최근 AI 시장의 흐름은 모델을 만드는 훈련(Training) 단계에서 실제 서비스를 제공하는 추론(Inference) 단계로 무게 중심이 이동하고 있습니다. 흔히 말하는 프로덕션 환경에 AI 서비스가 본격적으로 투입되는 시기가 된 것입니다. 이런 분위기 속에서 구글 TPU에 대한 관심이 높아지고 있습니다. 아무래도 추론 관련 성능과 비용의 황금비를 찾는 것이 중요하다 보니 GPU와 TPU를 놓고 심각하게 고민하는 곳이 늘고 있는 것 같습니다. 이번 포스팅에서는 구글 클라우드의 최신 TPU 라인업인 Trillium(v6e)과 Ironwood(v7)를 중심으로 하드웨어 아키텍처가 어떻게 진화했는지 그리고 TPU를 통한 훈련과 추론 성능 및 비용 최적화에 대해 알아보겠습니다.
TPU 하드웨어 라인업의 진화
최신 TPU 라인업에는 구글 클라우드가 추구하는 AI 워크로드 최적화 전략이 담겨 있습니다. Trillium과 Ironwood 추가로 훈련과 추론 등 워크로드 최적화를 위한 가속기 선택지가 확대되었습니다. 여기에 더해 기존 라인업의 경제성까지 갖추어 최적화 목표가 성능인지 비용인지에 따른 선택지도 넓어졌습니다. 주로 세대별로 어떤 선택이 가능한지 소개하겠습니다.

먼저 TPU v5 시리즈는 효율성과 성능이라는 두 가지 토끼를 잡기 위해 전략을 이원화했습니다. TPU v5e(Efficiency)는 이름 그대로 비용 효율성에 중점을 둔 가속기입니다. 중소형 모델의 훈련과 추론에 최적화되어 있으며 이전 세대인 v4보다 훈련 비용 대비 성능은2배, 추론 비용 대비 성능은 2.5배나 높습니다. 1개 칩부터 256개 칩까지 유연하게 구성할 수 있어 스타트업이나 비용에 민감한 추론 서비스에 적합합니다.
다음으로 TPU v5p(Performance)는 강력한 성능을 지향합니다. 8,960개의 칩을 하나의 팟(Pod)으로 묶는 초대형 구성과 칩당4,800Gbps의 인터커넥트 대역폭을 지원합니다. 이를 통해 수조 개의 파라미터를 가진 거대 모델을 학습시키는 데 필요한 강력한 확장성을 보장합니다.
2024년에 정식 출시된 6세대 제품인 Trillium은 구글 클라우드가 10년 넘게 쌓아온 노하우의 정점을 보여줍니다. 가장 눈에 띄는 점은 성능과 효율입니다. v5e와 비교했을 때 칩당 피크 연산 성능은 4.7배 높아졌고 전력 대비 성능(Performance/Watt)인 에너지 효율은67%나 개선되었습니다.
메모리와 확장성 측면에서도 큰 발전을 이루었습니다. HBM 용량과 대역폭을 각각 2배씩 늘려 고질적인 메모리 문제를 완화했습니다. 또한, 최대 256개의 칩을 고속 ICI(Inter-Chip Interconnect)로 연결할 수 있어 중대형 모델의 훈련은 물론 대규모 추론 워크로드에서도 범용적으로 뛰어난 성능을 발휘합니다.
