올해 Google Cloud Next 2026 행사에서 구글은 기업의 데이터 활용 방식을 근본적으로 바꿀 새로운 패러다임, ‘Agentic Data Cloud’를 발표했습니다.
이는 단순히 데이터를 저장하고 분석하는 기존의 시스템을 넘어, AI 에이전트가 스스로 데이터를 인지하고, 추론하며, 행동하는 ‘실행 시스템(System of Action)’으로의 전환을 의미합니다.
본 블로그에서는 Google Next에서 공개된 Agentic Data Cloud의 핵심 비전, 구성 요소, 기반 기술, 실제 활용 사례 및 도입 시의 제약 사항까지 심층적으로 분석하여 제공합니다.
1탄. Google Agentic Data Cloud가 여는 데이터 생태계 혁명
Agentic Data Cloud의 비전: 정적 저장소에서 동적 추론 엔진으로
기존의 데이터 플랫폼이 인간의 분석을 돕기 위한 ‘지능형 시스템(Systems of Intelligence)’이었다면, Agentic Data Cloud는 AI 에이전트가 스스로 판단하고 움직이도록 설계된 ‘실행 시스템(System of Action)’입니다. 이는 기업의 데이터 플랫폼을 정적인 데이터 저장소에서 동적인 추론 엔진으로 진화시키는 AI 네이티브 아키텍처를 기반으로 하기 때문입니다. 구글은 이를 통해 AI 에이전트가 비즈니스 데이터와 맥락을 이해하고 직접 행동하며 ‘생각’과 ‘실행’ 사이의 간극을 좁힐 수 있다고 강조하고 있습니다.
AI 에이전트 주도의 데이터 생태계 전환과 구글의 해답
이제 데이터 인프라의 핵심 활용 주체는 사람이 아닌 ‘AI 에이전트’로 이동하고 있습니다. 그러나 기존의 레거시 스택 위에서 AI 에이전트를 확장할 경우 거버넌스 파편화, 신뢰성 격차, 추론 루프 단절, 그리고 통제 불가능한 비용 증가라는 심각한 구조적 리스크에 직면하게 됩니다.
구글의 Agentic Data Cloud는 이러한 한계를 극복하고, 기업이 안심하고 AI를 확장할 수 있는 단일화된 엔터프라이즈급 데이터 기반을 제공하는 것을 최우선 목표로 합니다.
숫자로 입증된 구글 기술의 압도적 성과와 신뢰성
이 거대한 기술적 도약은 이미 다음과 같은 압도적인 성장 지표로 입증되고 있습니다.

구글은 파편화된 데이터를 통합하고 AI 추론의 신뢰성을 보장함으로써, 귀사의 데이터 인프라가 미래 지향적인 ‘AI-First’ 아키텍처로 도약할 수 있도록 강력하게 지원합니다.
Agentic Data Cloud의 핵심 구성 요소
Agentic Data Cloud는 세 가지 핵심적인 혁신을 통해 구현됩니다.
1. Knowledge Catalog : Universal Context Engine
Knowledge Catalog는 기존 Dataplex가 진화한 형태로, AI 에이전트가 기업의 데이터를 정확히 이해하고 Hallucination 없이 작업을 수행하도록 돕는 ‘Universal Context Engine’입니다. 이는 정적인 메타데이터 목록을 넘어 동적인 ‘컨텍스트 그래프(Context Graph)’를 구축하며, 집계(Aggregation), 강화(Enrichment), 검색(Search)이라는 세 가지 원리로 작동합니다.
- 집계(Aggregation) 아키텍처: 기업 내외부에 흩어진 모든 데이터의 컨텍스트를 통합합니다.
- 네이티브 컨텍스트 집계: 구글 레이크하우스를 허브로 삼아 SAP, Salesforce, Palantir 등의 외부 데이터 자산은 물론 Atlan, Collibra와 같은 기존 카탈로그 메타데이터까지 단일 환경으로 완벽히 통합합니다.
- 시맨틱 모델 통합: LookML 에이전트가 비정형 전략 문서를 분석해 비즈니스 시맨틱을 자동 생성합니다. 이를 통해 AI 에이전트는 인간 분석가와 완전히 동일한 비즈니스 규칙과 정의를 기반으로 추론할 수 있습니다.
