데이터 관련해 영원한 과제가 있다면 아마 마이그레이션일 것입니다. 어떤 기술이건 시대가 지나면 낡게 마련입니다. 메가 트렌드가 바뀔 때마다 새로운 환경으로 데이터를 최신 플랫폼으로 옮기는 것은 늘 중요 과제였습니다. 클라우드 네이티브와 AI라는 큰 흐름이 주류인 2026년 데이터 엔지니어들에게 주어진 시급한 과제 역시 마이그레이션입니다.
이번 포스팅에서는 마이그레이션을 단순히 플랫폼을 최신 환경으로 바꾸는 것(Lift-and-Shift)이 아닌 현대화(Modernization) 관점에서 바라보고 구글 클라우드가 어떻게 성공적인 마이그레이션 여정을 안내하는지 알아보겠습니다.
마이그레이션을 주저하는 이유
데이터 플랫폼을 옮기는 일은 앱을 이전하는 것보다 훨씬 복잡합니다. 짧게는 수년, 길게는 십수 년 간 쌓인 기술적 부채와 복잡한 상호 의존성이 얽혀 있어 조심스러운 작업이 요구됩니다.
가장 큰 도전 과제는 SQL 문법의 차이입니다. 예를 들어 Teradata의 MERGE JOIN이나 Snowflake의 TIMESTAMP_TZ 같은 고유 기능을 BigQuery 표준인 GoogleSQL로 바꾸려면 단순 치환이 아니라 문맥을 완벽히 이해하는 의미론적 번역이 필요합니다.
게다가 문서화되지 않은 채 숨어 있는 ETL 파이프라인, 소유자가 불분명한 좀비 데이터 그리고 테이블 간의 복잡한 리니지(Lineage)는 계획 수립 단계부터 엔지니어의 발목을 잡습니다. 무엇보다 “문제없이 잘 작동하니 손대지 말자(If it works, don’t touch it)”는 식의 보수적인 문화도 현대화를 가로막는 보이지 않는 벽입니다.
오래된 습관을 버리고 현대화로 가는 길
긍정적인 마인드로 보자면 마이그레이션은 비효율적인 오랜 습관을 과감히 버릴 절호의 기회입니다. 예전엔 컴퓨팅 자원이 부족해 데이터를 추출하고 변환한 뒤 적재하는 ETL 방식을 썼지만 컴퓨팅 자원을 유연하게 할당해 활용할 수 있는 클라우드 네이티브 환경에서는 데이터를 일단 넣고(Load) 내부에서 변환(Transform)하는 ELT 방식이 훨씬 효율적입니다.
비용 관리도 마찬가지입니다. 모든 데이터를 실시간으로 처리해야 한다는 강박은 피크 타임을 대비해 자원을 미리 왕창 잡아두는 과잉 프로비저닝의 원인이 됩니다. 클라우드 환경에서는 이런 강박을 갖지 않아도 됩니다. 사용량 기반 과금(Pay-as-you-go)이다 보니 피크 타임을 위해 따로 자원을 잡아 둘 이유가 없습니다.