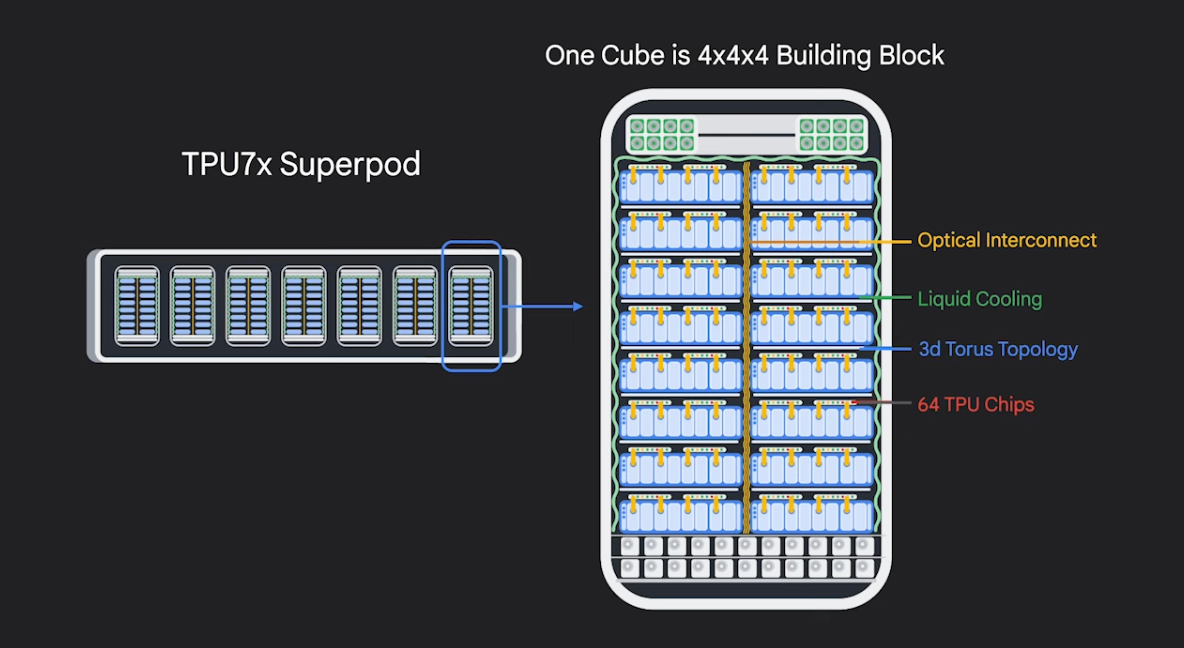
2025년 11월에 출시된 7세대 제품인 Ironwood는 NVIDIA의 H100 및 Blackwell 아키텍처에 대응하는 가속기로 추론의 시대를 겨냥해 설계한 칩셋입니다. Ironwood는 제조 수율과 효율을 높이기 위해 듀얼 칩렛(Dual Chiplet) 구조를 채택했으며 칩당 192GB의 HBM과7.37TB/s라는 압도적인 대역폭을 제공합니다. 이는 메모리 사용량이 많은 거대 모델 추론에 있어 이점을 제공합니다.
스케일 또한 슈퍼컴퓨팅급입니다. 9,216개의 칩을 하나의 슈퍼파드(Superpod)로 구성할 수 있으며 광회선 스위칭(OCS) 기반의 3D Mesh/Torus 토폴로지를 적용해 장애가 발생해도 시스템이 멈추지 않고 높은 가용성을 유지합니다. 실제로 Anthropic은 이 기술을 활용해 최대 100만 개의 TPU 클러스터를 구축하겠다는 계획을 발표하기도 했습니다.
소프트웨어 생태계 JAX, PyTorch, vLLM
칩셋의 잠재력을 100% 끌어내려면 강력한 소프트웨어가 뒷받침되어야 합니다. 구글 클라우드는 XLA(Accelerated Linear Algebra) 컴파일러를 중심으로 견고한 소프트웨어 스택을 구축했습니다.
먼저 JAX와 MaxText는 TPU에 가장 최적화된 TPU 네이티브 프레임워크입니다. MaxText는 순수 Python과 JAX로 작성된 오픈소스LLM 프레임워크로 Llama 3 같은 최신 모델에서 60% 이상의 높은 MFU(Model FLOPs Utilization)를 달성합니다.

