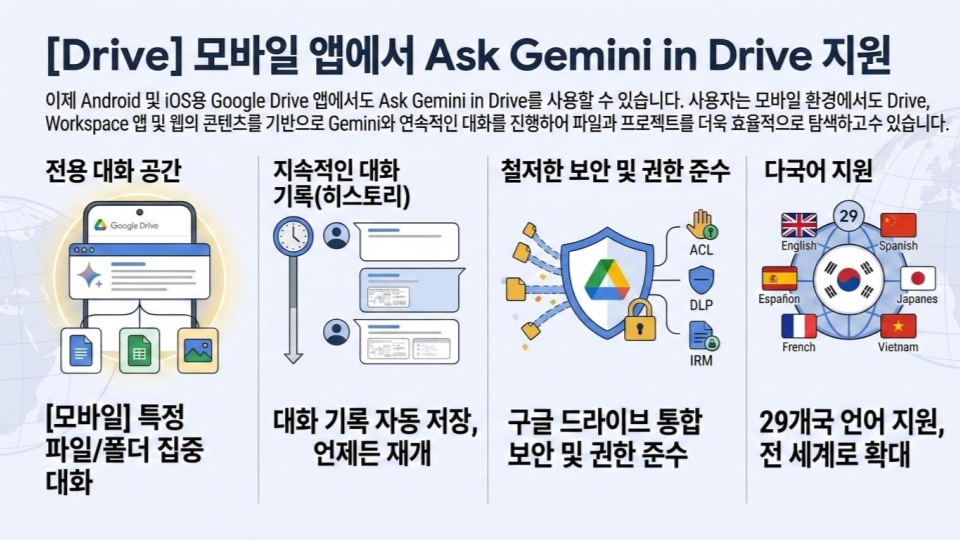
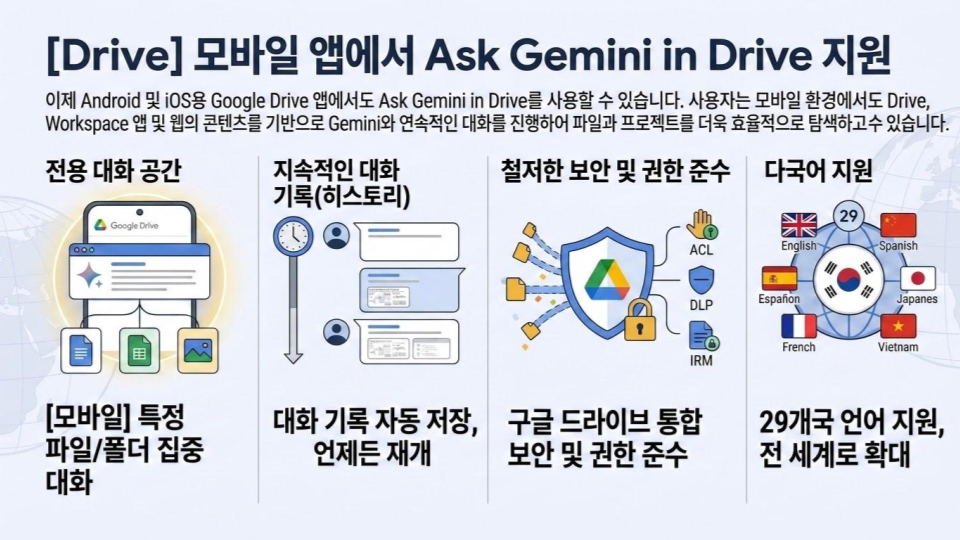
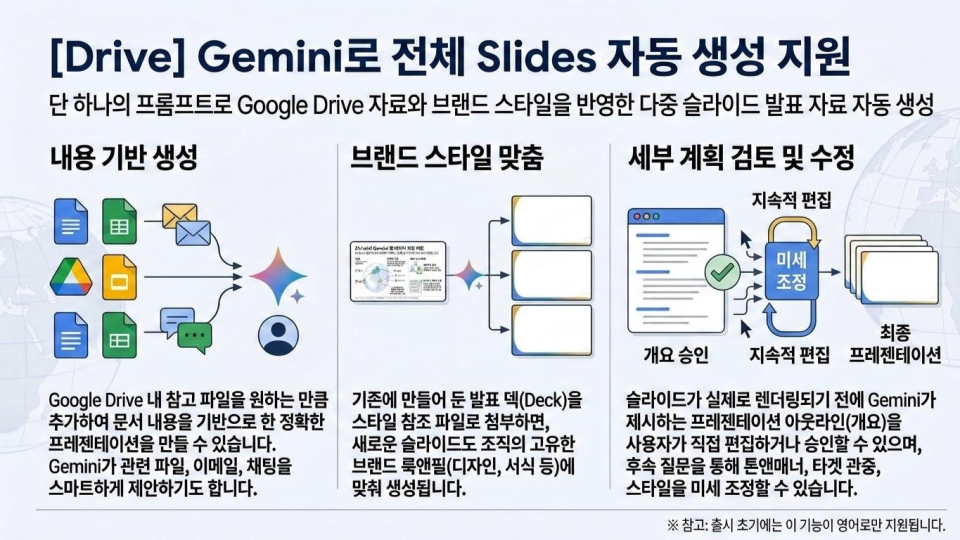
데이터 레이크의 가치가 나날이 높아지고 있습니다. AI가 모든 IT 프로젝트에 포함되는 주제가 되다 보니 데이터 레이크 역시 따라서 몸값이 뛰는 것이 아닐까요. 이처럼 중요한 데이터 레이크가 제 기능을 못한다면? 고민이 클 것입니다. 실제로 데이터가 어디에 있는지, 무엇을 의미하는지 파악할 수 없는 이른바 데이터 늪(Data Swamp) 문제로 데이터 레이크가 제 역할을 못하는 경우도 적지 않습니다. 데이터 늪은 데이터의 양이 늘어날수록 이 늪은 깊어 진다는 데에 문제의 심각성이 있습니다. 관련해 이번 포스팅에서는 Dataplex를 활용해 데이터 늪에서 탈출하는 방법을 공유해까 합니다.
태깅의 역설
많은 조직이 데이터 늪에서 탈출하기 위해 가장 직관적인 방법인 태깅(Tagging)을 시도합니다. 데이터에 꼬리표를 붙여 식별하겠다는 것입니다. 하지만 명확한 규칙 없이 사람이 직접 입력하는) 방식은 시간이 지날수록 혼란만 키웁니다. 이를 일반적으로 태깅의 역설(The Tagging Paradox)이라고 부릅니다.
흔히 발생할 수 있는 상황을 예로 들어보겠습니다. 어떤 데이터의 소유자를 표시하기 위해 누군가 Owner: Bob이라는 태그를 붙였습니다. 6개월 후 Bob이 퇴사하자 후임자는 Contact: Alice라는 새로운 태그를 만듭니다. 또 다른 부서에서는 민감 정보를 PII: True로 표시하는데, 누군가는 Sensitive: Yes라고 적거나 소문자로 pii라고 입력합니다. 이렇게 제각각인 표기법이 난무하면 정확한 검색이 불가능합니다. 결국 데이터 카탈로그는 누구도 믿지 않는 의미 없는 존재로 전락하고 맙니다.
