1. 개요
Google BigQuery는 서버리스 아키텍처를 기반으로 하는 페타바이트 규모의 완전 관리형 데이터 웨어하우스입니다. 인프라 관리 부담 없이 방대한 데이터를 실시간으로 분석할 수 있다는 강력한 장점이 있지만, 그 강력한 성능만큼이나 중요한 것이 바로 ‘비용(Cost)’입니다.
BigQuery의 유연한 과금 체계를 제대로 이해하지 못하면, 잘못된 쿼리 습관이나 설정 실수 하나로 예상치 못한 ‘요금 폭탄’을 맞을 수 있습니다. 반대로 과금 구조를 정확히 이해한다면 데이터 분석 전략의 효율성을 극대화할 수 있습니다. 본 가이드에서는 과금 체계의 핵심을 분석하고, 실제 실패 사례와 이를 극복하기 위한 고급 FinOps 전략, 그리고 비즈니스 규모별 맞춤 적용 시나리오까지 완벽하게 정리합니다.
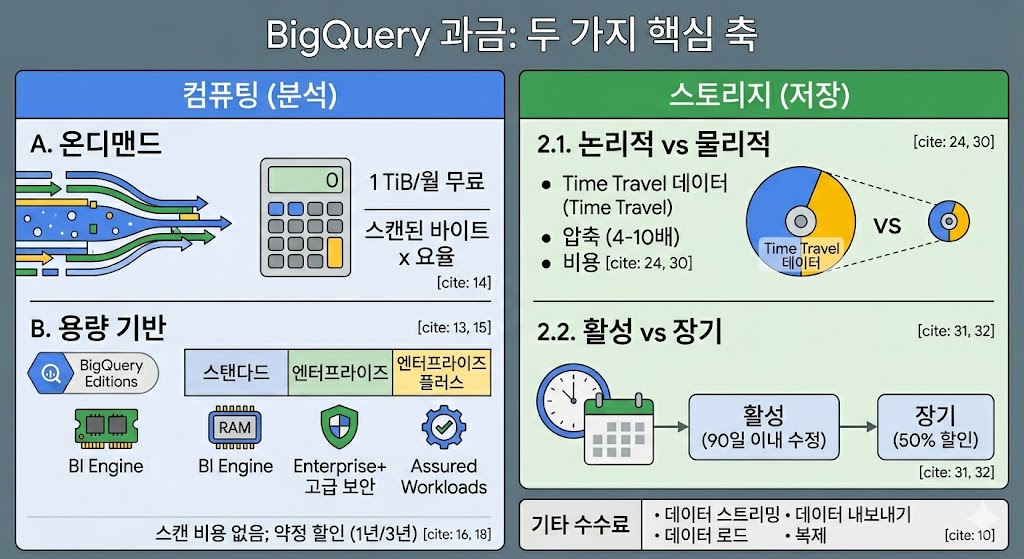
2. BigQuery 과금의 두 가지 핵심 축
BigQuery의 요금은 크게 컴퓨팅(분석) 요금과 스토리지(저장) 요금 두 가지로 구성됩니다. (※ 이 외에 데이터 스트리밍 삽입 등 수집/추출 비용이 별도로 발생할 수 있습니다.)
2.1 컴퓨팅(분석) 요금: 쿼리 실행 비용
쿼리를 실행하여 데이터를 처리할 때 발생하는 비용입니다. 워크로드 특성에 따라 두 가지 주요 모델 중 하나를 선택할 수 있습니다.
- A. 주문형(On-demand) 요금제: 쿼리가 처리(스캔)하는 데이터의 바이트 수에 따라 요금이 부과되는 가장 기본적이고 직관적인 방식입니다. 매월 첫 1테라바이트(TiB)의 데이터 처리는 무료로 제공됩니다. 사용량이 적거나 불규칙할 때 초기 비용 없이 유연하게 쓸 수 있지만, 대용량 테이블을 빈번하게 조회하면 비용이 급증할 수 있습니다.
- B. 용량 기반(Capacity-based) 요금제 (BigQuery Editions): 쿼리를 처리하는 가상 CPU 단위인 ‘슬롯(Slot)’을 구매하여 사용하는 방식입니다. 스캔한 데이터 양과 무관하게 예약한 슬롯 용량과 사용 시간에 대해서만 비용을 지불합니다.
