
BigQuery with the TimesFM foundation model
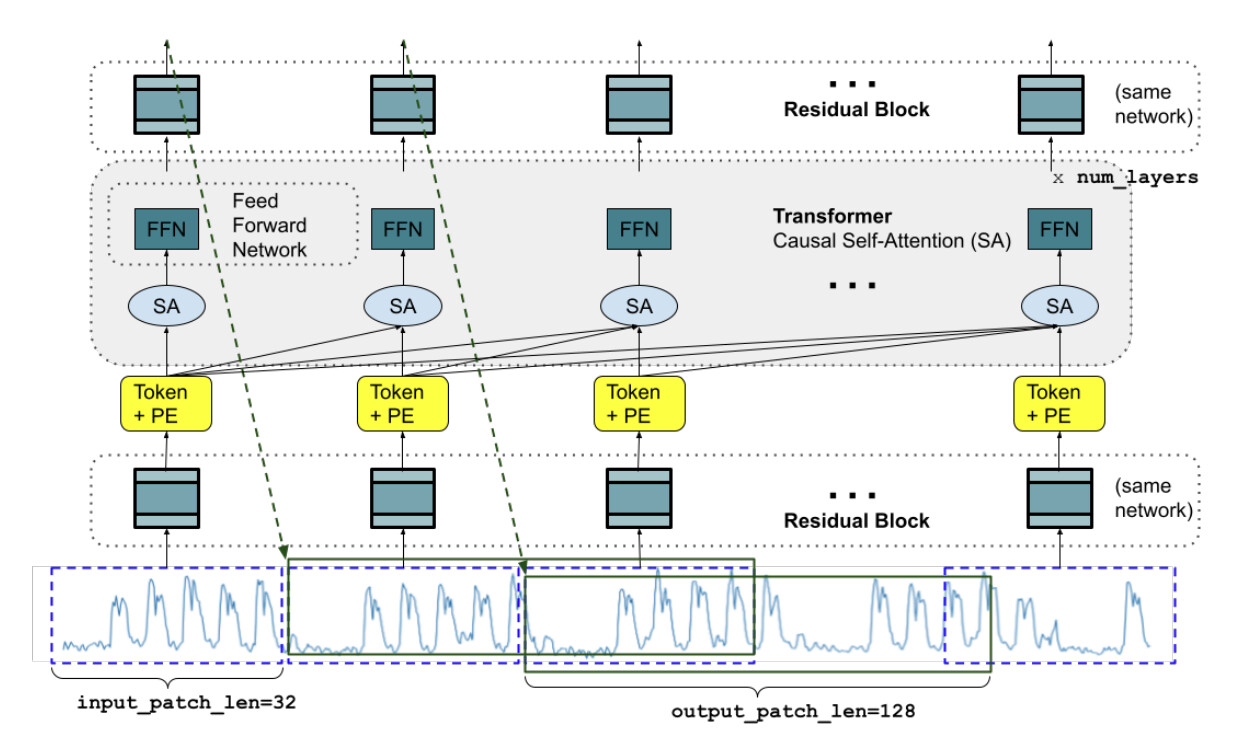
Google Research에서 개발한 최신 시계열 예측 모델인 TimeFM은 4,000억 개에 달하는 방대한 실제 시점 데이터셋을 기반으로 사전 학습된 파운데이션 모델
주요 특징
- 제로샷(Zero-shot) 예측 : 학습되지 않은 데이터셋에서도 추가적인 훈련 없이 정확한 예측 수행
- BigQuery ML 통합 : BigQuery의 기본 ML 모델로, 5억 개의 매개변수를 가지고 있으며 BigQuery 인프라에서 직접 모델 추론이 실행되어 모델 훈련, 엔드포인트 관리,
연결 설정 및 할당량 조정이 불필요
- 확장성 및 효율성 : 단일 SQL 쿼리로 수백만 개의 단일 변수 시계열을 몇 분 안에 예측할 수 있음
사용 방법
AI.FORECAST함수를 사용
예시) Single time series
- 일별 자전거 공유 여행의 총 횟수를 집계하고 향후 10일 동안의 여행 횟수를 예측하는 쿼리
- 샌프란시스코 공유 자전거 데이터 : bigquery-public-data.san_francisco_bikeshare.bikeshare_trips
SELECT * FROM AI.FORECAST((SELECT TIMESTAMP_TRUNC(start_date, DAY) AS trip_date, COUNT(*) AS num_trips FROM `bigquery-public-data.san_francisco_bikeshare.bikeshare_trips` GROUP BY 1),
timestamp_col=> 'trip_date',
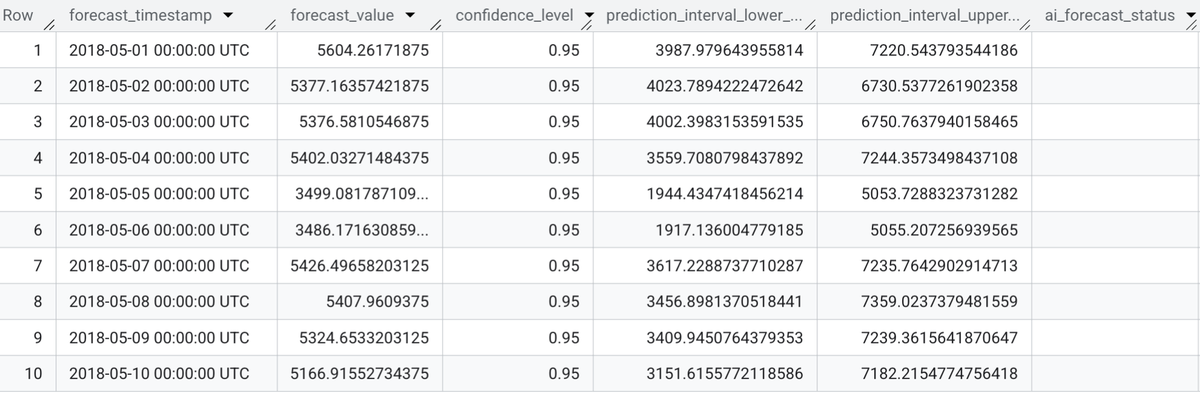
data_col=> 'num_trips');Result)
- 예측 타임스탬프와 예측 값(
forecast_timestamp,forecast_value)을 포함한 결과를 반환하며, 기본 신뢰 수준은 0.95
