6편: AI 스토리지 다층 전략
AI/ML 워크로드는 한 가지 스토리지로 처리되지 않습니다. 데이터 준비 단계에서 거대한 원본 데이터셋을 모아두는 곳과 학습 도중 체크포인트를 빠르게 쓰는 곳, 추론 시점에 모델 가중치를 GPU로 끌어올리는 곳은 요구 조건이 다릅니다. 본 글은 구글 쿠버네티스 엔진(GKE)이 제공하는 스토리지 옵션을 워크로드 단계별로 어떻게 매핑하는지 정리합니다. 이 글은 학습 인프라 축에 속합니다
배경: 왜 다층 스토리지가 필요한가
AI/ML 워크로드는 데이터 준비, 학습, 체크포인트 저장, 추론(모델 로드) 4단계마다 입출력 패턴이 달라 단일 스토리지로 묶기 어렵습니다. GKE는 영구 디스크(Persistent Disk), Hyperdisk, Hyperdisk Storage Pools, Local SSD, Managed Lustre, Filestore, Cloud Storage 옵션을 단계별로 골라 쓰도록 설계되었고, PV·PVC·StorageClass 추상화 위에 컨테이너 스토리지 인터페이스(CSI) 드라이버가 각 백엔드를 연결합니다.
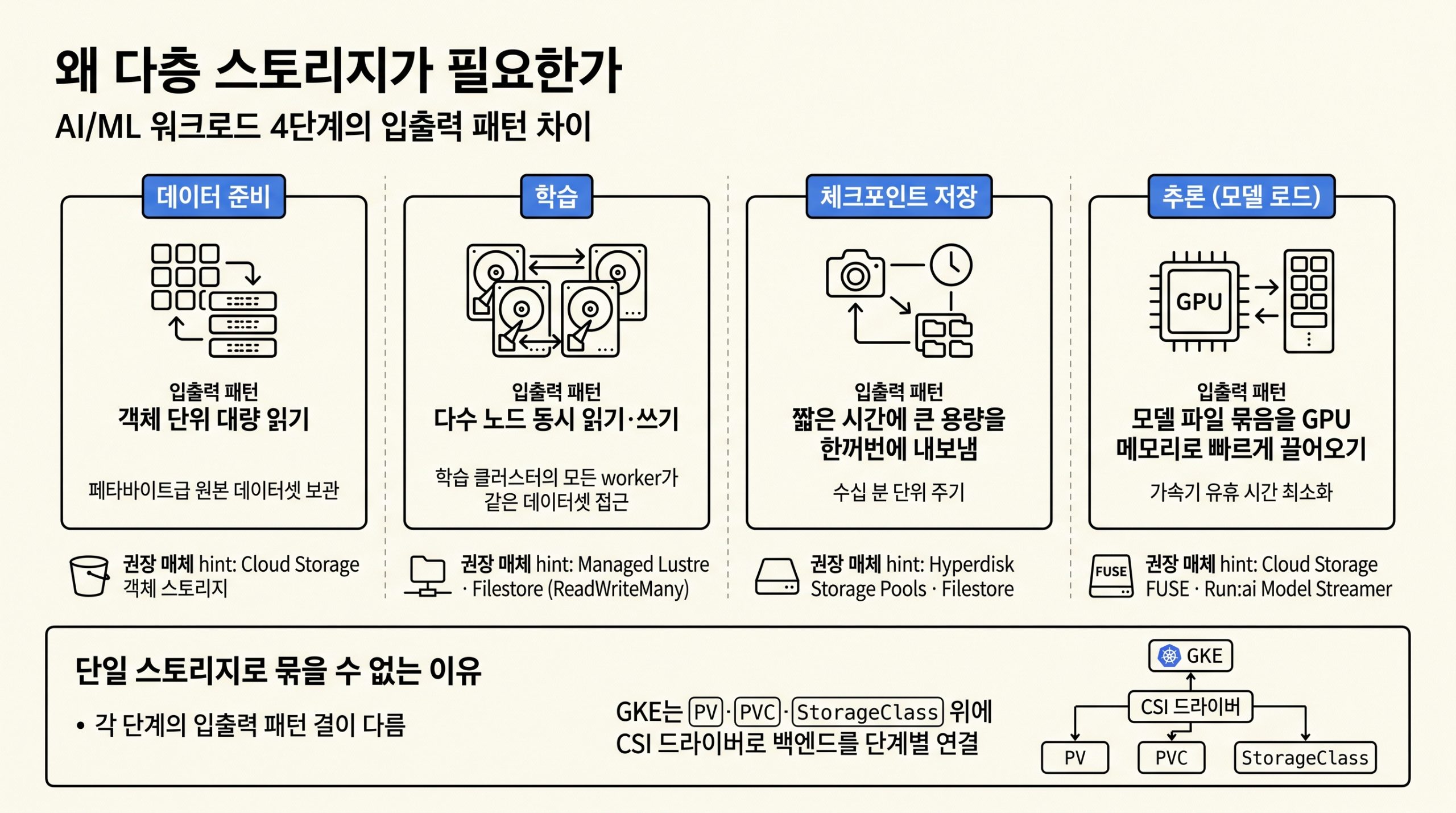
그림 1. 데이터 준비·학습·체크포인트 저장·추론 4단계의 입출력 패턴이 다르기 때문에 GKE는 단계별 매체를 PV·PVC·CSI로 연결합니다
스토리지 옵션 한눈에 보기
GKE의 스토리지 옵션은 블록·임시 블록·병렬 파일·NFS·객체 다섯 갈래로 나뉘며 각 옵션의 유형, 기본 액세스 모드, 영속성, 주된 용도는 다음 매트릭스로 정리합니다. 블록 스토리지에서도 Hyperdisk는 IOPS·처리량을 동적으로 조정하고 Hyperdisk ML은 모델 가중치 로드에 특화됩니다.
