2026년은 년초부터 온디바이스AI(On Device AI) 의 잠재력을 보여주는 소식이 계속 이어지는 것 같습니다.
OpenClaw가 공개되자마자 맥미니 판매가 급증하는 현상이 일어났는데 몇 개월 지나지 않았는데 Gemma 4가 애플 실리콘 기반 장치 수요를 끌어 올리고 있습니다. 이번 포스팅에서는 Gemma 4의 기술적 특성과 함께 개인용 컴퓨팅 환경에서의 활용 가능성, 그리고 온디바이스 AI의 전략적 활용 방안을 알아보겠습니다.
Gemma 4의 인기 비결
2026년 4월 2일 구글 딥마인드가 공개한 Gemma 4는 최첨단 상용 모델인 Gemini 3과 동일한 연구 기반에서 탄생한 네 번째 세대 오픈 모델입니다. 이번 발표가 특히 주목받는 이유는 상용 활용에 제약이 없는 Apache 2.0 라이선스를 전격 채택했기 때문입니다. 기업이든 개인이든 라이선스 비용 부담 없이 모델을 수정하고 재배포하며 상용 제품에 통합할 수 있는 길이 열린 것이죠.

Gemma 4는 선택지도 넓습니다. 굳이 새로운 장치를 사지 않아도 현재 사용 중인 장치 스펙에 맞는 선택을 할 수 있습니다. 심지어 모바일, 엣지 장치도 활용할 수 있습니다.
- E2B와 E4B: 모바일과 엣지 환경을 겨냥한 소형 모델입니다. 층별 임베딩(Per-Layer Embeddings, PLE) 기술을 적용해 제한된 하드웨어 자원에서도 높은 지능을 발휘하도록 설계되었습니다.
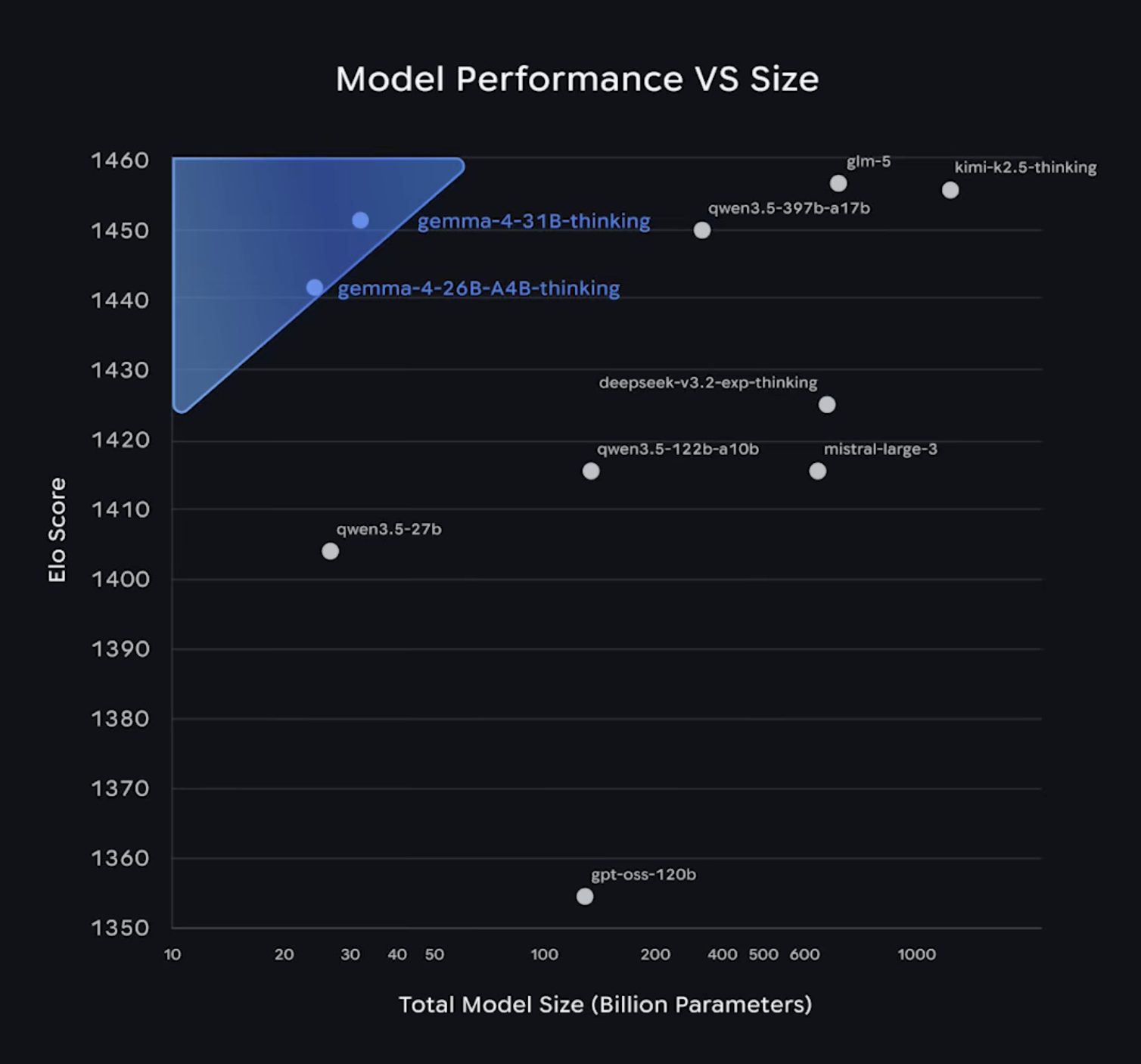
- 31B Dense: 고성능 추론에 특화된 모델로 파라미터 수가 수십 배 큰 거대 모델들을 위협하는 성능을 보여줍니다.