TimesFM과 ARIMA_PLUS 비교
- TimesFM
- 빠른, 즉시 사용 가능한 예측, 기준선 설정 또는 최소한의 설정으로 일반적인 추세 식별에 적합
- 여러 비즈니스 도메인에서 높은 사용 편의성과 우수한 일반화 기능을 제공하며, 종종 사용자 지정 훈련된 통계 및 딥러닝 모델보다 뛰어난 성능을 제공
- ARIMA_PLUS
- 특정 패턴 모델링, 계절성 또는 공휴일에 대한 예측 미세 조정, 다변수 예측(ARIMA_PLUS_XREG), 설명 가능한 결과 필요, 또는 더 긴 과거 컨텍스트를 활용해야 할 때 더 적합함
Docs : https: //cloud.google.com/bigquery/docs/reference/standard-sql/bigqueryml-syntax-ai-forecast
Advanced aggregation functions in BigQuery
BigQuery는 기본적인 집계 함수 외에도 더 복잡하고 정교한 사용 사례를 가능하게 하는 고급 집계 기능들을 통해 데이터 분석을 한 단계 끌어올릴 수 있습니다.
1) Group by extension
- GROUPING SETS, CUBE:
GROUPING SETS를 사용하면 단일 쿼리문으로 여러 차원에서 집계를 계산할 수 있습니다.
GROUP BY CUBE(x, y)는GROUPING SETS((x, y), x, y, ())의 단축 문법으로, 모든 조합의 차원에 따라 그룹화 할 수 있습니다.
- GROUP BY STRUCT, ARRAY:BigQuery에서 가장 많이 사용되는 데이터 타입인 STRUCT와 ARRAY를
GROUP BY와SELECT DISTINCT에 직접 사용할 수 있게 되어, 쿼리를 단순화하고 성능을 향상
- GROUP BY ALL:이 기능은
SELECT절에 있는 비집계 컬럼들을 자동으로 추론하여GROUP BY절에 동일한 컬럼을 두 번 나열할 필요가 없습니다.