[용량 기반 요금제: BigQuery 에디션별 기능 비교]
| 항목 | Standard | Enterprise | Enterprise Plus |
| 주요 대상 | 개발, 테스트, 임시 분석 | 프로덕션, 핵심 비즈니스 워크로드 | 미션 크리티컬, 고보안/고가용성 |
| 슬롯 할당 | 자동 확장만 지원 | 기준 슬롯(Baseline) + 자동 확장 | 기준 슬롯(Baseline) + 자동 확장 |
| 약정 할인 | ❌ 지원 안 함 | 1년(20%), 3년(40%) | 1년(20%), 3년(40%) |
| BI Engine 가속화 | ❌ 지원 안 함 | ✔ 지원 | ✔ 지원 |
| 고급 보안/거버넌스 | ❌ 기본 기능만 지원 | 열/행 수준 보안, CMEK 등 | ✔ Assured Workloads 등 최상위 보안 |
| 재해 복구 (DR) | ❌ 지원 안 함 | ❌ 지원 안 함 | ✔ 관리형 재해 복구 지원 |
💡 심층 분석: BI Engine 가속화의 비밀 (Enterprise 이상)
BI Engine은 Looker Studio나 Tableau 같은 BI 대시보드의 응답 속도를 1초 미만으로 줄여줍니다. 그 비결은 자주 사용하는 데이터를 메모리(RAM)에 지능적으로 캐시하는 인메모리 아키텍처와, 행 단위가 아닌 열 단위로 데이터를 한 번에 처리하는 벡터화 처리(Vectorized Processing) 기술에 있습니다.
2.2 스토리지 요금: 데이터 보관 비용
데이터세트(Dataset) 수준에서 과금 모델을 선택할 수 있으며, 데이터 수정 빈도에 따라 요금이 차등 적용됩니다.
논리적(Logical) vs 물리적(Physical) 스토리지
- 논리적 스토리지 (기본값): 압축 전 원본 크기를 기준으로 과금합니다. GB당 단가는 저렴하며, Time Travel(과거 7일 데이터 복구) 비용이 포함되어 있어 데이터 변경이 잦아도 비용 예측이 쉽습니다.
- 물리적 스토리지: 디스크에 압축되어 저장된 실제 크기를 기준으로 과금합니다. GB당 단가는 논리적 모델보다 약 2배 비싸지만, BigQuery의 압축률이 보통 4~10배에 달하므로 결과적으로 물리적 모델이 스토리지 총비용을 20~70% 절감하는 경우가 많습니다. 단, Time Travel 데이터에 대해서도 요금이 청구됩니다.
활성(Active) vs 장기(Long-term) 스토리지
- 활성 스토리지: 최근 90일 이내에 수정된 데이터에 적용됩니다.
- 장기 스토리지: 90일 연속으로 수정되지 않은 데이터는 자동으로 장기 스토리지로 분류되어 약 50% 저렴한 요금이 적용됩니다.
⚠️ 숨겨진 비용 분석: 장기 스토리지 데이터 수정의 함정
90일 이상되어 50% 할인을 받던 장기 스토리지 데이터에 UPDATE, DELETE 등의 DML을 실행하면 요금 폭탄의 원인이 될 수 있습니다. DML 실행 시 해당 데이터는 ① 즉시 비싼 ‘활성 스토리지’로 전환되고, ② 쿼리 스캔 비용이 발생하며, ③ 변경 전 데이터가 Time Travel 용량으로 잡혀 추가 스토리지 비용까지 3중으로 발생하게 됩니다.
3. ‘요금 폭탄’을 부르는 3가지 실패 사례와 해결책
사례 1: “LIMIT 100을 걸었으니 비용이 적게 나오겠지?” (SELECT * 와 LIMIT의 함정)
- 상황 및 원인: 대규모 테이블의 구조를 보기 위해 SELECT * FROM table LIMIT 100을 실행했습니다. 그러나 LIMIT 은 쿼리 결과물만 100건으로 잘라줄 뿐, BigQuery는 테이블 전체 데이터를 모두 스캔한 후 잘라냅니다. 즉, 1TB 테이블이면 1TB 전체 스캔 비용이 그대로 청구됩니다.
- 해결책: 전체 스캔 없이 일부 데이터만 샘플링하여 조회하려면 TABLESAMPLE을 사용해야 합니다. 이는 물리적 데이터 블록의 지정된 비율만 읽도록 지시하므로 직접적인 비용 절감으로 이어집니다.
SELECT * FROM `my_large_table` TABLESAMPLE SYSTEM (1 PERCENT);
사례 2: 파티션 필터 누락
- 상황 및 원인: 마케팅팀이 일별 데이터 파티셔닝된 테이블에서 특정 날짜 필터(WHERE date = …)를 빼먹고 쿼리를 실행했습니다. 그 결과 특정일 데이터가 아닌 수년 치 전체 데이터를 스캔하여 수십만 원의 쿼리 비용이 단 한 번에 발생했습니다.
- 해결책: 파티션 테이블 생성 시 require_partition_filter = true 옵션을 강제하여, 필터 조건이 없는 쿼리는 아예 실행되지 않도록 원천 차단해야 합니다.
사례 3: 오토스케일링(자동 확장) 설정 실수
- 상황 및 원인: 용량 기반 요금제 사용자가 워크로드 분석 없이 최대 슬롯(Max Slots) 수를 무한대에 가깝게 설정했습니다. 이로 인해 누군가 비효율적인 무거운 쿼리를 날릴 때마다 슬롯이 최대치로 확장되어 불필요한 과금이 대량 발생했습니다.
