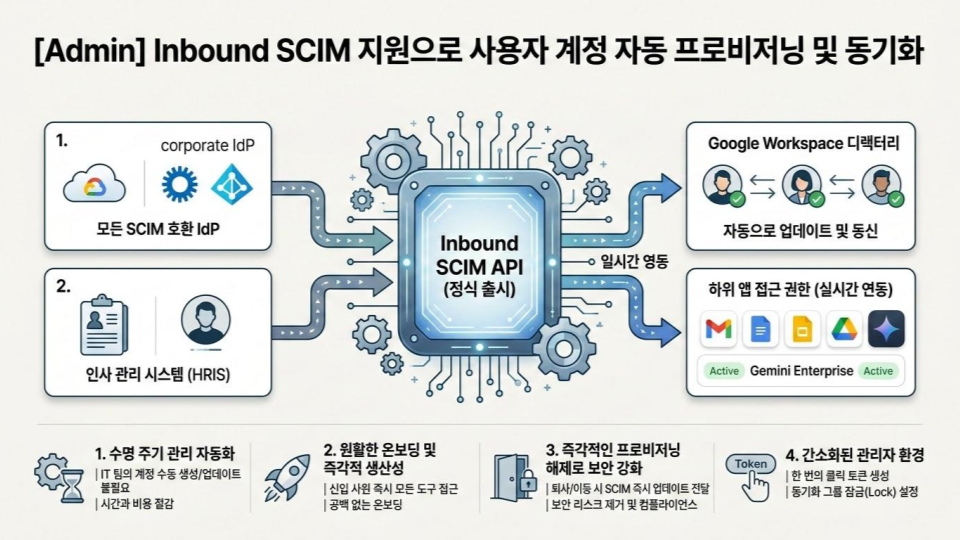
생성형 AI가 기업의 프로덕션 환경으로 들어오기 시작하면서 데이터베이스의 역할이 달라지고 있습니다.
예전에는 데이터를 안정적으로 저장하고 정해진 업무 화면에 필요한 정보를 제공하는 것이 데이터베이스의 역할이었습니다. 에이전틱 AI 시대가 되면서 데이터베이스는 새로운 역할을 요구받고 있습니다.
애플리케이션은 사용자 행동을 실시간으로 읽어야 합니다. 추천 시스템은 방금 발생한 클릭과 구매 이력을 반영해야 합니다.
사기 탐지 시스템은 거래가 일어나는 순간 판단해야 합니다. AI 기반 챗봇이나 에이전트는 프롬프트, 응답, 세션 상태, 피드백 데이터를 빠르게 저장하고 다시 불러와야 합니다. 모델이 아무리 좋아도 최신 데이터를 빠르게 읽지 못하면 서비스 품질은 떨어집니다. 이런 변화는 데이터베이스 선택 기준을 바꿉니다. AI 시대의 실시간 서비스는 대규모 쓰기, 낮은 지연 시간, 지속적인 확장성, 운영 데이터와 분석 데이터의 연결을 동시에 요구합니다.
구글 클라우드의 Bigtable은 AI 시대의 이런 요구에 맞춰 진화를 거듭하고 있습니다. Bigtable은 이제 단순히 데이터를 보관하는 저장소가 아닙니다. 사용자와 모델이 필요로 하는 최신 상태를 빠르게 제공하는 실시간 서빙 계층으로 기능과 역할을 확장하고 있습니다. 관련해 이번 포스팅에서는 Bigtable을 예로 AI 시대의 데이터베이스가 갖추어야 할 특성을 짚어 볼까 합니다.
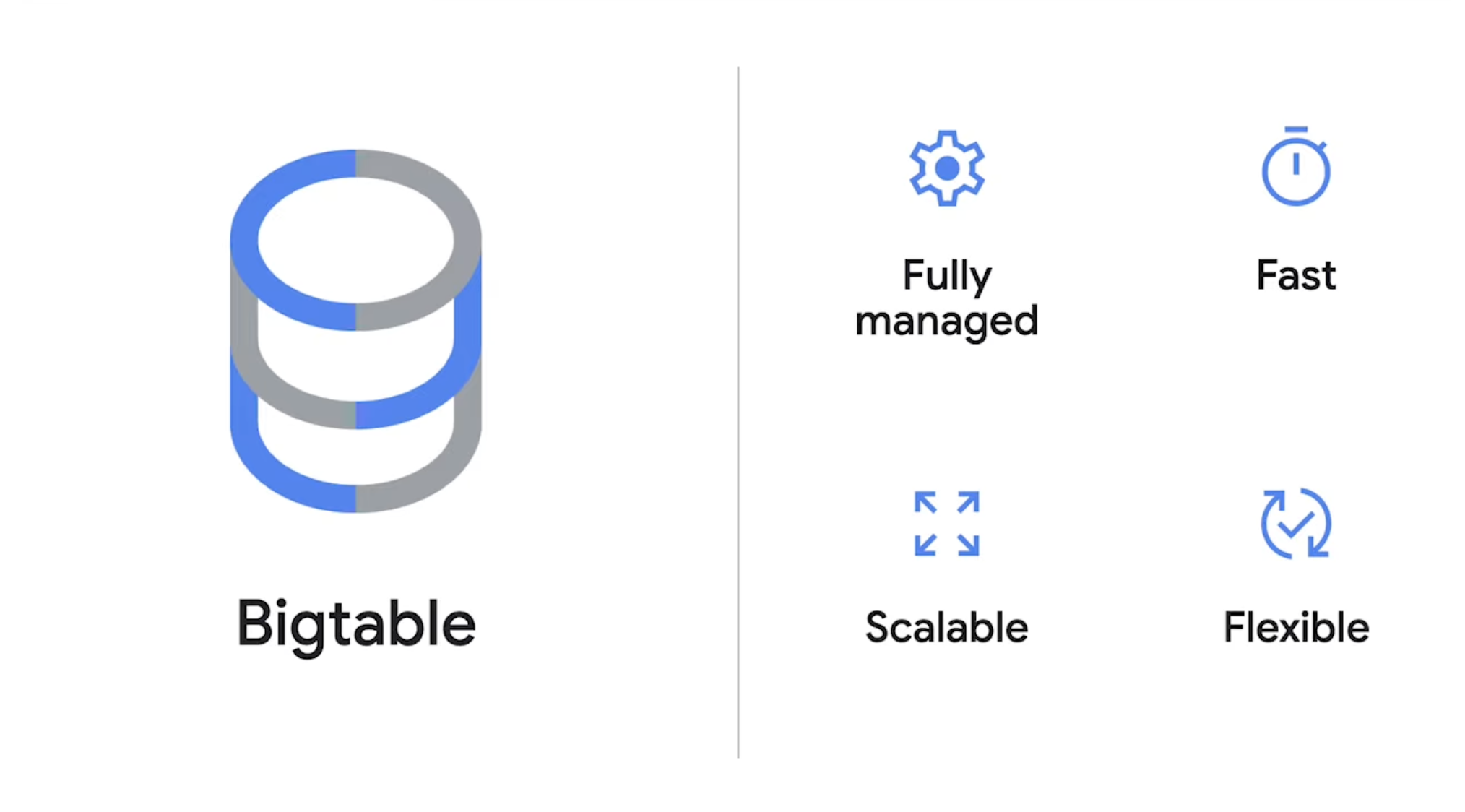
Bigtable은 어떤 데이터베이스인가?
Bigtable은 구글 클라우드의 완전 관리형 NoSQL 데이터베이스입니다.
와이드 컬럼 기반의 키-값 저장소이며 수만 개의 컬럼과 페타바이트 규모의 데이터까지 확장할 수 있습니다. 여러 리전에 데이터를 복제하는 글로벌 복제를 통해 고가용성과 복원력도 확보할 수 있습니다. Bigtable의 특장점은 다음과 같이 정리해 볼 수 있습니다.