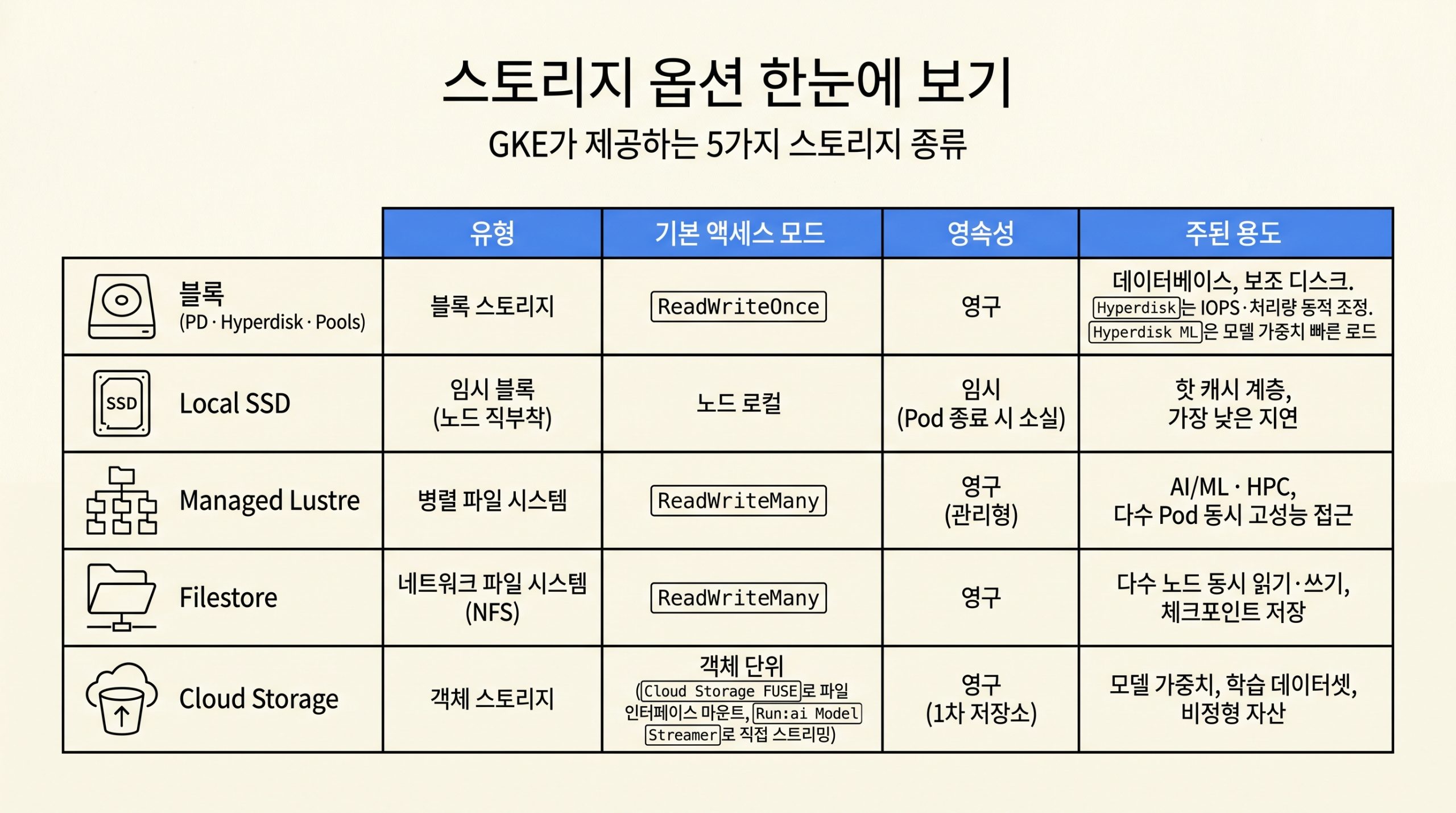
그림 2. 블록·Local SSD·Managed Lustre·Filestore·Cloud Storage 5종의 유형, 액세스 모드, 영속성, 주된 용도 비교.
워크로드 단계별 매핑
학습부터 서빙까지의 흐름을 표로 정리합니다.