- 해결책: 안정적인 쿼리를 위한 ‘기준 슬롯(Baseline)’을 적절히 설정하고, 쿼리 폭주 시 비용 상한선 역할을 하는 ‘최대 예약 슬롯’ 한도를 합리적으로 제한해야 합니다.
4. FinOps 문화: 고급 비용 모니터링 전략
단순한 쿼리 최적화를 넘어, 프로젝트 수준의 강력한 통제 및 모니터링 체계를 갖추어야 합니다.
4.1 프로젝트/사용자 수준의 사전 비용 통제
- 커스텀 할당량(Custom Quotas): 프로젝트 전체 또는 사용자별로 일일 쿼리 한도(예: 10TB/일)를 설정하여 예산을 초과하는 지출을 원천적으로 차단합니다.
- 예산 및 알림(Budgets & Alerts): 예산의 50%, 90% 도달 시 담당자에게 알림을 발송하도록 설정하여 비용 이상 징후를 조기에 감지합니다.
4.2 INFORMATION_SCHEMA를 활용한 정밀 비용 추적
BigQuery 관리자라면 INFORMATION_SCHEMA.JOBS 뷰를 활용해 비용 주범을 찾아낼 수 있어야 합니다.
[주문형 요금제] 지난 30일간 비용이 가장 많이 발생한 쿼리 TOP 10
DECLARE TIB_PRICE FLOAT64 DEFAULT 7.50; — 서울 리전 기준 단가
SELECT
job_id, user_email, query,
SAFE.DIVIDE(total_bytes_billed, 1024*1024*1024*1024) AS total_terabytes_billed,
(SAFE.DIVIDE(total_bytes_billed, 1024*1024*1024*1024) * TIB_PRICE) AS estimated_cost_usd
FROM
`region-asia-northeast3`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 30 DAY) AND CURRENT_TIMESTAMP()
AND job_type = ‘QUERY’ AND statement_type != ‘SCRIPT’
AND total_bytes_billed > 0 AND cache_hit = FALSE
ORDER BY estimated_cost_usd DESC
LIMIT 10;
[용량 요금제] 지난 7일간 슬롯을 가장 많이 소모한 쿼리 TOP 10
SELECT
job_id, user_email, query,
SAFE.DIVIDE(total_slot_ms, 1000*60*60) AS total_slot_hours
FROM
`region-asia-northeast3`.INFORMATION_SCHEMA.JOBS_BY_PROJECT
WHERE
creation_time BETWEEN TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 7 DAY) AND CURRENT_TIMESTAMP()
AND job_type = ‘QUERY’ AND statement_type != ‘SCRIPT’
AND total_slot_ms > 0
ORDER BY total_slot_hours DESC
LIMIT 10;
5. 비즈니스 규모별 맞춤 최적화 시나리오
자신의 워크로드에 맞는 최적의 요금제 조합을 찾는 것이 FinOps의 핵심입니다.
- 스타트업 (불규칙한 탐색적 분석 위주): 주문형(On-demand) + 논리적(Logical) 스토리지
초기에는 1TiB 무료 제공량을 적극 활용합니다. 테이블 탐색 시 LIMIT 대신 TABLESAMPLE을 사용하고, 혹시 모를 비용 급증을 막기 위해 ‘커스텀 할당량’을 최하 수준으로 설정합니다. - 중견 기업 (정기적인 마케팅/BI 대시보드 운영): Enterprise 에디션 + 기준 슬롯 약정
매일 실행되는 무거운 쿼리는 주문형보다 슬롯 예약이 저렴합니다. BI Engine을 통해 대시보드 속도를 높이고, 예약(Reservation) 기능으로 ETL 작업과 BI 대시보드용 슬롯을 격리하여 성능을 안정적으로 유지합니다. - 글로벌 대기업 (미션 크리티컬 실시간 시스템): Enterprise Plus 에디션 + 물리적(Physical) 스토리지
단 몇 분의 장애도 허용되지 않으므로 ‘관리형 재해 복구(자동 장애 조치)’ 기능이 필수적입니다. 압축률이 높은 대용량 로그 데이터가 지속적으로 쌓이므로, 스토리지 요금은 물리적 모델을 채택하여 저장 비용을 극적으로 낮춥니다.
6. 결론
BigQuery는 매우 강력한 도구이지만, 효율적으로 사용하려면 명확한 전략이 필요합니다. SELECT * 금지, 파티션 분할 등 엔지니어링 차원의 노력은 기본입니다.
이에 더해 각 과금 모델(주문형 vs 용량형, 논리적 vs 물리적)의 특징을 깊이 이해하고, 사전에 할당량을 설정하며, INFORMATION_SCHEMA를 활용한 지속적인 모니터링 체계를 갖추는 FinOps 문화의 내재화가 반드시 동반되어야 합니다.
자세한 내용이 궁금하시다면, 메가존소프트 문의포탈을 통해 궁금한 부분을 남겨주세요.