- 26B MoE(Mixture-of-Experts): 가장 흥미로운 모델입니다. 총 26B 파라미터 중 추론 시에는 약 38억 개만 활성화하여 연산 효율을 극대화했습니다. 128개의 전문가 중 토큰당 8개만 선택해 사용하는 희소 활성화 방식으로 26B 규모의 지식 수용량을 유지하면서도 실제 연산 비용은 4B 수준으로 낮추었습니다. 별도의 공유 전문가(Shared Expert)가 기본 지식을 보완해 31B Dense 모델에 근접하는 수준의 답변을 내놓습니다.
Gemma 4 등장 후 이를 설치해 사용하는 이들이 빠르게 늘어난 이유는 성능 때문입니다. Gemma 4는 31B Dense 기준으로 전작인 Gemma 3 27B와 비교했을 때 수학 벤치마크 AIME 2026 점수는 20.8%에서 89.2%로 코딩 벤치마크 LiveCodeBench는 29.1%에서 80.0%로 수직 상승했습니다. 과학적 추론 GPQA 지표 역시 42.4%에서 84.3%로 두 배 가까이 올랐습니다. 모델 크기를 키우는 대신 구조적 최적화와 정교한 데이터 튜닝으로 바이트당 성능을 끌어올린 결과입니다.
단순 챗봇을 넘어선 실행 가능한 지능
성능이 발군이다 보디 활용도가 높습니다. Gemma 4는 단순히 묻는 말에 대답하는 챗봇을 넘어 스스로 계획을 세우고 도구를 사용하는 에이전트 워크플로를 지향합니다. 모든 모델이 텍스트와 이미지 입력을 기본으로 처리하며 소형 모델인 E2B와 E4B는 오디오 입력까지 직접 처리합니다. 비전 토큰을 이미지 해상도와 종횡비에 맞춰 동적으로 할당하는 기술로 멀티 모달 처리의 정밀도도 높였습니다.