수작업도 태킹의 역설을 맞이하게 하는 중요 요인입니다. 수작업 방식은 사람의 실수로부터 자유롭지 않을 뿐만 아니라 비용도 많이 듭니다. 수만 건의 데이터셋에 일일이 라벨을 붙이려면 수백 시간 인력을 투입해야 합니다. 게다가 데이터가 변경될 때마다 태그를 일일이 업데이트하는 것은 사실상 불가능에 가깝습니다. 결국 카탈로그 정보와 실제 데이터가 서로 다른 상태가 되어 데이터의 신뢰도는 바닥으로 떨어집니다.
메타 데이터 엔지니어링
태킹의 역설 문제를 해결하는 열쇠는 메타 데이터를 단순한 주석이 아닌 코드(Code)처럼 엄격하게 다루는 것입니다. 개발자가 데이터베이스를 만들 때 스키마를 먼저 정의하듯이 메타 데이터 관리에도 강력한 규칙과 타입 시스템이 필요합니다.
Dataplex를 활용하면 자연스럽게 메타 데이터를 코드처럼 다룰 수 있습니다. Dataplex는 애스펙트 타입(Aspect Type)이라는 기능을 통해 지원합니다. 이는 프로그래밍에서 말하는 클래스나 설계도와 비슷합니다. 예를 들어 데이터 거버넌스라는 애스펙트 타입을 만들 때 민감도 항목은 Public, Internal, Confidential 셋 중 하나만 선택하도록 강제할 수 있습니다. 사용자가 임의로 Secret이나 Important 같은 엉뚱한 값을 입력하는 것을 시스템 차원에서 원천 차단하여 데이터의 일관성을 유지할 수 있습니다. 기존의 태그 템플릿과 Dataplex의 애스펙트 타입은 명확한 차이가 있습니다.
