토큰 경제 시대, AI 인프라 경쟁력은 속도보다 효율로 이동 중
요즘 기업의 AI 도입 논의에서 빠지지 않는 질문이 있습니다.
“이걸 실제 업무에 붙였을 때 비용을 감당할 수 있을까?”라는 질문입니다. 생성형 AI가 등장한 초기만 해도 모델 성능이 가장 큰 관심사였습니다. 모두가 어떤 모델이 더 똑똑한지, 어떤 모델이 더 긴 문맥을 처리하는지, 어떤 모델이 더 어려운 문제를 푸는지를 따졌습니다. 지금은 관심사가 다릅니다. 기업이 AI를 실제 서비스와 업무 시스템에 붙이기 시작하면서 비용 문제가 전면에 등장한 것이죠. 관련해 이번 포스팅에서는 실제 프론티어 모델을 기업에서 사용할 때 비용 최적화를 왜 해야 하는지 그리고 훈련과 추론을 구분해 AI 가속기를 선택하는 것이 실제로 어떤 비용 절감 효과가 있는지에 대해 알아보겠습니다.
무시할 수 없는 토큰 비용
AI 비용을 이해하려면 토큰(Token)이 무엇인지 알아야 합니다. 토큰이란 AI가 처리하는 정보의 기본 단위라고 이해하면 됩니다. 거대 언어 모델(LLM)의 경우 글자나 단어가 토큰이라는 단위로 처리됩니다. 우리가 보는 글자 수와 AI가 계산하는 토큰 수는 다릅니다. 최근 보편화되고 있는 멀티모달 모델은 텍스트뿐 아니라 영상, 이미지 같은 입력을 모두 유형별 최소 단위로 변환해 처리합니다. 입력이 다양해질수록 한 번의 요청이 만들어 내는 토큰량도 빠르게 늘어납니다.
토큰은 사용자가 요청을 할 때마다 비용이 발생합니다. 단순한 챗봇이 아니라 여러 에이전트를 운영하는 경우 문서를 읽고, 검색하고, 다시 판단하고, 도구를 호출할 때마다 토큰은 더 늘어납니다. 토큰 비용은 PoC 프로젝트를 할 때는 크게 눈에 들어오지 않습니다. 하지만 프로덕션 환경에서는 다릅니다. AI가 실험을 넘어 업무 흐름 안으로 들어올수록 토큰은 매우 큰 운영비가 됩니다. 이런 이유로 프로덕션 환경에서 AI 전환(AX)이 실제 일어나고 있는 조직이라면 “어떤 모델을 쓸 것인가”만 묻는 것으로는 부족합니다. “하나의 업무 결과를 만들기 위해 몇 개의 토큰을 쓰는가”, “그 토큰을 어떤 인프라에서 처리하는가”, “지연 시간과 비용을 동시에 낮출 수 있는가”를 함께 봐야 합니다.
이런 인식 변화는 AI 인프라 비용 논의의 무게중심도 바꿔 놓고 있습니다. 예전에는 클라우드 환경에서 고성능 GPU 한 장을 시간당 얼마에 쓰는지가 중요했습니다. 지금은 고객 응대 한 건, 코드 리뷰 한 건, 보고서 초안 한 건, 리스크 분석 한 건에 얼마의 토큰을 쓰는지가 더 중요해지고 있습니다. 특히 요즘 에이전트가 대세가 되면서 토큰 처리 비용을 어떻게 최적화할 것인지가 더욱 중요해지고 있습니다. 에이전트는 한 번의 질문에 바로 답하고 끝나지 않습니다. 사내 문서를 검색합니다. 외부 도구를 호출합니다. 중간 결과를 평가합니다. 필요하면 다시 계획을 수정합니다. 한 번의 사용자 요청이 여러 번의 모델 호출로 이어지는 것입니다.
이런 구조에서는 모델 호출 단가가 조금만 높아도 전체 운영비가 빠르게 커집니다. PoC에서는 크게 보이지 않던 비용이 전사 업무에 붙고, 고객 서비스에 연결되고, 개발 조직 전체가 쓰기 시작하면 곧바로 비용이 눈덩이처럼 늘어나게 됩니다.