한층 더 높아진 자동화 수준
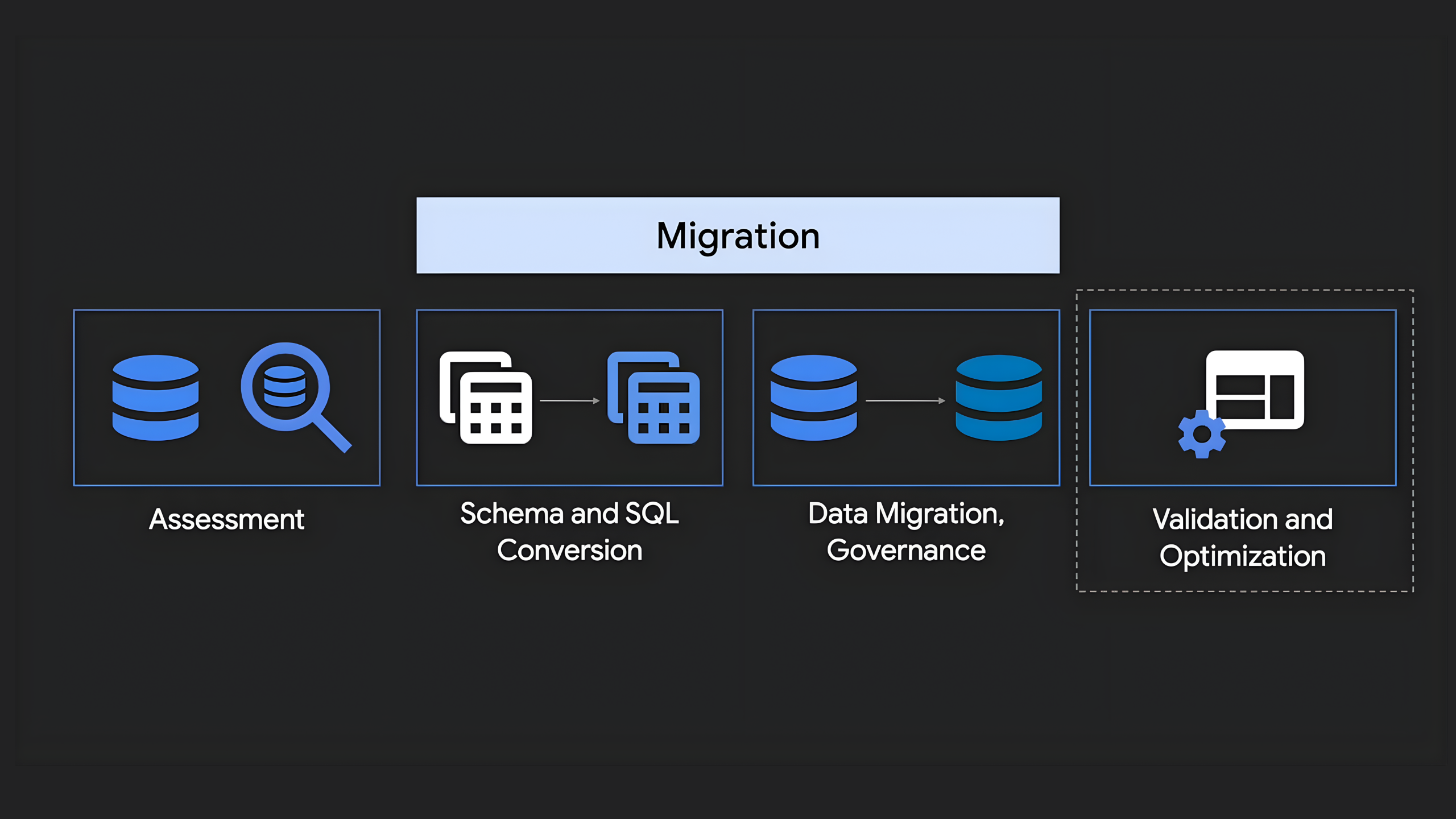
그렇다면 복잡한 마이그레이션을 어떻게 현대화의 기회로 삼을 수 있을까요? 답은 자동화 도구와 AI에 있습니다. 구글 클라우드는 ‘평가 → SQL 번역 → 데이터 전송 → 검증’으로 이어지는 여정을 자동화했습니다. 이 자동화는 예전의 방식을 뛰어넘는 만족감을 줍니다. 생성형 AI 기술이 접목되면서 큰 폭의 개선이 이루어졌습니다.