- 데이터 모델: 모든 행이 동일한 열을 가질 필요가 없습니다. 특정 행에 값이 없는 열은 저장 공간을 차지하지 않습니다. 사용자 프로필, 상품 속성, 로그 이벤트, AI 세션 메타데이터처럼 구조가 계속 바뀌는 데이터에 유리합니다.
- 시간 버전 관리: 같은 셀에 여러 버전의 값을 저장할 수 있기 때문에 특정 시점의 상태를 추적하거나, 시간에 따른 변화 흐름을 분석하는 데 유리합니다. 이는 로그, 피처, 센서, 세션 데이터처럼 시간축이 중요한 워크로드와 잘 맞습니다.
- 자동 데이터 티어링: Bigtable은 RAM, SSD, HDD 사이에서 데이터를 자동으로 이동시켜 자주 쓰이는 데이터는 빠르게 읽고, 잘 쓰이지 않는 데이터는 비용 효율적으로 저장합니다. 별도 캐싱 계층을 두지 않아도 핫 데이터를 RAM 수준의 지연 시간으로 다룰 수 있습니다.
- SQL 친화성: GoogleSQL for Bigtable이 더해지면서 관계형 데이터베이스에 익숙한 개발자도 SQL로 Bigtable 데이터를 탐색할 수 있게 됐습니다. NoSQL의 확장성을 유지하면서 SQL의 친숙함을 함께 제공하려는 방향입니다. 여기에 변경 사항을 실시간으로 반영하는 연속 구체화 뷰(continuous materialized views), 글로벌 보조 인덱스 같은 기능이 더해지면서 단순 키-값 조회 이상의 분석성도 갖추고 있습니다.
다만 위와 같은 강점을 살리려면 한 가지 설계 조건을 지켜야 합니다. 바로 행 키 설계입니다. 어떤 방식으로 행 키를 구성하느냐에 따라 읽기 성능과 쓰기 분산이 달라집니다. 사용자별 활동 이력을 빠르게 불러와야 한다면 사용자 ID와 시간 정보를 조합한 키를 설계할 수 있습니다. 장치별 센서 데이터를 읽어야 한다면 장치 ID와 타임스탬프를 조합할 수 있습니다. 즉, Bigtable을 도입할 때는 어떤 데이터를 저장할 것인가보다 어떤 방식으로 읽을 것인가를 먼저 봐야 합니다. 사용자 단위, 장치 단위, 세션 단위, 시간 구간 단위 조회 패턴이 명확하다면 Bigtable의 장점이 극대화됩니다. 반대로 복잡한 조인과 임의 조건 검색이 많다면 다른 데이터베이스가 더 적합할 수 있습니다.