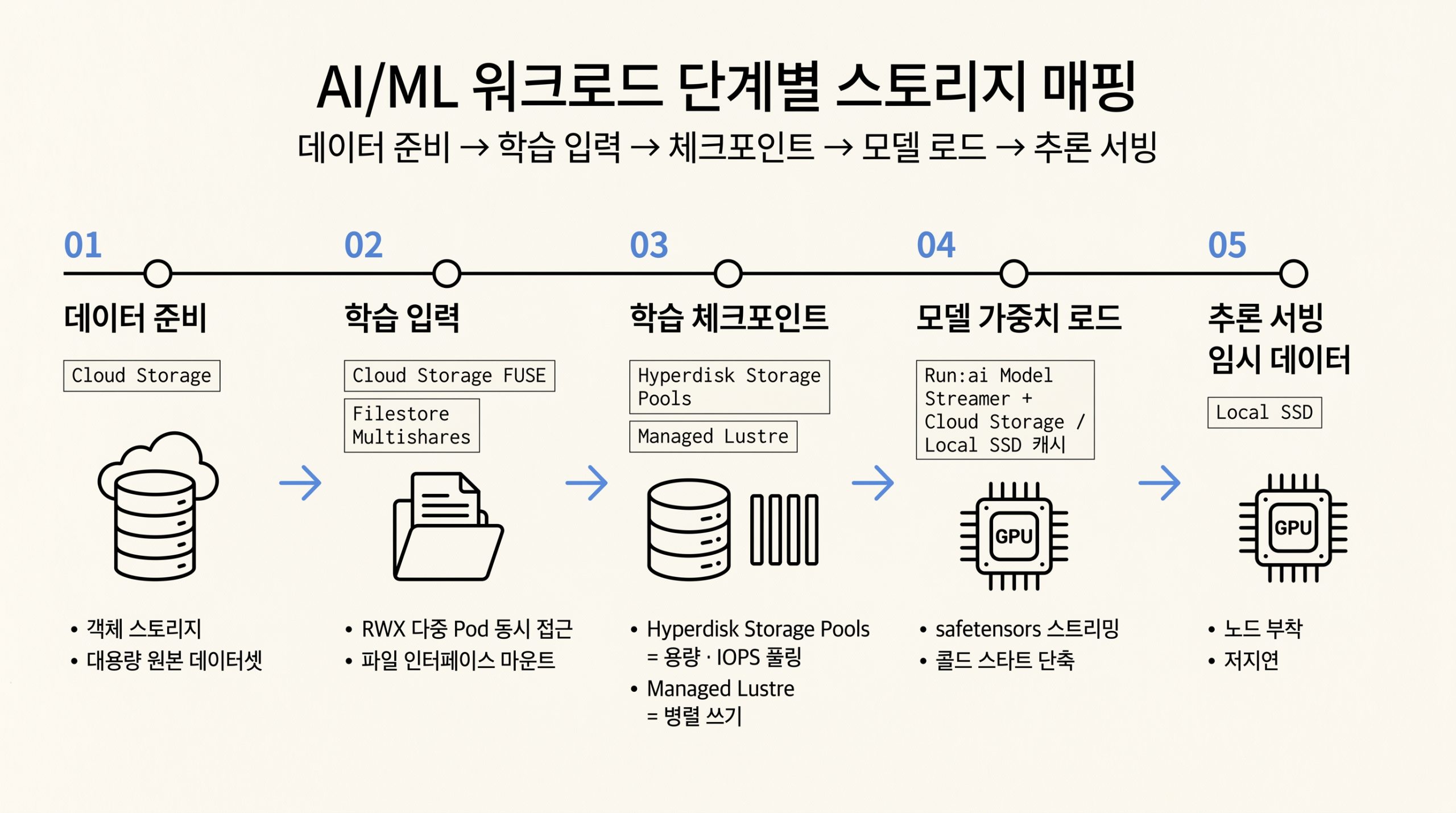
그림 3. 데이터 준비부터 추론 서빙까지 단계별 스토리지 선택
| 단계 | 추천 스토리지 | 이유 |
|---|---|---|
| 데이터 준비 | Cloud Storage(객체) | 비정형 원본 데이터셋의 1차 보관소. 학습 Pod에서는 Cloud Storage FUSE로 파일 인터페이스 마운트. |
| 학습(다수 Pod 동시 접근) | Managed Lustre 또는 Filestore | 병렬 파일 시스템과 NFS는 ReadWriteMany를 지원해 다수 학습 노드가 같은 데이터셋을 동시에 읽음. |
| 체크포인트 저장 | Hyperdisk Storage Pools(블록) 또는 Filestore | 짧은 시간에 큰 용량을 쓰는 패턴에 IOPS·처리량을 동적으로 할당. |
| 핫 캐시 계층 | Local SSD | Cloud Storage 앞단의 캐싱 레이어로 사용해 가장 낮은 지연 확보. |
| 모델 로드(서빙) | Cloud Storage FUSE 또는 Run:ai Model Streamer | 객체 스토리지의 safetensors 파일을 vLLM, SGLang 같은 추론 서버로 빠르게 스트리밍. |
각 행은 입력 자료에서 명시된 권장 사례를 그대로 옮긴 것입니다. 같은 워크로드라도 비용·성능 균형에 따라 두 옵션을 병행할 수 있습니다.
주요 구성 요소
Hyperdisk Storage Pools: 용량과 성능을 풀로 묶기
Hyperdisk Storage Pools은 용량, 처리량, IOPS를 사전 프로비저닝한 풀입니다. 여러 디스크가 그 풀을 공유하면서, 중복 제거와 thin provisioning 같은 기법으로 효율을 끌어올립니다. GKE 클러스터 부트 디스크와 attached 디스크 모두 풀에 묶을 수 있습니다.
StorageClass를 만들 때 storage-pools 매개변수에 풀 경로를 지정하고, 필요한 처리량과 IOPS를 함께 적습니다. 다음은 입력 자료에 등장하는 StorageClass 예시입니다.