SQL Translation을 예로 들어 보겠습니다. 이 도구는 15개 이상의 SQL 방언을 이해하고 단순 문법 변환을 넘어 미세한 뉘앙스까지 잡아내 BigQuery에 맞게 바꿔줍니다. 더 놀라운 점은 configuration.yaml 같은 설정 파일을 통해 번역 규칙을 정밀하게 제어할 수 있다는 점입니다. 일례로 테이블 이름을 클라우드 명명 규칙에 맞게 자동으로 바꾸거나 특정 함수를 비즈니스 로직에 맞게 재정의하는 작업이 가능합니다.
대용량 데이터 전송에는 DTS(Data Transfer Service)가 활약합니다. 단순히 데이터를 붓는 것이 아니라 커스텀 스키마(Custom Schema) 전략을 통해 똑똑하게 옮깁니다. JSON 스키마 파일에 파티셔닝 기준이나 데이터 변경 시점(COMMIT_TIMESTAMP)을 명확히 지정해 주면 알아서 최적화된 테이블을 만들고 변경된 데이터만 쏙쏙 골라 옮기는 증분 전송이 가능해집니다. 마지막엔 데이터 검증 도구(DVT)가 행(Row) 수 비교뿐만 아니라 해시(Hash) 값을 비교하여 데이터가 깨지진 않았는지 꼼꼼하게 확인해 줍니다.
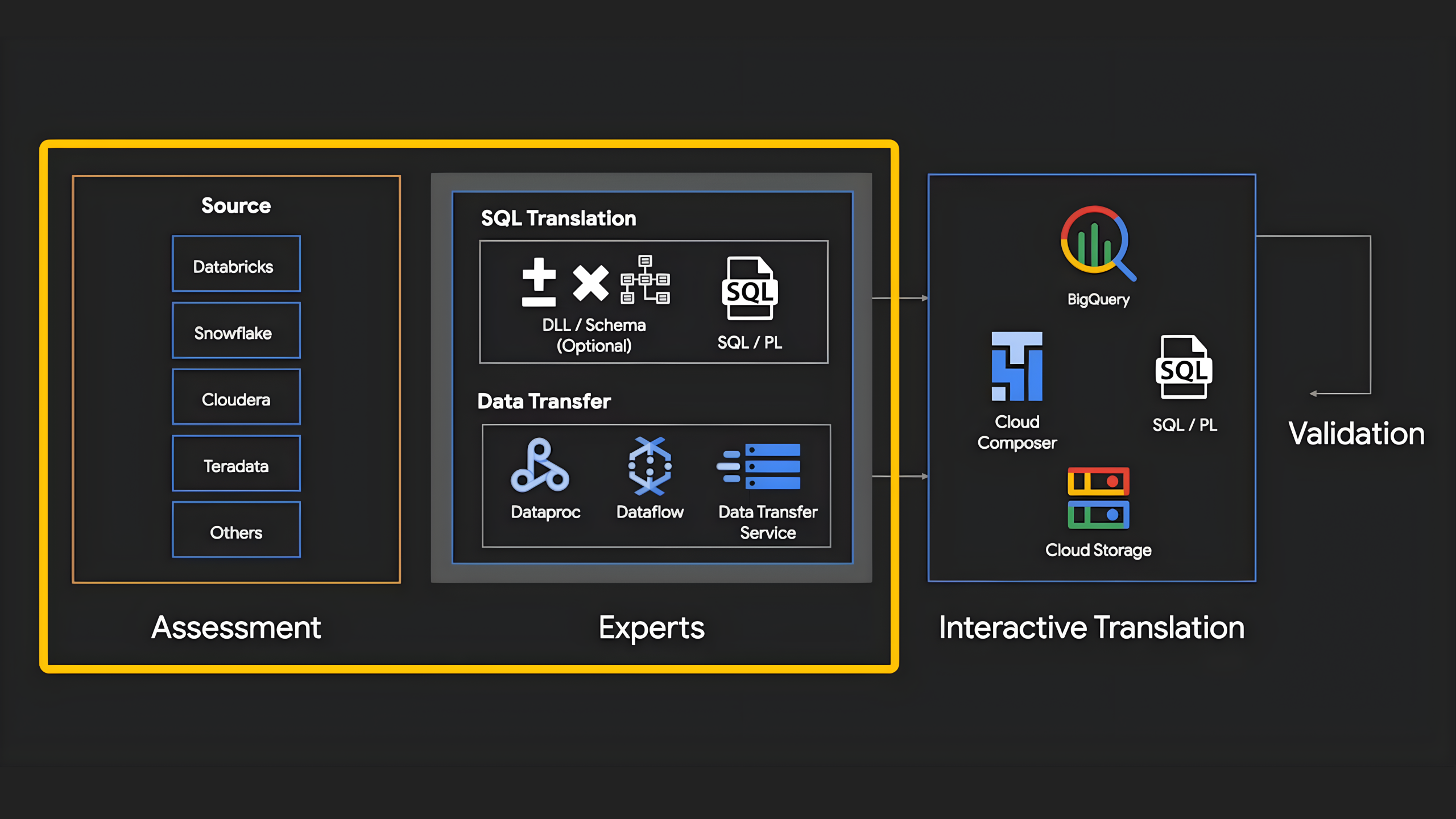
높은 수준의 자동화 도구와 함께 구글 클라우드는 현재 사용 중인데이터 플랫폼별 맞춤형 마이그레이션 방안도 제안합니다.
- Hadoop/Cloudera: Dataproc을 활용하면 기존 Spark, Hive 작업을 코드 수정 없이 리프트 앤 시프트 방식으로 옮긴 뒤 점진적으로 현대화할 수 있습니다. HDFS 데이터는 Cloud Storage로 메타데이터는 Dataproc Metastore로 이관하면 됩니다.