2) 사용자 정의 집계 함수 (UDAFs)
사용자 지정 집계를 한 번 정의하고 프로젝트와 팀에서 재사용할 수 있도록 하여 이를 통해 가중 평균, JSON 데이터 병합 또는 지리공간 함수 시뮬레이션과 같은 고급 기능을 구현
- Javascript UDAF:내장 함수를 넘어선 사용자 지정 집계 로직을 생성
- SQL UDAF:복잡한 집계 표현식을 UDF로 캡슐화하여 재사용성을 높일 수 있음
3) 근사 집계 함수 (Approximate aggregate functions)
대량의 데이터를 분석할 때, 정확한 결과 대신 지정된 오차 범위 내의 근사 결과를 계산하여 더 빠른 응답을 얻고자 하는 경우, 스케치(Sketches)는 최소한의 메모리와 계산 오버헤드로 고유 카운트, 분위수, 히스토그램 및 기타 통계 측정의 근사치를 효율적으로 추정할 수 있게 해주는 기술
- KLL quantile functions(preview)
- Apache DataSketches:확률적 스트리밍 알고리즘을 위한 Apache DataSketches도 지원
- Theta Sketch:카디널리티(cardinality) 추정 및 집합 연산(합집합, 교집합, 차집합)을 위해 설계
- KLL Sketch:분위수(quantile) 추정을 위해 설계
- Tuple Sketch:추정된 고유 항목과 값을 연결하는 것을 지원하는 Theta Sketch의 확장 기능
Blogs : https: //cloud.google.com/blog/products/data-analytics/bigquery-advanced-aggregation-functions
Cloud SQL for MySQL integration with Vertex AI
Cloud SQL for MySQL에서 벡터 지원을 통해 벡터 임베딩을 저장, persistent index 구축하고 ANN(근사 최근접 이웃) 검색을 수행할 수 있습니다. 또한 Vertex AI 통힙 기능으로 SQL 함수를 사용해 벡터 임베딩 생성을 지원 합니다.
벡터 임베딩 생성, 저장 및 검색
mysql.ml_embedding함수를 사용하여 기존 제품 데이터에 벡터 임베딩을 추가
예시)
ALTER TABLE my_products ADD COLUMN embedding vector(768) using varbinary;
-- In this example,
product_description can be a text column describing the product in a given row UPDATE my_products SET embedding=mysql.ml_embedding('text-embedding-005', product_description);
- 유사한 제품을 빠르게 찾기 위하여 ANN search를 위한 벡터 인덱스 생성
예시)
CREATE VECTOR INDEX my_products_embedding_idx ON my_products(embedding) USING SCANN DISTANCE_MEASURE=COSINE NUM_LEAVES=500;
- 특정 행사를 위한 옷을 찾기 위한 쿼리
예시)
SELECT mysql.ml_embedding('text-embedding-005', 'Dress for a springtime black-tie wedding') into @query_vector;
SELECT approx_distance(embedding, @query_vector, 'distance_measure=cosine') as distance FROM my_products ORDER BY distance ASC LIMIT 5;
Gemini 및 기타 Vertex Al 모델로부터 응답 받기
Cloud SQL Vertex AI 통합으로 Vertex AI endpoint로 요청을 보낼 수 있으며 벡터 임베딩 생성 뿐만 아니라 예측 수행도 가능 합니다. 예를 들어 제품에 대한 고객 리뷰를 MySQL 데이터베이스에 저장하고 Vertex AI LLM을 호출하여 고객 만족도를 결정하고 그 평가를 저장할 수 있습니다.
예시)
SELECT mysql.ml_predict_row('publishers/google/models/gemini-2.0-flash:generateContent',
CONCAT('{ "contents": [{ "role": "user", "parts":[
{
"text": "Please rate customer sentiment from 1-10 based on the following review. Only output the number, nothing else. Text: \n', review_content, ' "
}
]
}
]
}
')) from customer_reviews;Docs : https: //cloud.google.com/sql/docs/mysql/integrate-cloud-sql-with-vertex-ai