- 기존 태그 템플릿: 단순한 키-값(Key-Value) 쌍으로 이루어져 있으며 텍스트 위주의 모호한 검색만 가능합니다. 관리 또한 지역(Region) 단위로 쪼개져 있어 전사적 관리가 어렵습니다.
- Dataplex 애스펙트 타입: 복잡한 데이터 구조를 지원하며 엄격한 제약 조건을 걸 수 있습니다. 구조화된 쿼리를 통해 정밀한 필터링이 가능하고 전역(Global) 리소스로 통합 관리됩니다.
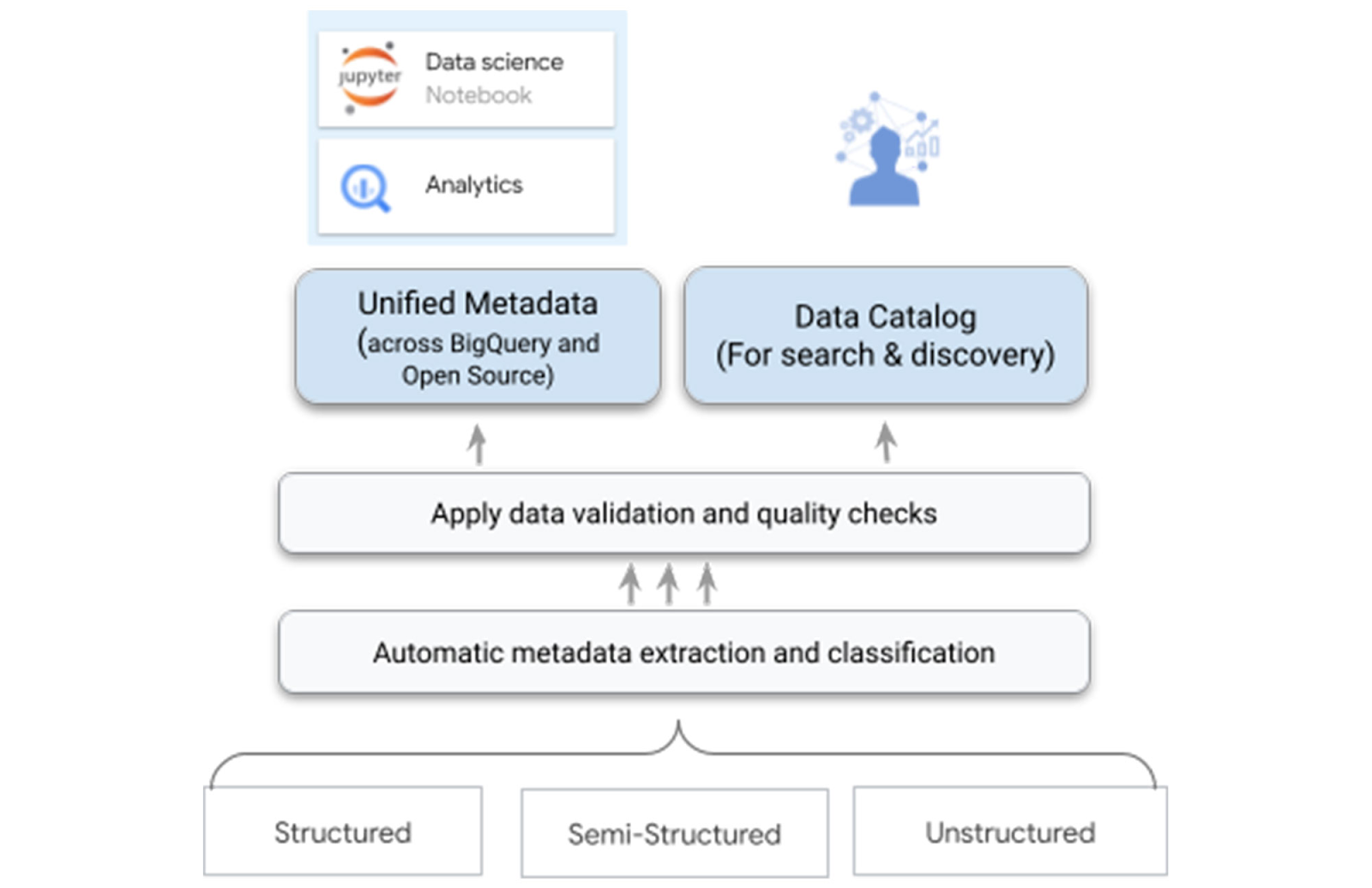
지능형 패브릭 기반 데이터 카탈로그
태킹의 늪에서 벗어나는 가장 확실한 방법은 사람이 태킹을 하지 않게 하는 것입니다. Dataplex는 데이터를 물리적으로 이동시키지 않고도 논리적으로 통합 관리하는 지능형 데이터 패브릭 환경을 제공합니다. 이는 메타 데이터 생성과 관리를 자동화할 수 있고 데이터가 어디에 있든 중앙에서 관리할 수 있다는 뜻입니다.