💻 예시 코드
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: storage-pools-sc
provisioner: pd.csi.storage.gke.io
volumeBindingMode: WaitForFirstConsumer
allowVolumeExpansion: true
parameters:
type: hyperdisk-balanced
provisioned-throughput-on-create: “140Mi”
provisioned-iops-on-create: “3000”
storage-pools: projects/my-project/zones/us-east4-c/storagePools/pool-us-east4-c
volumeBindingMode: WaitForFirstConsumer는 PVC를 사용하는 Pod이 스케줄링되기 전까지 PV 프로비저닝을 미룹니다. PV와 Pod의 존(zone)이 어긋나면 Pod이 Pending에 머무는 문제를 막습니다. allowVolumeExpansion: true는 추후 볼륨을 확장할 수 있게 합니다.
Filestore Multishares: 한 인스턴스에 여러 PV
Filestore enterprise tier 인스턴스 한 개에 여러 PV를 얹는 것이 Multishares입니다. share 수의 한도는 CSI 드라이버 버전과 share 크기에 따라 달라집니다.

그림 4. CSI 드라이버 1.27 이상에서 share 크기에 따라 인스턴스당 80·40·20·10 share까지 둘 수 있고, 그 이전 드라이버는 10 share 고정입니다.
max-volume-size: “128Gi”를 StorageClass에 지정하면 한 10 TiB enterprise 인스턴스에 share를 80개까지 매핑합니다. GKE는 같은 multishare StorageClass를 참조하는 PV들을 같은 Filestore 인스턴스로 묶는 bin packing을 수행합니다. 입력 문서의 예시에서는 두 replica가 PVC 한 개를 공유하는 Deployment와 아홉 replica가 volumeClaimTemplates로 PVC 아홉 개를 만드는 StatefulSet이 합쳐져 100 GiB짜리 PVC 10개가 한 enterprise multishare 인스턴스에 모였습니다. 이 상태에서 PVC 한 개를 100 GiB에서 500 GiB로 확장하자 CSI 드라이버가 인스턴스 용량을 1024 GiB에서 1536 GiB로 자동 확장한 뒤 share를 키웠습니다.
Local SSD: GPU 옆 캐시 계층
Local SSD는 노드에 물리적으로 부착되는 디스크입니다. Pod의 수명에 묶인 임시 스토리지로 동작하지만, 가장 낮은 지연을 제공합니다. 핫 데이터베이스 캐시, 실시간 분석, AI/ML과 배치 처리에서 Cloud Storage 앞단의 캐싱 계층으로 자주 쓰입니다.
–ephemeral-storage-local-ssd count=NUMBER_OF_DISKS 옵션으로 노드에 Local SSD를 부착하고, Pod은 emptyDir 볼륨으로 그 공간을 사용합니다. C3 같은 3·4세대 머신 시리즈는 별도 옵션 없이 머신 타입에 따라 Local SSD가 자동으로 부착됩니다.
Managed Lustre: 병렬 파일 시스템 인터페이스
Managed Lustre는 GKE에 Managed Lustre CSI 드라이버로 통합되는 완전 관리형 병렬 파일 시스템입니다. PV와 PVC라는 표준 쿠버네티스 객체로 인스턴스를 프로비저닝하고, 학습 도중 볼륨을 동적으로 확장할 수 있습니다. AI/ML과 HPC 워크로드에서 다수 Pod이 동시에 고처리량·저지연으로 접근해야 할 때 적합합니다.
고객이 키를 직접 관리하려면 고객 관리 암호화 키(CMEK)를 사용합니다. 단, GKE에서 CMEK로 보호되는 Managed Lustre 인스턴스의 동적 프로비저닝은 지원되지 않으며, 정적 프로비저닝만 가능합니다. CMEK 키는 Managed Lustre 인스턴스와 같은 리전에 있어야 합니다.
Cloud Storage FUSE와 Run:ai Model Streamer
Cloud Storage FUSE CSI 드라이버는 Cloud Storage 버킷을 GKE 노드의 파일 시스템으로 마운트합니다. ReadWriteMany, ReadOnlyMany, ReadWriteOnce를 모두 지원합니다. 모델 학습 데이터와 가중치를 객체 형태로 보관하고, Pod에서는 파일 인터페이스로 접근하는 패턴이 일반적입니다.
Run:ai Model Streamer는 객체 스토리지의 모델 가중치를 GPU 메모리로 직접 스트리밍하는 Python SDK입니다. 고성능 C++ 구현이 모델 텐서를 동시에 읽어 들여 추론 엔진의 콜드 스타트 시간을 줄입니다. vLLM 같은 추론 서버와 통합되어 Cloud Storage에 저장된 safetensors 파일을 스트리밍 방식으로 로드합니다.
동작 흐름: 객체에서 GPU까지
데이터 준비 시점에는 원본 데이터를 Cloud Storage 버킷에 모읍니다. Cloud Storage FUSE CSI 드라이버는 이 버킷을 GKE 노드의 파일 시스템으로 마운트해 ReadWriteMany, ReadOnlyMany, ReadWriteOnce 액세스를 제공합니다. NFS 의존 워크로드는 Filestore enterprise 인스턴스를 PV로 붙여 다수 노드가 동시에 읽고 쓰는 환경을 구성합니다. 큰 데이터셋을 Cloud Storage에서 Filestore file share로 옮길 때는 Storage Transfer Service를 사용해 객체 스토리지의 데이터를 파일 스토리지로 이동시킵니다.