한편, 토큰 비용은 단순한 예산 문제가 아닙니다. AI를 기업의 주요 제품이나 서비스에 적용한 경우 비즈니스 경쟁력과도 연결됩니다. 같은 품질의 답을 더 적은 비용으로 만들 수 있는 기업은 더 낮은 가격으로 제품이나 서비스를 제공할 수 있습니다. 같은 비용으로 더 많은 사용자를 지원할 수도 있습니다. 더 긴 컨텍스트와 더 복잡한 에이전트 워크플로도 감당할 수 있습니다.
이제 AI 인프라 경쟁은 “GPU를 얼마나 많이 확보했는가”에서 끝나지 않습니다. 어떤 워크로드에 어떤 유형의 AI 가속기를 쓰는지, 학습과 추론을 같은 방식으로 처리해도 되는지, 추론 요청을 어떻게 분산하는지, 캐시와 메모리 대역폭을 어떻게 활용하는지가 모두 토큰 비용을 좌우합니다.
구글 클라우드가 학습과 추론을 분리해 보는 이유
그렇다면 AI 인프라 측면에서 토큰 비용을 어떻게 최적화할 수 있을까요?
GPU만 고집할 것이 아니라 AI 워크로드 유형에 맞는 AI 가속기를 유연하게 선택하는 것부터 시작할 수 있습니다.
AI 모델의 학습과 추론은 둘 다 AI 워크로드입니다. 하지만 AI 인프라 관점에서는 전혀 다른 성격을 가집니다. 학습은 대규모 데이터를 반복적으로 처리합니다. 많은 칩이 긴 시간 동안 함께 움직입니다. 높은 처리량, 고속 인터커넥트, 안정적인 장기 실행, 빠른 체크포인트가 중요합니다. 학습 작업은 며칠 또는 몇 주 동안 이어질 수 있습니다. 중간 장애가 발생하면 비용 손실이 커집니다.
추론은 다릅니다. 사용자가 요청을 보내면 즉시 응답해야 합니다. 요청마다 길이도 다릅니다. 어떤 요청은 짧은 답변으로 끝납니다. 어떤 요청은 긴 문서와 도구 호출을 포함합니다. 이때 중요한 것은 첫 토큰 생성 시간, 전체 응답 지연 시간, 캐시 효율, 동시 요청 처리량입니다.
구글의 TPU 전략은 훈련과 추론의 차이에서 비용 최적화 방안을 찾습니다. 현재 정식 출시된 칩은 7세대 Ironwood로, 학습과 추론을 함께 다룰 수 있도록 설계됐습니다. 한 발 더 나아가 구글은 Cloud Next 2026에서 8세대 TPU를 공개하며 라인을 처음으로 둘로 쪼갰습니다. 학습 전용 TPU 8t와 추론 전용 TPU 8i입니다. TPU 8t는 슈퍼팟 하나당 9,600개 칩 규모의 대규모 사전 학습에 최적화돼 있고, Ironwood 대비 2.7배 수준의 학습 가격 대비 성능을 제공한다고 발표됐습니다. TPU 8i는 대규모 MoE 모델의 저지연 추론에 초점을 두고, 이전 세대 대비 80% 향상된 가격 대비 성능을 제시합니다. 이 8세대 칩은 TSMC 2나노 공정으로 2027년 말 출시 예정인 차세대 로드맵입니다.
칩만 나누는 것이 아닙니다. GKE, Dynamic Workload Scheduler, GKE Inference Gateway, vLLM, JAX, PyTorch 같은 소프트웨어 계층을 함께 묶습니다. 쉽게 말하면 “워크로드 유형과 특성이 다르면 칩과 운영 방식도 달라야 한다”는 식의 접근입니다. 토큰당 비용을 구조적으로 낮추려면 학습과 추론을 같은 방식으로 다뤄서는 안 됩니다.