Dataplex의 AutoDQ 기능은 데이터 품질 관리를 코드로 정의하고(Quality as Code) 이를 자동화된 스캔 작업으로 실행합니다. 스캔 결과는 별도의 로그 파일로 남는 것이 아니라 카탈로그의 시스템 애스팩트로 자동 등록됩니다.
데이터 늪 문제가 있는 환경에서는 데이터의 기원을 알기 어렵습니다. Dataplex는 통합 카탈로그와 계보(Lineage) 추적을 지원합니다. BigQuery나 Vertex AI 등 여러 곳에 흩어진 메타데이터를 자동으로 수집하고, 데이터가 어디서 생성되어 어떤 AI 모델로 흘러갔는지 그 경로를 투명하게 보여줍니다.
비즈니스 용어집(Business Glossary)도 제공합니다. 개발자가 쓰는 용어와 현업 부서가 쓰는 용어가 달라 생기는 소통 오류를 막기 위해 비즈니스 용어를 정의하고 이를 실제 데이터 컬럼과 연결해 줍니다. 이외에도 Dataplex는 별도의 서버 구축 없이도 데이터 품질을 지속적으로 감시하며, AI가 데이터 특성에 맞는 품질 규칙을 자동으로 제안해 관리 부담을 줄여줍니다.
거버넌스의 코드화
거버넌스 정책을 지속 가능하게 확장하려면 모든 정책을 코드로 관리해야 합니다. 이를 거버넌스 코드화(Governance as Code)라고 합니다. Dataplex는 인프라를 코드로 관리하는 도구인 테라폼(Terraform)과 완벽하게 연동됩니다.
이를 통해 메타 데이터 정책의 변경 이력을 마치 소프트웨어 버전 관리하듯 추적할 수 있습니다. 예를 들어 google_dataplex_aspect_type이라는 코드를 사용해 필수 보안 태그 정책을 정의하면 개발 환경이든 운영 환경이든 관계없이 동일한 보안 정책이 자동으로 적용됩니다. 사람의 개입을 최소화하여 정책 준수율을 100%로 유지하는 것입니다.
잘 관리된 데이터 카탈로그는 생성형 AI의 성공을 위한 필수 전제 조건입니다. 특히 AI가 거짓 정보를 사실인 양 말하는 환각(Hallucination) 현상을 줄이는 데 기여합니다.
- 그라운딩(Grounding) 소스: AI는 Dataplex의 잘 정리된 메타 데이터를 참조하여 사용자의 질문 의도를 파악합니다. 또한, 인증된(Certified) 마크가 붙은 신뢰할 수 있는 데이터만을 근거로 답변을 생성하게 하여 정확도를 높입니다.
- 시맨틱 검색(Semantic Search): 사용자가 “지난달 지역별 매출 데이터 보여줘”라고 자연어로 물어봐도 AI가 문맥을 이해하여 정확한 테이블 이름이나 컬럼을 몰라도 관련 데이터를 찾아줍니다.
데이터의 자산 가치 높이기
정리하자면 데이터 태깅, 카탈로그, 거버넌스는 별개의 활동이 아니라 서로 맞물려 돌아가는 순환 구조입니다. 구조화된 애스펙트를 통해 데이터에 명확한 맥락을 부여하고(태깅), 이를 하나로 모아 전방위적인 시야를 확보하며(카탈로그), 축적된 정보를 바탕으로 정책을 자동화하여 통제하는 것(거버넌스), 이 세 박자가 맞아야 합니다. Dataplex를 활용하면 데이터를 단순히 저장하는 단계를 넘어, 엔지니어링 된 메타 데이터를 통해 데이터를 ‘설명 가능하고’, ‘신뢰할 수 있으며’, ‘기계가 이해할 수 있는’ 자산으로 바꿀 수 있습니다. 이것이 DX, AX 시대가 요구하는 진정한 데이터 거버넌스가 아닐까요?