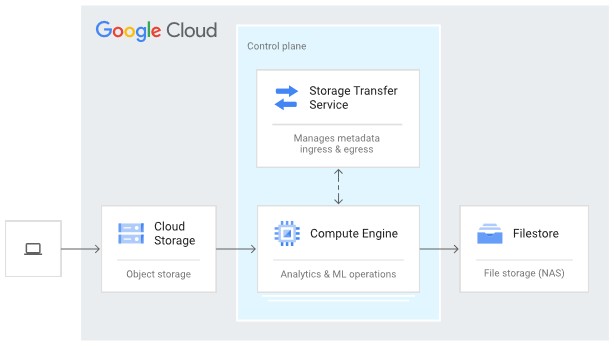
그림 5. Cloud Storage에서 Filestore로 데이터를 옮기는 Storage Transfer Service 흐름
학습 단계에서는 다수 노드가 같은 데이터셋을 동시에 읽어야 하므로 Managed Lustre의 ReadWriteMany 마운트 또는 Filestore Multishares의 enterprise 인스턴스를 사용합니다. 체크포인트는 Hyperdisk Storage Pools에 묶인 attached 디스크 또는 Filestore 위로 떨어집니다.
학습이 끝나 모델을 서빙으로 넘기는 단계에서는 Cloud Storage에 있는 safetensors 파일을 Run:ai Model Streamer가 GPU 메모리로 끌어올리거나, Cloud Storage FUSE로 파일 시스템처럼 마운트해 추론 엔진이 읽습니다. 이 단계에서 GPU/TPU 유휴 시간을 줄이는 또 다른 선택지가 Hyperdisk ML로, 모델 가중치를 빠르게 로드하도록 최적화된 블록 옵션입니다.