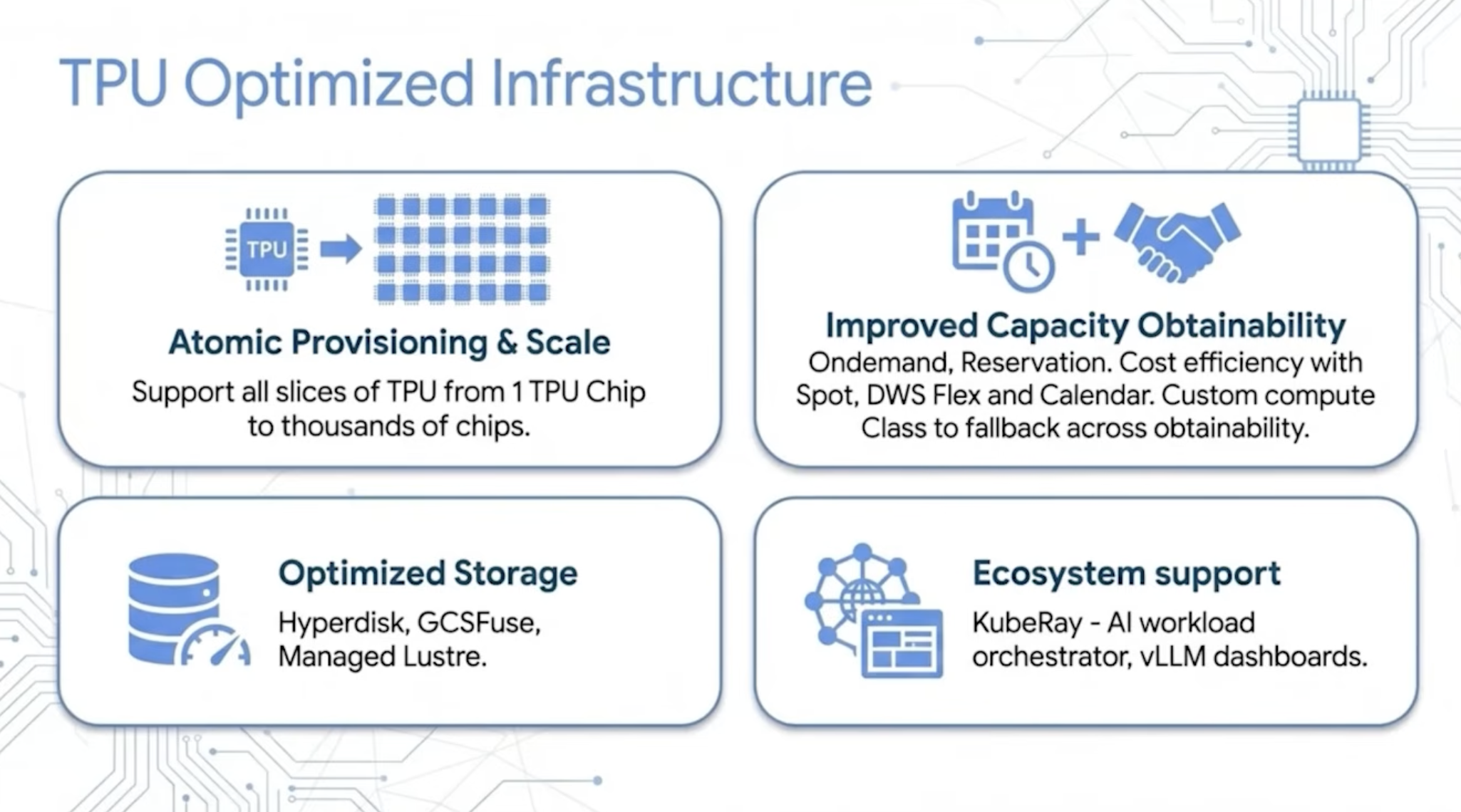
TPU의 진짜 가치는 칩 한 장이 아니라 운영 구조에서 나온다!
TPU가 일반 가속기와 다른 지점은 칩 한 장의 성능만이 아닙니다. TPU는 슬라이스라는 단위로 묶여 동작합니다.
슬라이스는 수십에서 수천 개의 칩을 고속 인터커넥트로 연결해 하나의 원자적 자원처럼 다루는 묶음입니다. 학습 작업은 이 슬라이스 단위로 실행됩니다. 대규모 학습 작업은 필요한 칩을 모두 확보해야 의미 있게 실행됩니다. 예를 들어 64개 칩이 필요한 작업에 60개만 먼저 배치하면 나머지 칩을 기다리는 동안 자원이 낭비됩니다. 일부 가속기는 일을 하지 않는데 비용은 계속 발생합니다.
