과가 분명합니다.
- vLLM 같은 모델 서버를 사용하면서 KV 캐시 점유율이나 요청 큐 길이 기반의 라우팅 결정이 필요한 LLM 서빙
- 한 모델 서버 풀 위에 여러 LoRA 어댑터를 얹어 다중 워크로드를 동시에 서빙하는 구성
- 동적인 프롬프트 길이로 요청별 처리 비용이 크게 차이 나는 워크로드
- critical, standard, sheddable 같은 요청 등급을 두고 우선순위 처리가 필요한 트래픽
- KV 캐시 점유율 같은 추론 고유 신호에 묶인 오토스케일링이 필요한 모델 서버
- Model Armor를 게이트웨이 단에서 적용해 입출력 콘텐츠를 점검하려는 경우
도입을 검토할 때 짚어야 할 점
게이트웨이 자체는 무료지만 운영 결정은 다섯 갈래로 나뉩니다. Gateway 클래스 선택, 모델 서버 프레임워크 선택, LoRA 어댑터 운영 모델, 관측성 구성, 그리고 preStop과 종료 그레이스 기간입니다. 각 단계의 핵심 선택지는 다음 인포그래픽으로 정리합니다.
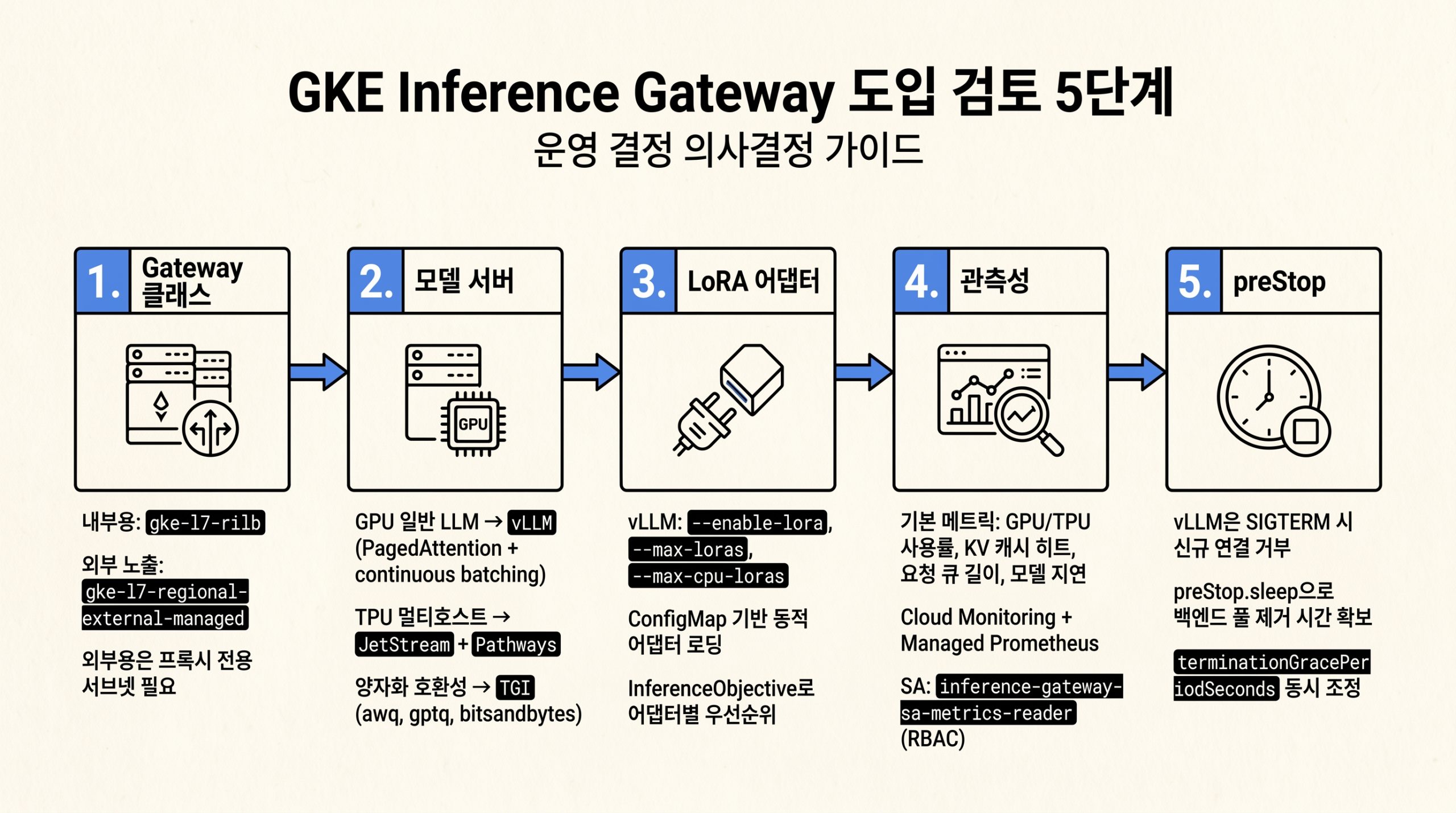
그림 6. Gateway 클래스부터 preStop까지, 운영 결정 5단계의 핵심 선택지
본 시리즈와의 연결
GKE Inference Gateway는 본 시리즈의 다른 글들과 다음과 같이 이어집니다.
- 본 시리즈 3편에서 다루는 KV 캐시 티어링은 게이트웨이가 라우팅 신호로 쓰는 바로 그 KV 캐시 자체를 어떻게 메모리 계층 사이에서 분산·재사용하는지 설명합니다. 게이트웨이가 KV 캐시 점유율을 보고 분배할 때, 그 캐시가 GPU 안에만 있는지 아니면 호스트 메모리·로컬 SSD까지 확장되어 있는지에 따라 라우팅 의미가 달라집니다.