- 지속적인 강화(Continuous Enrichment) 메커니즘: 데이터를 지속적으로 학습하고 의미를 부여하여 컨텍스트를 풍부하게 만듭니다.
- Smart Storage: Google Cloud Storage(GCS)에 내장된 기능으로, 이미지나 PDF 같은 비정형 파일이 저장되는 즉시 자동으로 메타데이터를 태깅하고 임베딩을 생성하여 강화합니다. 이를 통해 이전에는 활용이 어려웠던 ‘다크 데이터’를 AI 에이전트가 즉시 발견하고 사용할 수 있게 되었습니다.
- Gemini 기반 심층 분석: Gemini 모델이 조직의 사용 로그, 쿼리 패턴, BI 시맨틱 모델 등을 분석하여 데이터 간의 숨겨진 관계를 추론하고, 누락된 스키마나 데이터셋에 대한 자연어 설명, 비즈니스 용어집을 자동으로 생성합니다.
- 제로 트러스트 기반의 액세스 제어 인식 검색(Access Control-Aware Search): 에이전트가 승인된 데이터에만 접근하고 행동하도록 보장합니다.
- 에이전트에 Google 검색 기술과 Google Cloud의 IAM(Identity and Access Management)이 결합되어 하이브리드 검색 스택을 제공합니다. 검색 시 소스 시스템에 정의된 메타데이터 접근 권한을 그대로 승계하여, 에이전트는 명시적으로 승인된 자산만 검색 결과로 받을 수 있습니다. 이를 통해 데이터 보안을 유지하고 에이전트의 신뢰도를 일 수 있는 제로 트러스트 거버넌스가 구현됩니다.
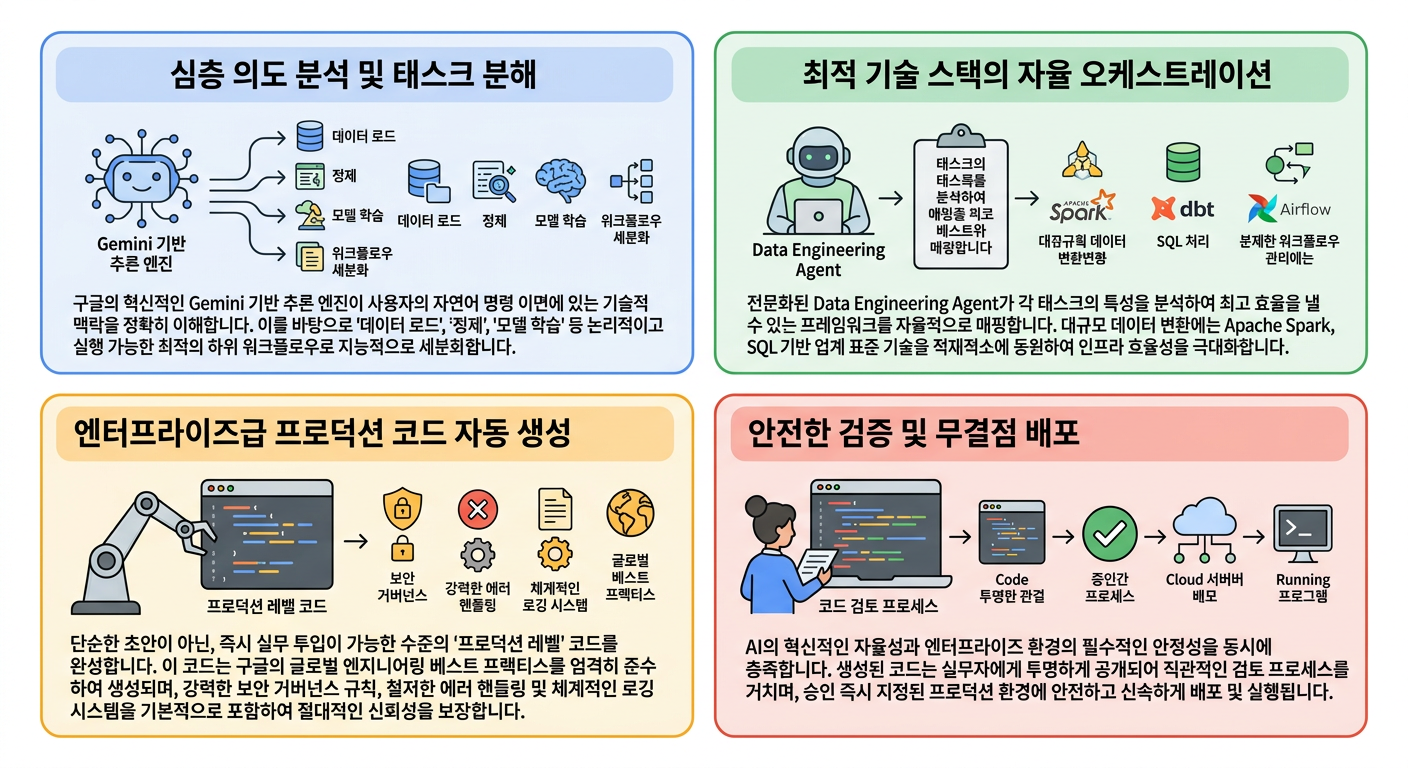
2. Data Agent Kit : 에이전트 우선의 실무자 경험
Data Agent Kit는 데이터 전문가의 역할을 단순하고 반복적인 파이프라인 구축자에서, 비즈니스 가치를 창출하는 ‘의도 중심 엔지니어링(Intent-driven Engineering)’의 전략적 조율자로 격상시킵니다. VS Code, Gemini CLI 등 개발자가 이미 친숙한 IDE 환경에 심리스(Seamless)하게 통합되어, 구글의 강력한 엔터프라이즈급 AI 역량을 실무자의 손끝에서 즉각적으로 구현합니다.
- 핵심 아키텍처 및 작동 메커니즘: 자연어가 곧 엔터프라이즈 솔루션이 되는 과정: 개발자가 비즈니스 목표를 자연어로 제시하면, 시스템이 최적의 실행 경로를 자율적으로 설계하고 완벽하게 수행합니다.