적용 시나리오
대규모 학습 클러스터에서 자주 보이는 조합은 다음과 같습니다.
- 데이터셋은 Cloud Storage에 두고, Cloud Storage FUSE로 학습 Pod에 마운트.
- 작은 학습 작업이나 NFS 의존 워크로드는 Filestore enterprise multishare 인스턴스 하나에 PVC를 묶어 비용을 절감.
- 멀티 노드 분산 학습에서는 Managed Lustre로 처리량을 끌어올리고, 학습 도중 볼륨을 확장해 데이터 증가에 대응.
- 체크포인트 디스크는 Hyperdisk Storage Pools에 묶어 IOPS·처리량을 풀 단위로 관리.
- 추론 단계에서는 Cloud Storage에 둔 safetensors를 Run:ai Model Streamer가 vLLM 컨테이너로 스트리밍.
CMEK 요구가 있는 환경에서는 Filestore Multishares StorageClass의 instance-encryption-kms-key 매개변수에 KMS 키를 지정합니다. Managed Lustre의 경우 CMEK는 정적 프로비저닝에서만 지원된다는 점을 미리 검토합니다.
도입을 검토할 때 짚어야 할 점
도입 평가는 액세스 모드, 영속성, 존(zone) 일치, Multishares 한도, CMEK 제약 다섯 단계로 정리됩니다.
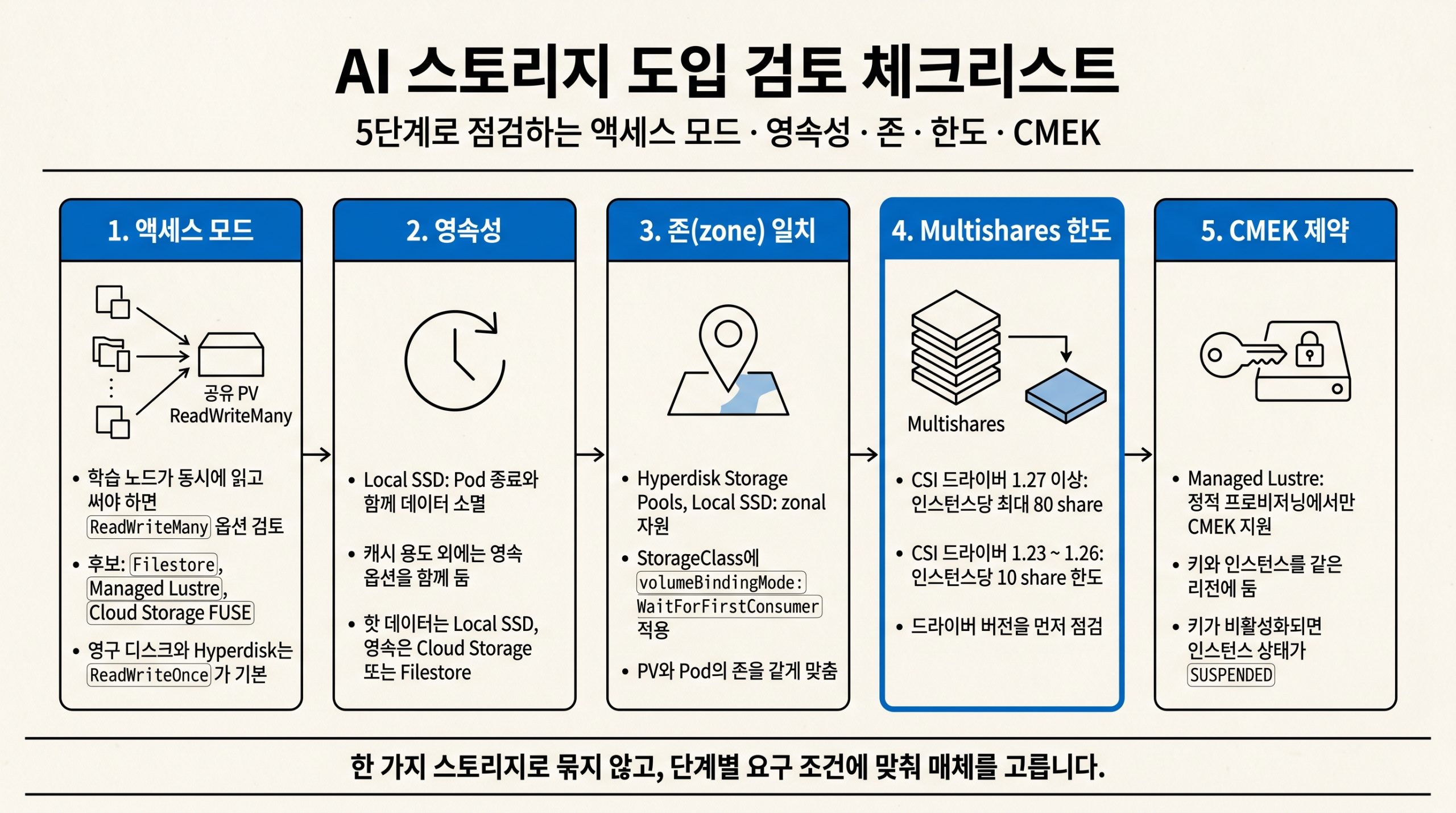
그림 6. 액세스 모드·영속성·존 일치·Multishares 한도·CMEK 제약 다섯 단계로 정리한 도입 검토 체크리스트.
본 시리즈와의 연결
AI 스토리지 다층 전략은 본 시리즈의 다른 글들과 다음과 같이 이어집니다.
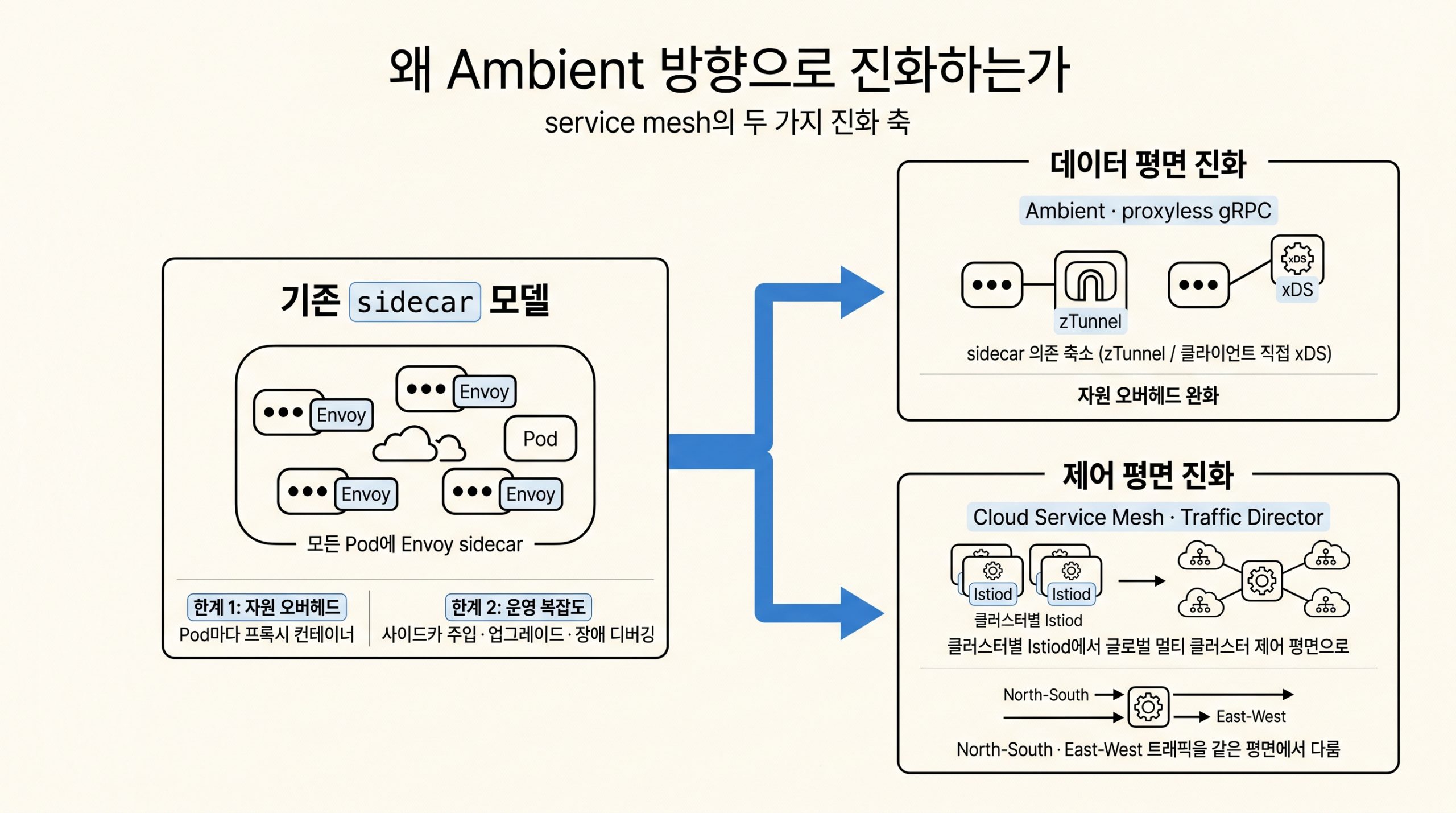
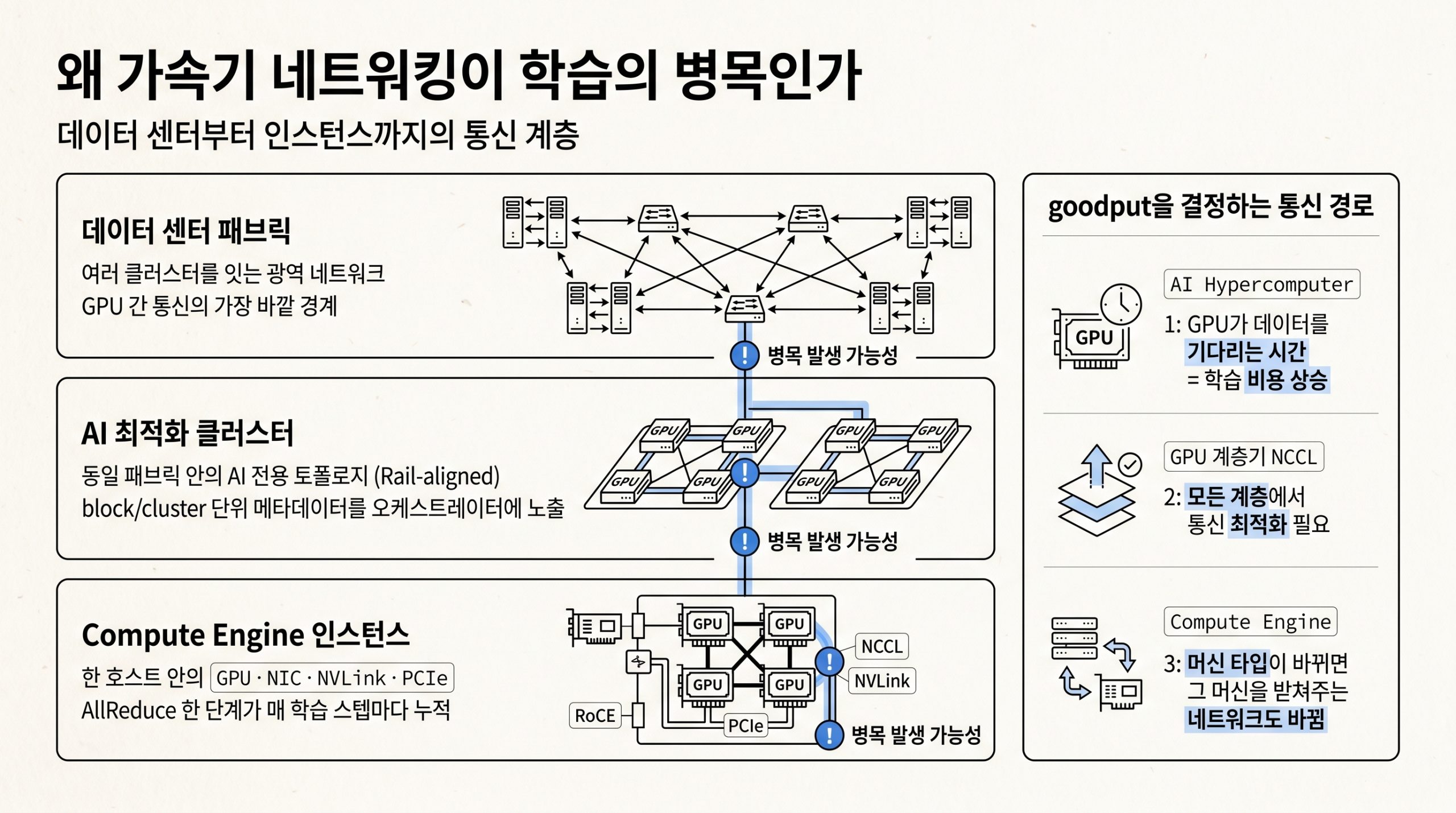
- 본 시리즈 5편에서 다루는 가속기 네트워킹은 학습 노드 사이의 통신을 NCCL과 RDMA로 최적화합니다. 그 위에서 6편의 Managed Lustre·Filestore가 노드 간 데이터 공유 경로를 제공합니다.