PyTorch/XLA와 Torchax는 기존 PyTorch 사용자를 위한 도구입니다. 코드를 거의 수정하지 않고도 TPU에서 모델을 실행할 수 있게 지원합니다. 최근 등장한 Torchax 덕분에 PyTorch 코드도 JAX의 최적화 경로를 활용할 수 있게 되어 상호운용성이 대폭 강화되었습니다.
마지막으로 2025년 vLLM은 JAX와 PyTorch를 단일 런타임으로 통합한 tpu-inference 백엔드를 선보였습니다. 이로써 개발자는 프레임워크에 구애받지 않고 PagedAttention이나 Continuous Batching 같은 최신 추론 기술을 TPU 상에서 고성능으로 구현할 수 있게 되었습니다.
워크로드별 최적화 전략
AI 인프라 구축의 성공 여부는 단순히 좋은 장비를 쓰는 것이 아니라 ‘비용 대비 성능(Performance per Dollar)’을 극대화하는 전략적 선택에 달려 있습니다.
수천억 파라미터 규모의 모델을 훈련할 때는 데이터, 텐서, 파이프라인 병렬화를 결합한 3D 병렬화 전략이 필수적입니다. 통신 빈도가 잦은 텐서 병렬화 작업은 고속 ICI로 연결된 Pod 내부에서 처리하고, 데이터 병렬화 작업은 데이터센터 네트워크(DCN)를 통해 처리하는 멀티슬라이스(Multislice) 기술을 활용하는 것이 좋습니다.
구체적으로 보자면 초대형 모델의 사전 학습(Pre-training)에는 v5p나 Ironwood의 3D Torus 네트워크를 활용해 통신 병목을 최소화하고, 중소형 모델의 파인튜닝(Fine-tuning)에는 가성비가 뛰어난 v5e나 v6e를 활용하는 것을 고려할 수 있습니다.
추론 단계에서는 지연 시간(Latency)과 처리량(Throughput)이 핵심입니다. 특히 생성형 AI는 메모리 대역폭이 성능을 좌우하는 특성이 있습니다.
이에 대한 해법으로 연산이 많이 필요한 Prefill 단계와 메모리가 많이 필요한 Decode 단계를 분리하여 처리하는 디스어그리게이션(Disaggregated) 서빙 아키텍처를 적용합니다. Ironwood는 192GB의 대용량 메모리를 갖추고 있어 Llama 3.1 405B와 같은 거대 모델의 KV 캐시를 충분히 수용하며 효율적으로 서빙할 수 있습니다.
일반적인 서비스 서빙에는 최고의 가성비를 자랑하는 v5e를 초거대 모델이나 극도로 짧은 지연 시간이 필요한 서비스에는 Ironwood를 선택하는 것이 적합합니다.
반드시 하나의 칩셋만 고집할 필요는 없습니다. 워크로드 특성에 따라 여러 TPU를 섞어 쓰는 하이브리드 전략이 총소유비용(TCO)을 낮출 수 있습니다. 예를 들어 연구나 프로토타입 개발 단계에서는 저렴한 v5e나 Spot VM을 활용합니다. 그리고 대규모 학습이나 최종 배포 단계에서는 v5p 혹은 Ironwood를 사용하는 식입니다.
AI 인프라 전략 수립의 새로운 기준
구글 클라우드의 TPU 라인업, 특히 Trillium과 Ironwood의 등장은 AI 인프라 시장이 단순한 연산 속도 경쟁을 넘어섰음을 시사합니다. 이제는 메모리 대역폭, 인터커넥트 확장성, 그리고 에너지 효율성까지 종합적인 균형을 추구해야 할 때입니다. Agentic AI 전략을 엔터프라이즈 컴퓨팅 환경에 적용하고 싶거나 사용자 수가 많은 생성형 AI 기반 대외 서비스를 준비 중이라면? 메가존소프트가 워크로드 최적화 인프라 전략을 제안해 드리겠습니다.