 3. AI 네이티브 멀티 클라우드 레이크하우스: BigQuery를 통한 데이터 사일로 해소
3. AI 네이티브 멀티 클라우드 레이크하우스: BigQuery를 통한 데이터 사일로 해소
성공적인 AI 에이전트의 자율성은 ‘데이터가 어디에 있든 제약 없이 접근할 수 있는 개방형 파운데이션’에서 비롯됩니다. 구글 클라우드의 BigQuery는 독보적인 Cross-Cloud Lakehouse 비전을 통해 데이터의 물리적 위치와 플랫폼의 경계를 완전히 허무는 ‘초연결 데이터 기반’을 기업에 제공합니다.
- 관리형 Iceberg 테이블 (Managed Iceberg Tables): 개방성과 통제의 완벽한 결합
- 기술 원리: Apache Iceberg는 다양한 엔진 간 상호 운용성을 보장하는 개방형 테이블 형식입니다. BigQuery의 이 기능은 고객 소유의 클라우드 스토리지에 데이터를 Iceberg 포맷으로 저장하면서도, BigQuery의 완전 관리형 기능을 그대로 사용할 수 있게 합니다.
- 에이전틱 시대 가속화: 데이터 이동 없이 단일 데이터 소스를 기반으로 다양한 AI 에이전트와 분석 도구가 동시에 작업을 수행할 수 있습니다. 자동 테이블 관리와 같은 BigQuery의 고급 기능이 Iceberg 테이블에 적용되어 AI 에이전트가 항상 최신 데이터에 기반한 신뢰도 높은 추론을 수행하도록 돕습니다.
- 멀티 클라우드 분석 (BigQuery Omni): 벤더 종속성 없는 데이터 자산의 통합
- 기술 원리: AWS, Azure 등 다른 클라우드에 저장된 데이터를 이전하지 않고도 직접 쿼리하고 분석할 수 있습니다. 이는 Iceberg와 같은 개방형 표준과 Cross-Cloud Interconnect 같은 고대역폭 네트워크를 통해 가능하며, 투명한 캐싱 기술로 네이티브 웨어하우스와 대등한 성능을 구현합니다.
- 에이전틱 시대 가속화: AI 에이전트가 벤더 종속이나 데이터 이동 비용 문제 없이 조직의 전체 데이터 자산을 탐색하고 분석하여 더 포괄적이고 정확한 인사이트를 도출할 수 있게 합니다.
자세한 내용이 궁금하시다면, 메가존소프트 문의포탈을 통해 궁금한 부분을 남겨주세요.