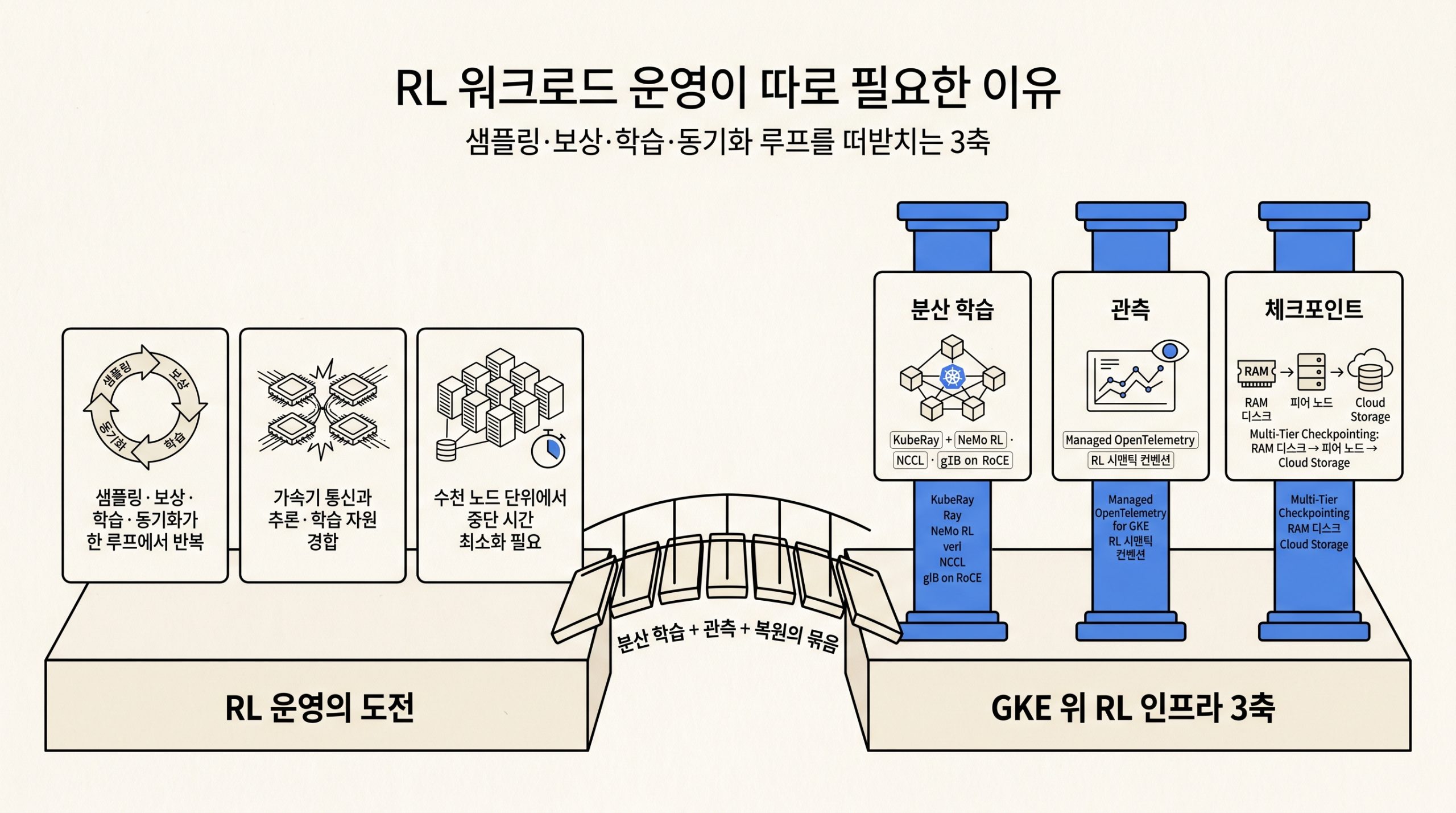
- 본 시리즈 7편의 강화학습 워크로드는 학습 데이터셋과 체크포인트를 빠르게 회전시키는 환경이 전제입니다. Hyperdisk Storage Pools와 Local SSD가 그 회전 속도를 받칩니다.
- 본 시리즈 3편의 KV 캐시 티어링은 추론 시점의 메모리 계층화입니다. 6편의 Cloud Storage FUSE와 Run:ai Model Streamer가 그 위 계층, 즉 모델 가중치 로드 단계를 책임집니다.
참고 자료
- Google Cloud, “AI infrastructure at Next 26”, https://cloud.google.com/blog/ko/products/compute/ai-infrastructure-at-next26/
- Google Cloud, “Google Cloud Next 2026 wrap-up”, https://cloud.google.com/blog/topics/google-cloud-next/google-cloud-next-2026-wrap-up
- Google Cloud Documentation, “GKE cluster storage overview”, https://docs.cloud.google.com/kubernetes-engine/docs/concepts/storage-overview
- Google Cloud Documentation, “GKE persistent volumes & provisioning”, https://docs.cloud.google.com/kubernetes-engine/docs/concepts/persistent-volumes
- Google Cloud Documentation, “Optimize storage performance and cost with Hyperdisk Storage Pools”, https://docs.cloud.google.com/kubernetes-engine/docs/how-to/persistent-volumes/hyperdisk-storage-pools
- Google Cloud Documentation, “About Filestore support for Google Kubernetes Engine”, https://docs.cloud.google.com/filestore/docs/filestore-for-gke
- Google Cloud Documentation, “Optimize storage with Filestore Multishares for GKE”, https://docs.cloud.google.com/filestore/docs/optimize-multishares
- Google Cloud Documentation, “Transfer data from Cloud Storage”, https://docs.cloud.google.com/filestore/docs/transfer-data-from-gcs
- Google Cloud Documentation, “Provision and use Local SSD-backed ephemeral storage”, https://docs.cloud.google.com/kubernetes-engine/docs/how-to/persistent-volumes/local-ssd
- Google Cloud Documentation, “Customer-managed encryption keys for Managed Lustre”, https://docs.cloud.google.com/managed-lustre/docs/cmek
자세한 내용이 궁금하시다면, 메가존소프트 문의포탈을 통해 궁금한 부분을 남겨주세요.