- Databricks: Spark SQL은 BigQuery로 노트북은 Jupyter로 매핑하면 됩니다. 특히 Delta Lake 테이블은 BigQuery의 네이티브 테이블이나 Iceberg/BigLake 테이블로 변환하여 유연하게 활용 가능합니다.
- Snowflake/Teradata: 전용 커넥터와 AI 도구를 통해 데이터와 쿼리 로직을 한 번에 옮길 수 있으며 Parquet 변환 시 발생하는 타입 불일치 문제도 AI가 매끄럽게 해결해 줍니다.
마이그레이션의 목표는 결국 AI 경쟁력 강화
레거시 데이터 플랫폼 환경을 구글 클라우드로 이전하는 것은 단순한 데이터 플랫폼 환경을 바꾸는 것이 아닙니다. 기업이 AI를 즉시 활용할 수 있는 ‘AI-Ready’ 플랫폼으로 레거시 환경을 현대화하는 여정입니다.
AI는 마이그레이션 이후에도 강력한 무기가 됩니다. 엔지니어가 자연어로 물어보면 복잡한 SQL을 만들어주고 쿼리 패턴을 분석해 “이 테이블을 날짜별로 파티셔닝하면 슬롯 시간을 획기적으로 줄일 수 있어요”라며 구체적인 최적화 방법도 제안합니다. 정형 데이터뿐만 아니라 이미지나 PDF 문서 같은 비정형 데이터도 객체 테이블(Object Tables) 기능을 통해 SQL로 분석할 수 있습니다.
이런 이점을 이미 누리는 곳도 많습니다. PayPal이나 Vodafone, HSBC 같은 글로벌 기업들은 BigQuery로 옮겨 비용은 줄이고 인사이트는 실시간으로 얻고 있습니다. “문제 없이 잘 작동하니 손대지 말자”는 마인드로는 경쟁에서 뒤처질 수밖에 없습니다.
이제 데이터를 깨끗한 자산으로 만들고 그 위에 AI라는 강력한 엔진을 달아야 할 때가 아닐까요? 더 자세한 내용이 궁금하다면, 메가존소프트 문의포탈을 통해 궁금한 부분을 남겨주세요.