Gemma 4에서 주목할 특징 중 하나는 사고 모드(Thinking Mode)입니다. 최종 답변을 내놓기 전 내부적으로 단계별 추론 과정을 거치도록 훈련된 이 기능은 논리적 단계가 중요한 작업에서 진가를 발휘합니다. 시스템 프롬프트에 특정 토큰을 포함하면 모델은 답변 전 단계에서 사용자의 의도를 분석하고, 필요한 도구를 선정하며, 출력 형식이 요구사항에 맞는지 자체적으로 점검합니다.
자율적인 문제 해결 능력도 눈에 띕니다. 코드를 작성하고 실행하는 과정에서 환경의 제약으로 오류가 발생하면 AI가 즉시 원인을 파악해 대안을 찾아냅니다. 라이브러리 가속 기능을 사용할 수 없는 샌드박스 환경에서 애니메이션을 구현해야 할 때 직접 수학적 물리 엔진을 설계해 문제를 해결하는 사례는 Gemma 4가 단순한 코드 복사기가 아닌 지능형 에이전트임을 보여줍니다.
또한, JSON 스키마 기반의 함수 호출(Function Calling)을 학습 데이터 수준에서 지원합니다. ADK와 MCP를 활용하면 구글 지도, 파일 시스템, 데이터베이스 등 외부 서비스의 데이터를 실시간으로 가져와 복잡한 다단계 과업을 수행할 수 있습니다.
온디바이스 AI의 전략적 활용 방안
Gemma 4를 로컬 환경에 구축했다면 이를 어떻게 실무에서 효과적으로 활용할 수 있을까요? 개발자라면 코딩 어시스턴트로 활용하는 것을 가장 먼저 떠올릴 것입니다. 코드 자동 완성, 리팩터링 제안, 테스트 코드 생성 작업을 로컬 서버에서 처리하면 지연 시간을 최소화할 수 있고, 핵심 소스 코드가 외부로 유출될 걱정도 없습니다.
일반적인 사무를 보는 사용자라면 평소 쓰던 유료 생성형 AI 서비스를 이용하듯이 쓰면 됩니다. Gemma 4의 컨텍스트 윈도우는 상용 서비스 부럽지 않습니다. 소형 모델은 128K, 중대형 모델은 256K 토큰을 지원하는데, 수백 페이지 분량의 문서를 한꺼번에 입력받아 맥락을 파악할 수 있는 수준입니다. RAG를 연계하면 활용도가 더 높아집니다. 사내 위키, 개인 메모, 이메일 기록 등을 로컬 벡터 데이터베이스에 색인해 두고 Gemma 4와 연결하면 외부 네트워크 연결 없이도 자연어로 질의하고 정확한 답변을 얻을 수 있습니다.
개인이 아니라 조직 측면에서 볼 때 Gemma 4의 활용 가치를 높이는 방법은 무엇일까요? 현실적인 운영 전략으로는 로컬과 클라우드를 결합하는 것입니다. 보안이 중요한 반복적 일상 업무는 개인 기기의 Gemma 4가 처리하고 거대한 연산량이나 최신 웹 검색이 필요한 복잡한 프로젝트는 클라우드 API로 넘기는 방식입니다.
추론 비용 절감도 가능?
Gemma 4는 AI가 데이터센터를 벗어나 사용자의 책상 위와 손안으로 내려올 수 있다는 가능성을 널리 알리고 있는 모델입니다. 에이전틱 AI가 새로운 투자 방향으로 자리를 잡으면서 추론 작업에 소요되는 비용 부담이 새로운 도전 과제가 되었습니다. 비용을 적절히 통제하면서 AI 활용을 전사적으로 확산하는 데 있어 클라우드와 로컬 투 트랙으로 모델에 접근하는 것이 갖는 이점은 분명해보입니다. 앞으로 어떤 변화가 일어날 지 지속해서 블로그를 통해 내용을 공유하겠습니다.
더 자세한 내용이 궁금하다면 메가존소프트 문의포탈을 통해 궁금한 부분을 남겨주세요.