GKE는 TPU 슬라이스를 하나의 원자적 단위(Atomic Unit)로 다룹니다. 필요한 자원이 모두 준비됐을 때 작업을 실행합니다. JobSet과 큐 기반 스케줄링은 이런 대규모 작업 배치에 중요합니다. 팀별 쿼터와 우선순위를 관리하고 전체 노드가 정상적으로 올라온 뒤 학습을 시작할 수 있게 합니다. 장애 복구도 비용 최적화의 핵심입니다. 수만 개의 칩을 장시간 사용하는 환경에서 장애는 피하기 어렵습니다. GKE는 자동 복구와 체크포인트 전략을 통해 실제 학습에 기여한 시간, 즉 굿풋을 높입니다. 처리량이 높아도 장애 복구와 데이터 로딩에 시간이 많이 쓰이면 실제 비용 효율은 떨어집니다. 정리하자면 AI 인프라는 단순 컴퓨팅 자원 묶음이 아닙니다. 스케줄링, 체크포인트, 복구, 데이터 로딩까지 포함한 운영 체계입니다. 가속기가 쉬는 시간을 줄이는 것이 곧 비용 절감입니다.
라우팅에서 갈리는 추론 비용
학습이 슬라이스의 게임이라면 추론은 라우팅의 게임입니다. 같은 TPU 자원을 두고 요청을 어떻게 분배하느냐에 따라 첫 토큰 생성 시간과 처리량이 달라집니다. 일반적인 라운드로빈 로드밸런싱은 LLM 추론에 잘 맞지 않습니다. 요청마다 처리 시간이 다르기 때문입니다. 긴 문서 분석 요청이 특정 인스턴스에 몰리면 가벼운 요청도 줄을 서게 됩니다. 일부 서버는 과부하 상태가 되고, 일부 서버는 남는 용량을 갖게 됩니다.
GKE Inference Gateway는 모델 서버의 부하, 로컬 큐, KV 캐시 상태를 고려해 요청을 보냅니다. 또한 같은 컨텍스트를 다시 처리하지 않도록 프리픽스 캐시 적중률이 높은 서버에 우선 라우팅하는 기능도 제공합니다. 모델 서버 내부 상태를 라우팅에 반영한다는 점이 일반 로드 밸런서와 다릅니다.
이런 식의 접근은 토큰 경제(Token Economy) 시대에 중요합니다. 캐시를 제대로 활용하지 못하면 같은 맥락을 반복해서 처리합니다. 요청 분산이 비효율적이면 가속기 가동률이 떨어집니다. 지연 시간이 늘면 더 많은 인스턴스를 띄워야 하고 이는 곧 비용으로 이어집니다.
기업이 실시간 AI 서비스를 운영한다면 이 지점이 중요합니다. 고객 응대, 코드 보조, 문서 분석, 검색형 챗봇, 에이전트 서비스는 트래픽 패턴이 일정하지 않습니다. 어떤 요청은 짧고, 어떤 요청은 매우 깁니다. 추론 게이트웨이는 이런 불균형을 흡수하는 핵심 계층이 됩니다.
토큰 경제 시대의 인프라 전략
앞서 소개한 바와 같이 토큰 경제 시대의 AI 인프라는 칩 하나로 결정되지 않습니다. 학습, 파인튜닝, 배치 추론, 실시간 추론, 에이전트 실행, 장애 복구, 스토리지, 네트워크, 스케줄링이 모두 비용 구조에 들어갑니다. 구글 클라우드의 TPU와 GKE 조합은 이 전체를 하나의 운영 환경으로 묶습니다. 학습과 추론의 물리적 특성을 나누고, 슬라이스 단위로 가속기를 관리하며, 추론 게이트웨이로 요청 라우팅을 최적화합니다. 이제 경쟁력은 “얼마나 큰 모델을 쓰는가”에서 나오지 않습니다. “얼마나 적은 비용으로 더 많은 유용한 토큰을 처리하는가”가 경쟁력의 원천입니다. 토큰당 비용을 측정하고, 학습과 추론을 분리하고, 가속기 유휴 시간을 줄이는 일을 함께 챙기는 조직이 AI 인프라 경쟁에서 앞서갈 수 있습니다.
더 자세한 내용이 궁금하다면 메가존소프트 문의포탈을 통해 궁금한 부분을 남겨주세요.