구글이 직접 검증한 데이터베이스
Bigtable은 구글이 대규모 인터넷 서비스를 운영하면서 현장에서 검증을 마친 데이터베이스입니다.
Google Search, Ads, Drive, Analytics, Maps, YouTube 같은 지연 시간 민감형 워크로드에 주로 사용되어 왔습니다. 트래픽 규모와 지연 시간 요구가 높은 서비스에서 발전했고 데이터가 폭발적으로 증가해도 사용자 경험을 유지해야 하는 환경에서 검증된 데이터베이스입니다.
외부 고객 사례도 다양합니다. 음악 스트리밍, 금융 거래 플랫폼, 머신러닝 플랫폼 등에서 Bigtable을 피처 저장소, 실시간 데이터 서빙 계층, 대규모 이벤트 저장소로 활용하고 있습니다. 산업이 달라도 공통점은 같습니다. 데이터가 빠르게 쌓이고 낮은 지연 시간으로 다시 읽어야 하는 조건에서 Bigtable의 제 역할을 하고 있습니다.

AI 시대에 Bigtable을 다시 봐야 하는 이유
AI 시대의 데이터 워크로드는 세 방향으로 바뀌고 있습니다. 데이터 생성 속도가 빨라졌습니다. 데이터 활용 시점이 앞당겨졌습니다.
운영 데이터와 분석 데이터의 경계가 흐려졌습니다. 추천 모델은 사용자의 최근 행동을 알아야 합니다. 사기 탐지 모델은 현재 거래 맥락과 과거 이상 패턴을 함께 봐야 합니다. 고객 상담 AI는 최근 문의와 상품 이용 상태를 빠르게 불러와야 합니다.
Bigtable은 이 환경에서 실시간 서빙 계층 역할을 할 수 있습니다. 낮은 지연 시간, 높은 처리량, 수평 확장, 시간 버전 데이터 모델, 연속 구체화 뷰, BigQuery와의 연결, 글로벌 복제, 자동 티어드 스토리지를 제공합니다. 실시간 AI 애플리케이션을 위한 운영 데이터 기반으로 볼 수 있습니다.
특히 AI 에이전트 환경에서는 세션 상태, 도구 호출 기록, 사용자 피드백, 안전성 점검 결과가 계속 쌓입니다. 이 데이터는 구조가 고정되어 있지 않고 시간에 따라 변합니다. 특정 사용자, 세션, 문서, 장치, 워크플로 단위로 빠르게 조회해야 합니다. Bigtable의 와이드 컬럼 모델과 타임스탬프 기반 버전 관리는 이런 패턴과 잘 맞습니다. 최근에는 Agent Development Kit(ADK)용 Bigtable 도구도 정식 공개되어 AI 에이전트가 Bigtable의 메타데이터를 탐색하고 LLM 기반 SQL 쿼리를 실행하는 흐름도 직접 지원합니다.
다만 Bigtable이 모든 역할을 맡아야 하는 것은 아닙니다. 장기 분석은 BigQuery가 맡고 관계형 트랜잭션은 Cloud SQL, AlloyDB, Spanner가 맡을 수 있습니다. Bigtable은 이들 사이에서 실시간 서빙 계층으로 자리 잡을 때 시너지를 냅니다. 즉, BigQuery가 장기 분석 계층이고 Cloud SQL·AlloyDB·Spanner가 트랜잭션 계층이라면 Bigtable은 사용자와 모델이 즉시 필요로 하는 최신 상태를 제공하는 실시간 서빙 계층입니다.
AI는 모델만으로 움직이지 않는다!
AI는 모델만으로 움직이지 않습니다. 모델이 만나는 데이터의 신선도, 접근 속도, 운영 안정성이 함께 결정합니다.
Bigtable은 그중 실시간 데이터 접근 속도와 확장성을 보장하는 역할도 할 수 있습니다. 물론 Bigtable이 모든 데이터베이스를 대체하지는 않습니다. 복잡한 조인, 다중 행 트랜잭션, 강한 관계형 제약 조건이 핵심인 업무라면Cloud SQL, AlloyDB, Spanner가 더 적합할 수 있습니다.
하지만 초대규모 실시간 읽기·쓰기 패턴이 있고, AI 기능이 추론 시점에 최신 데이터를 몇 밀리초 안에 필요로 한다면 Bigtable은 잊지 말고 사전에 검토해야 봐야 할 선택지라 할 수 있습니다. 실시간으로 쓰고, 실시간으로 읽고, 실시간으로 판단해야 하는 기업이라면 Bigtable을 꼭 살펴보세요.
더 자세한 내용이 궁금하다면 메가존소프트 문의포탈을 통해 궁금한 부분을 남겨주세요.