- 본 시리즈 4편의 시작 가속과 의도 기반 오토스케일링은 게이트웨이가 만들어내는 KV 캐시·큐 길이 신호를 받아 모델 서버 복제본 수를 조정합니다. 새 복제본의 콜드 스타트 시간이 짧을수록 게이트웨이의 우선순위·셰딩 정책도 더 정교하게 동작합니다.
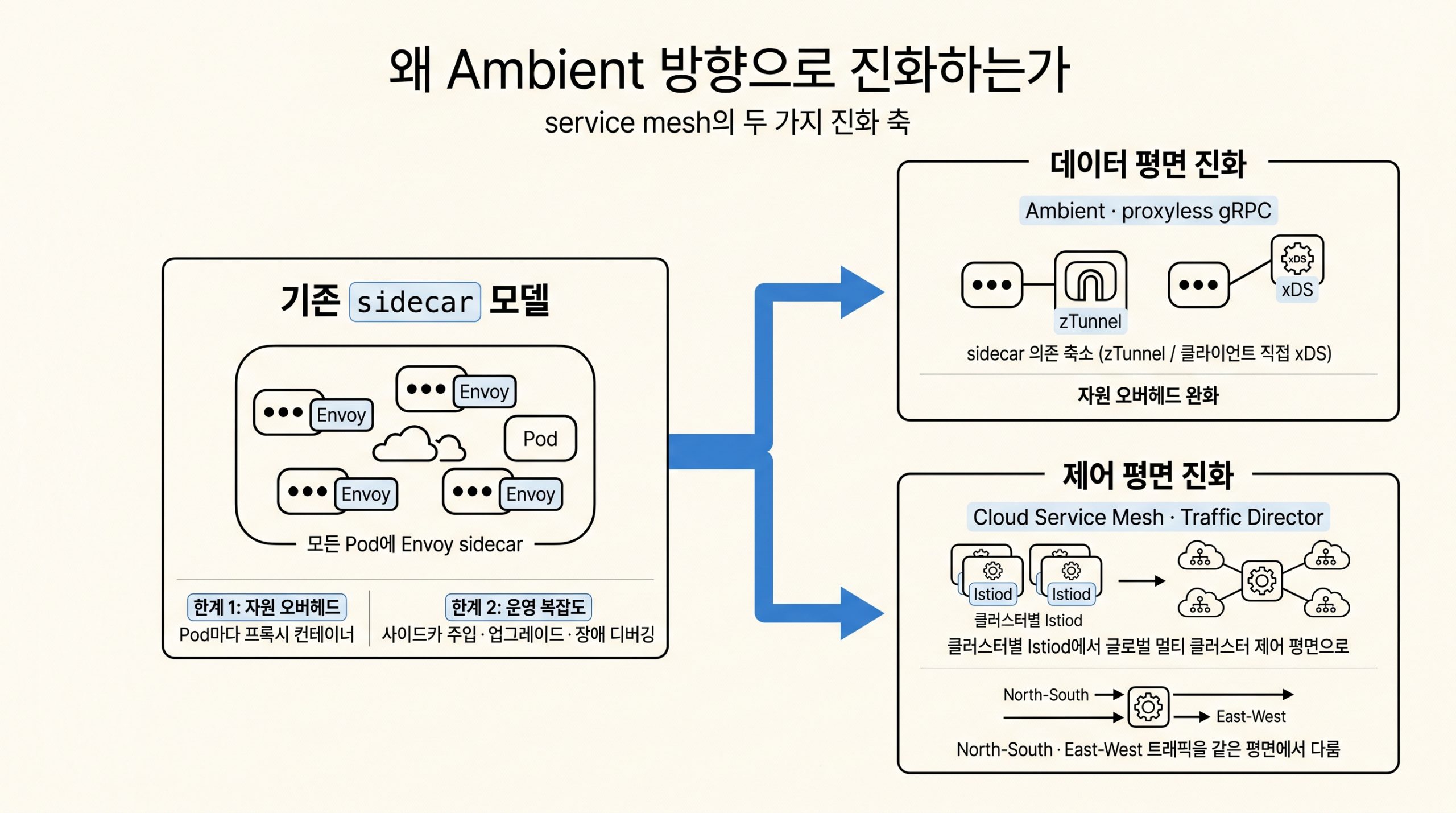
외전인 Ambient 네트워킹과 Cloud Service Mesh는 게이트웨이가 처리한 North-South 트래픽을 클러스터 내부의 East-West 경로와 연결할 때 함께 검토할 수 있습니다.
참고 자료
- Google Cloud, “AI infrastructure at Next 26”, https://cloud.google.com/blog/ko/products/compute/ai-infrastructure-at-next26/
- Google Cloud, “Google Cloud Next 2026 wrap-up”, https://cloud.google.com/blog/topics/google-cloud-next/google-cloud-next-2026-wrap-up
- Google Cloud Documentation, “About AI/ML model inference on GKE”, https://docs.cloud.google.com/kubernetes-engine/docs/concepts/machine-learning/inference
- Google Cloud Documentation, “Choose a load balancing strategy for AI/ML model inference on GKE”, https://docs.cloud.google.com/kubernetes-engine/docs/concepts/machine-learning/choose-lb-strategy
- Google Cloud Documentation, “Serve an LLM with GKE Inference Gateway”, https://docs.cloud.google.com/kubernetes-engine/docs/tutorials/serve-with-gke-inference-gateway
- Google Cloud Documentation, “Best practices for optimizing large language model inference with GPUs on GKE”, https://docs.cloud.google.com/kubernetes-engine/docs/best-practices/machine-learning/inference/llm-optimization
- Google Cloud Documentation, “Best practices for batch inference on GKE”, https://docs.cloud.google.com/kubernetes-engine/docs/best-practices/machine-learning/inference/batch-inference
- Google Cloud Documentation, “Serve an LLM on multi-host TPUs with JetStream and Pathways”, https://docs.cloud.google.com/kubernetes-engine/docs/tutorials/serve-multihost-tpu-jetstream
자세한 내용이 궁금하시다면, 메가존소프트 문의포탈을 통해 궁금한 부분을 남겨주세요.